Inicie Clusters do Amazon EMR em sub-redes privadas
Agora é possível iniciar clusters do Amazon EMR em sub-redes privadas no Amazon Virtual Private Cloud (VPC). Veja mais detalhes no artigo.

Estamos anunciando que agora é possível iniciar clusters do Amazon EMR em sub-redes privadas no Amazon Virtual Private Cloud (VPC), o que lhe permite criar clusters de forma fácil, rápida e econômica, totalmente configurados com aplicações Hadoop, Spark e Presto na sub-rede de sua escolha.
Com a versão 4.2.0 ou posterior do Amazon EMR, você pode iniciar seus clusters em uma sub-rede privada, sem endereços IP públicos ou gateway de Internet anexado. Você pode criar um endpoint privado para o Amazon S3 na sua sub-rede para dar acesso direto ao seu cluster Amazon EMR aos dados no S3 e, opcionalmente, criar uma instância do Network Address Translation (NAT) para que o cluster interaja com outros serviços da AWS, como o Amazon DynamoDB e AWS Key Management Service (KMS). Para mais informações sobre a Amazônia EMR em VPC, visite a página da documentação do Amazon EMR.
Topologia de rede para o Amazon EMR em uma sub-rede privada VPC
Antes de iniciar um cluster Amazon EMR em uma sub-rede privada VPC, por favor, verifique se você tem as permissões necessárias na sua função de serviço EMR e perfil de instância EC2, e que você tem uma rota (seja através de uma rota da sua sub-rede para um endpoint S3 em sua VPC ou uma instância NAT/Proxy) para os buckets S3 necessários para a inicialização do seu cluster. Clique aqui para obter mais informações sobre a configuração da sua sub-rede.
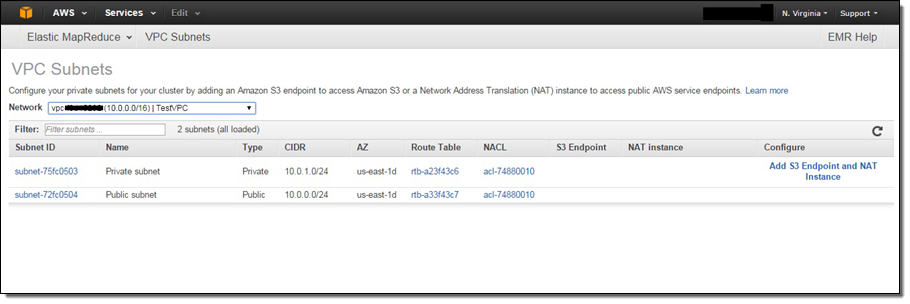
Você pode usar a nova página VPC sub-redes no Console do EMR para ver as sub-redes VPC disponíveis para seus clusters e configurá-los adicionando terminais S3 e instâncias NAT:
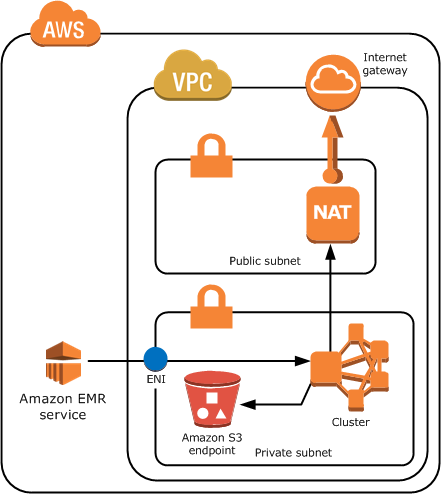
 Além disso, aqui está um exemplo de topologia de rede para um cluster Amazon EMR em uma sub-rede particular VPC com um endpoint S3 e uma instância NAT. No entanto, se você não precisa usar o seu cluster com os serviços da AWS, além do S3, você não precisa de uma instância NAT para fornecer uma rota para os endpoints públicos:
Além disso, aqui está um exemplo de topologia de rede para um cluster Amazon EMR em uma sub-rede particular VPC com um endpoint S3 e uma instância NAT. No entanto, se você não precisa usar o seu cluster com os serviços da AWS, além do S3, você não precisa de uma instância NAT para fornecer uma rota para os endpoints públicos:
Criptografia em repouso para Amazon S3 (com EMRFS), HDFS, e sistemas de arquivos local
Um Hadoop típico ou uma carga de trabalho Spark no Amazon EMR usa o Amazon S3 (usando o sistema de arquivos EMR – EMRFS) para conjuntos de dados de entrada/resultados de saída e dois sistemas de arquivos localizados em seu cluster: o sistema de arquivos Hadoop Distributed (HDFS) distribuídos em seu cluster e o sistema de arquivos local em cada instância. O Amazon EMR torna mais fácil para ativar a criptografia para cada sistema de arquivos, e há uma variedade de opções, dependendo de suas necessidades:
- Amazon S3 usando o sistema de arquivos EMR (EMRFS) – O EMRFS suporta várias opções de criptografia do Amazon S3 (usando criptografia AES-256), permitindo Hadoop e Spark no seu cluster para processar dados criptografados em S3 de forma permanente e transparente. O EMRFS funciona perfeitamente com objetos criptografados por S3 Server-Side Encryption ou S3 client-side encryption. Ao usar S3 client-side encryption, você pode usar chaves de criptografia armazenadas no Key Management Service AWS ou em um sistema de gerenciamento de chaves personalizado na AWS ou local.
- Criptografia transparente com Hadoop KMS – O Hadoop Key Management Server (KMS) pode fornecer chaves para HDFS Transparent Encryption e é instalado no nó principal do cluster EMR com HDFS. Uma vez que as atividades de encriptação e desencriptação são realizadas no cliente, os dados também são criptografados em trânsito no HDFS. Clique aqui para mais informações.
- Sistema de arquivos locais em cada nó – O Hadoop MapReduce e Spark frameworks utilizam o sistema de arquivos local em cada instância slave para dados intermediários por toda carga de trabalho. Você pode usar uma ação de inicialização para criptografar os diretórios utilizados para estes intermediários em cada nó usando LUKS.
Criptografia em trânsito para Hadoop MapReduce e Spark
Aplicações Hadoop instaladas em um cluster Amazon EMR normalmente têm diferentes mecanismos para criptografar dados em trânsito:
- Hadoop MapReduce Shuffle – Em um trabalho Hadoop MapReduce, o Hadoop enviará dados entre os nós do cluster na fase shuffle, que ocorre antes da fase de redução do trabalho. Você pode usar SSL para criptografar este processo, habilitando o Encrypted Shuffle nas configurações do Hadoop e fornecendo os certificados SSL necessários para cada nó.
- HDFS Rebalancing – HDFS restabelece o equilíbrio enviando blocos entre os processos DataNode. No entanto, se você usar HDFS Transparent Encryption (veja acima), o HDFS não detém blocos não criptografados e os blocos permanecem criptografados quando movido entre os nós.
- Spark Shuffle – O Spark, como o Hadoop MapReduce, também embaralha os dados entre os nós em determinados pontos durante um trabalho. A partir do Spark 1.4.0, você pode criptografar os dados nesta etapa usando criptografia SASL.
Usuários e funções IAM e auditoria com AWS CloudTrail
Você pode usar um usuário ou um usuário federado do Identity and Access Management (IAM) para chamar as APIs do Amazon EMR e limitar as chamadas de API que cada usuário pode fazer. Além disso, a Amazon EMR requer clusters criados com duas funções IAM, uma função de serviço EMR e um perfil de instância EC2, para limitar as permissões do serviço EMR e instâncias EC2 no seu cluster, respectivamente. O EMR fornece funções padrão usando EMR Named Policies para atualizações automáticas, no entanto, você também pode fornecer funções personalizadas IAM para o cluster. Finalmente, você pode auditar as chamadas feitas na sua conta para a API do Amazon EMR usando o AWS CloudTrail.
Grupos de segurança EC2 e acesso SSH opcional
O Amazon EMR usa dois grupos de segurança, um para o grupo instância mestre e outro para grupos de instância slave (Core e Task Instance Groups), para limitar a entrada e saída para as instâncias no seu cluster. O EMR fornece dois grupos de segurança padrão, mas você pode fornecer seu próprio (assumindo que eles têm as portas necessárias para a comunicação entre o serviço de EMR e o cluster) ou adicionar grupos de segurança adicionais para seu cluster. Em uma sub-rede privada, você também pode especificar o grupo de segurança adicionada à ENI usada pelo serviço de EMR para comunicar com o cluster.
Além disso, você pode, opcionalmente, adicionar um par de chaves EC2 para o nó principal do cluster se você quiser usar SSH para esse nó. Isso permite que você interaja diretamente com os aplicativos Hadoop instalados no seu conjunto, ou acesso web-UIs para aplicações usando um proxy sem abrir portas no seu grupo de segurança mestre.
Autenticação e autorização Hadoop e Spark
Uma vez que o Amazon EMR instala aplicativos Hadoop open source no seu cluster, você também pode aproveitar os recursos de segurança existentes nestes produtos. Você pode habilitar a autenticação Kerberos para YARN, o que dará a autenticação em nível de usuário para aplicativos em execução no YARN (como o Hadoop MapReduce e o Spark). Além disso, você pode ativar autorização SQL-level e tabela para Hive usando recursos HiveServer2 e utilizar a integração LDAP para criar e autenticar usuários em Hue.
Execute suas cargas de trabalho com segurança no Amazon EMR
No início deste ano o Amazon EMR foi adicionado ao AWS Business Associates Agreement (BAA) para a execução de cargas de trabalho que processam dados PII (incluindo elegibilidade para cargas de trabalho HIPAA). Amazon EMR também tem certificação para PCI DSS Level 1, ISO 9001, ISO 27001 e ISO 27018.
A segurança é uma prioridade para nós e nossos clientes. Nós estamos adicionando continuamente funcionalidade relacionada à segurança e certificados de conformidade de terceiros para o Amazon EMR, a fim de torná-lo ainda mais fácil para executar cargas de trabalho seg654uras e configurar recursos de segurança em Hadoop, Spark e Presto.
***
Artigo escrito por Jon Fritz.
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.