Pesquisa e interação com o streaming de dados com o Kinesis Connector para ElasticSearch
A equipe Amazon Kinesis está feliz em anunciar o Kinesis Connector para ElasticSearch!

A equipe Amazon Kinesis está feliz em anunciar o Kinesis Connector para ElasticSearch! Usando o conector, os desenvolvedores podem escrever um aplicativo que carrega o streaming de dados do Kinesis em um cluster ElasticSearch em escala em tempo real e de forma confiável. O Elasticsearch é um motor de busca e análise em código aberto. Ele indexa dados estruturados e não estruturados em tempo real. O Kibana é o motor de visualização de dados do ElasticSearch; ele é usado por devops e analistas de negócios para configuração de painéis interativos. Os dados em um cluster ElasticSearch também podem ser acessados por programação usando a API RESTful ou aplicativos SDKs. Use o template CloudFormation em nosso exemplo para criar rapidamente um cluster ElasticSearch no Amazon Elastic Compute Cloud (EC2), totalmente gerenciado por Auto Scaling.
Conexão entre Kinesis, Elasticsearch e Kibana
O diagrama de blocos abaixo mostra como as peças se encaixam no tabuleiro:
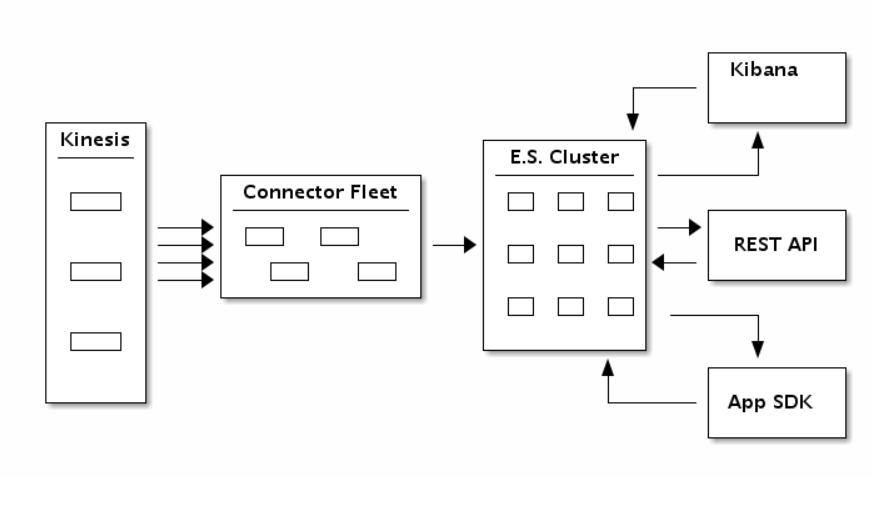
Ao usar o novo Kinesis Connector para ElasticSearch, é possível criar um aplicativo para consumir os dados do Kinesis Stream e indexá-los em um cluster ElasticSearch. Você pode transformar, filtrar e fazer o buffer de registros antes de emiti-los para o ElasticSearch. Você pode também fazer o ajuste fino de operações de indexação específicas do ElasticSearch para adicionar campos como time to live, version number, type e id em uma base por registro. O fluxo de registros segue conforme ilustrado no diagrama abaixo:
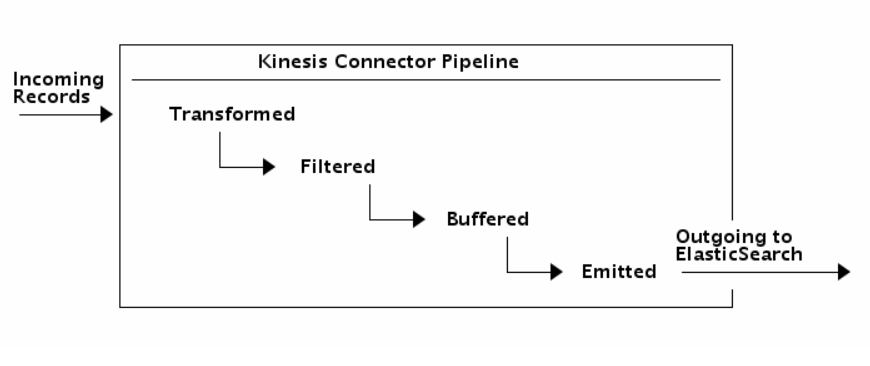
Note que também é possível executar todo o conector pipeline de dentro do cluster ElasticSearch usando River.
Como começar
Seu código possui as seguintes atribuições:
- Configurações específicas da aplicação
- Criar e configurar umKinesisConnectorPipeline com um Transformer, um Filter, um Buffer e um Emitter.
- Criar um KinesisConnectorExecutor que executa o pipeline continuamente.
Todos os componentes acima vêm com uma implementação padrão, que pode ser facilmente substituída pela lógica personalizada do usuário.
Configure as propriedades do conector
O exemplo vem com um arquivo .properties e um configurador. Há muitas configurações e o usuário pode deixar a maioria delas definidas para os valores padrão. Por exemplo, as seguintes definições irão configurar o conector para o carregamento em massa de dados no ElasticSearch somente após coletar ao menos 1.000 registros e usar o cluster local do ElasticSearch para testes.
bufferRecordCountLimit = 1000 elasticSearchEndpoint = localhost
Implementação de componentes do pipeline
Para conectar Transformer, Filter, Buffer e Emitter, o código deve implementar a interface IKinesisConnectorPipeline.
public class ElasticSearchPipeline implements
IKinesisConnectorPipeline<String,ElasticSearchObject>
public IEmitter<ElasticSearchObject> getEmitter
(KinesisConnectorConfiguration configuration) {
return new ElasticSearchEmitter(configuration);
}
view sourceprint?
public IBuffer<String> getBuffer(
KinesisConnectorConfiguration configuration) {
return new BasicMemoryBuffer<String>(configuration);
}
public ITransformerBase <String, ElasticSearchObject> getTransformer
(KinesisConnectorConfiguration configuration) {
return new StringToElasticSearchTransformer();
}
public IFilter<String> getFilter
(KinesisConnectorConfiguration configuration) {
return new AllPassFilter<String>();
}
O trecho a seguir implementa o método de construção abstrato, indicando o pipeline que se deseja usar:
public KinesisConnectorRecordProcessorFactory<String,ElasticSearchObject>
getKinesisConnectorRecordProcessorFactory() {
return new KinesisConnectorRecordProcessorFactory<String,
ElasticSearchObject>(new ElasticSearchPipeline(), config);
}
Definição do executor
O trecho a seguir define um pipeline onde os registros de entrada Kinesis são strings e os registros de saída são um ElasticSearchObject:
public class ElasticSearchExecutor extends KinesisConnectorExecutor<String,ElasticSearchObject>
O trecho a seguir implementa o método principal, cria o Executor e começa a executá-lo:
public static void main(String[] args) {
KinesisConnectorExecutor<String, ElasticSearchObject> executor
= new ElasticSearchExecutor(configFile);
executor.run();
}
A partir daqui, certifique-se de que suas credenciais AWS sejam fornecidas corretamente. Configure as dependências do projeto usando ant setup. Para executar o aplicativo, use ant run e pronto! Todo o código está no GitHub e pode ser usado imediatamente. Por favor envie suas perguntas e sugestões no Kinesis Forum.
Kinesis Client Library e Kinesis Connector Library
Quando lançamos o Kinesis em novembro de 2013, também introduzimos a Kinesis Client Library. Você pode usar a biblioteca cliente para construir aplicações que processam dados de streaming. Ela lida com questões complexas, como balanceamento de carga de streaming de dados e coordenação de serviços distribuídos, enquanto se adapta às alterações no volume de transmissão, tudo de uma forma tolerante a falhas. Sabemos que muitos desenvolvedores querem consumir e processar fluxos de entrada usando uma variedade de outros serviços AWS e não AWS. A fim de atender a essa necessidade, lançamos o Kinesis Connector Library no final do ano passado, com suporte para Amazon DynamoDB, Amazon Redshift e Amazon Simple Storage Service (S3). Em seguida, demos andamento ao Kinesis Storm Spout e ao conector Amazon EMR no início deste ano. Hoje, expandimos o Kinesis Connector Library com suporte ao ElasticSearch.
***
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.