Infrakit e modo Swarm do Docker: um cluster tolerante a falhas e autorrecuperável
Apresentamos um exemplo de aprimoramento de motor do Docker no modo Swarm para alcançar alta disponibilidade para o InfraKit.

Em outubro de 2010, o Docker lançou o Infrakit, um conjunto de ferramentas open source para a criação e o gerenciamento de infraestruturas declarativas e autorrecuperáveis. Esta é a segunda parte em uma série de duas partes que vai mais fundo internamente no InfraKit.
Introdução
No primeiro capítulo desta série de duas partes sobre o InfraKit, apresentamos o design, a arquitetura e a abordagem do InfraKit para alta disponibilidade. Nós também discutimos como ele pode ser combinado com outros sistemas para dar aos clusters distribuídos propriedades autogerenciáveis e autorrecuperáveis. Neste capítulo, apresentamos um exemplo de aprimoramento de motor do Docker no modo Swarm para alcançar alta disponibilidade para o InfraKit, que por sua vez melhora o cluster Docker Swarm tornando-o autorrecuperável.
Modo Docker Swarm e InfraKit
Uma das principais funcionalidades arquiteturais do Docker no modo Swarm é o quórum de gerenciamento distribuído pelo SwarmKit. O quórum de gerenciamento armazena informações sobre o cluster, e a consistência de informações é alcançada através do consenso via Algoritmo de Consenso Raft, que também é o coração de outros sistemas como o Etcd. Este guia nos dá uma visão geral da arquitetura do modo Docker Swarm e como o gerenciador de quórum mantém o estado do cluster.
Um aspecto do estado do cluster mantido pelo quórum é a adesão dos nós – quais nós estão no cluster, quem são os gerenciadores e operadores, e seus estados. O algoritmo de consenso Raft nos dá garantias sobre o comportamento de nossos clusters em caso de falha, e a tolerência a falhas dos clusters está relacionada ao número de gerenciadores de nós no quórum. Por exemplo, um Docker Swarm com três gerenciadores pode tolerar a queda de um nó, planejada ou não, enquanto um quórum de cinco gerenciadores pode tolerar a queda de até dois membros, possivelmente uma planejada e uma não planejada.
O quórum Raft torna o cluster Docker Swarm tolerante a falhas, mas ele não consegue se reparar. Quando o quórum sofre a queda dos gerenciadores dos nós, passos manuais são necessários para resolver o problema e restaurar o cluster. Esses procedimentos exigem que o operador atualize ou restaure a topologia do quórum rebaixando ou removendo nós antigos do quórum e adicionando novos gerenciadores de nós quando as substituições ficam online.
Enquanto essas tarefas de administração são simples utilizando a interface de linha de comando do Docker, o InfraKit pode automatizá-las e tornar o cluster autorreparável. Como descrito na primeira parte, o InfraKit pode ser aplicado de uma maneira altamente disponível, com múltiplas réplicas sendo executadas e somente um mestre ativo. Em sua configuração, as réplicas do InfraKit podem aceitar entradas externas para determinar qual réplica é o mestre ativo. Isso torna fácil integrar o InfraKit com o Docker no modo Swarm: executando o InfraKit em cada gerenciador de nó do Swarm e detectando as mudanças de liderança no quórum Raft via Docker API padrão, o InfraKit consegue a mesma tolerância a falhas que o cluster Swarm. Por sua vez, o monitoramento e a orquestração de capacidades de infraestrutura do InfraKit, quando existe uma queda, podem automaticamente restaurar o quórum, tornando o cluster autorreparável.
Exemplo: um Docker Swarm com InfraKit no AWS
Para ilustrar essa ideia, nós criamos um template de Cloudformation que irá carregar e criar um cluster Docker em modo Swarm gerenciado pelo InfraKit no AWS. Existem algumas maneiras de executar isso, você pode clonar o repositório de exemplos do InfraKit e subir o template, ou você pode utilizar esta URL para iniciar o console do Cloudformation.
Por favor, note que esse script é somente para demonstração e pode não apresentar as melhores práticas. No entanto, usuários técnicos deveriam experimentá-lo e personalizá-lo para seus propósitos. Alguns detalhes sobre esse template:
- Como uma demo, somente algumas regiões são suportadas: us-west-1 (norte da Califórnia), us-west-2 (Oregon), us-east-1 (norte da Virgínia) e eu-central-1 (Frankfurt).
- Ele leva o tamanho do cluster (número de nós), chave SSH e tamanho das instâncias como entrada primária do usuário quando estiver iniciando.
- Existem opções para instalar a versão mais nova do Docker Engine com base no Ubuntu 16.04 AMI ou utilizar imagens que tenham sido pré-instaladas pelo Docker e publicadas para demonstração.
- Ele inicializa o ambiente de rede criando um VPC, um gateway e rotas, uma sub-rede e um grupo de segurança.
- Ele cria uma função IAM para o plugin da instância do InfraKit no AWS para descrever e criar as instâncias EC2.
- Ele cria uma única instância de bootstrap EC2 e três volumes EBS (mais sobre isso à frente). A instância de bootstrap está anexada a um dos volumes e será a primeira líder so Swarm. O cluster Swarm inteiro vai crescer dessa semente, conforme direcionado pelo InfraKit.
Com os elementos acima, esse script Cloudformation tem tudo o que é necessário para inicializar um cluster Docker de N nós em modo Swarm gerenciado pelo InfraKit (com 3 gerenciadores e N-3 operadores).
Sobre volumes EBS e grupos autoescaláveis
A utilização dos volumes EBS em nosso exemplo demonstra uma abordagem alternativa para gerenciar os gerenciadores do modo Swarm do Docker. Em vez de depender de atualizar manualmente a topologia do quórum removendo e então adicionando novos gerenciadores de nós para substituir instâncias com problemas, nós utilizamos os volumes EBS anexados ao gerenciador de instâncias e montamos em /var/lib/docker para um estado durável que sobreviva após a vida de uma instância. Assim que o volume de um gerenciador finalizado é anexado a uma nova instância EC2 substituta, podemos carregar o estado do cluster mais rapidamente porque existem menos mudanças de estados para atualizar. Essa abordagem é atrativa para grandes clusters executando muitos nós e serviços, nos quais a totalidade dos estados dos clusters pode levar um tempo grande para ser replicada para o novo gerenciador que acabou de se juntar ao Swarm.
A utilização de volumes persistentes nesse exemplo destaca a filosofia do InfraKit de executar serviços com estados em uma infraestrutura imutável.
- Utiliza instâncias computacionais somente para núcleos de processamento; eles podem ir e vir;
- Mantém o estado de persistência de volumes que podem sobreviver quando as instâncias não sobrevivem;
- O orquestrador tem a responsabilidade de manter os membros em um grupo identificado por IDs lógicos fixos. Nesse caso, eles são IPs privados para os gerenciadores Swarm.
- O pareamento do ID lógico (endereço IP) e estado (no volume) precisam ser mantidos.
Isso traz um detalhe de implementação relacionado – por que não usar a implementação de grupos autoescalonáveis que já estão lá? Primeiro, a implementação dos grupos autoescalonáveis varia de um servidor de serviços em nuvem para outro, isso se estiver disponível. Segundo, a maioria dos autoescalonadores é desenvolvida para gerenciar grupos onde as instâncias individuais nos grupos são idênticas umas às outras. Isso claramente não é o caso para os gerenciadores Swarm:
- Os gerenciadores têm alguns tipos de identidade como recurso (via endereço IP).
- Como recursos de infraestrutura, os membros de um grupo podem saber sobre os outros via participação nesse grupo estável de IDs.
- Os gerenciadores identificados por esses endereços IP têm o estado que precisa ser desanexado e anexado durante o tempo de vida das instâncias. O pareamento deve ser mantido.
As implementações de autoescalonamento atuais focam no gerenciamento de instâncias idênticas em um grupo. Novas instâncias são adicionadas com IPs que não combinam com as expectativas do grupo, e os volumes das instâncias que falharam em um grupo de autoescalonamento não são passados para a nova instância. É possível trabalhar com essas limitações com suor e determinação; o InfraKit, por suportar alocação, IDs lógicos e anexos, suporta esse caso de uso nativamente.
Bootstraping o InfraKit e o Swarm
Até agora, o template Cloudformation implementa o que chamamos de “bootstrapping“, ou o processo de criar o conjunto mínimo de recursos para iniciar um cluster gerenciado InfraKit. Com a criação do ambiente de rede e da primeira instância seed EC2, o InfraKit tem os recursos exigidos para assumir o controle e completar o provisionamento do cluster para atingir a especificação do cliente de N nós (com 3 gerenciadores e N-3 operadores). Aqui está um resumo do processo:
Quando a única instância “seed“ EC2 iniciar, uma única linha de código é executada no UserData (também conhecido como cloudinit), em um JSON Cloudformation:
"docker run --rm ",{"Ref":"InfrakitCore"}," infrakit template --url ",
{"Ref":"InfrakitConfigRoot"}, "/boot.sh",
" --global /cluster/name=", {"Ref":"AWS::StackName"},
" --global /cluster/swarm/size=", {"Ref":"ClusterSize"},
" --global /provider/image/hasDocker=yes",
" --global /infrakit/config/root=", {"Ref":"InfrakitConfigRoot"},
" --global /infrakit/docker/image=", {"Ref":"InfrakitCore"},
" --global /infrakit/instance/docker/image=", {"Ref":"InfrakitInstancePlugin"},
" --global /infrakit/metadata/docker/image=", {"Ref":"InfrakitMetadataPlugin"},
" --global /infrakit/metadata/configURL=", {"Ref":"MetadataExportTemplate"},
" | tee /var/lib/infrakit.boot | sh \n"
Aqui, estamos executando o InfraKit encapsulado em uma imagem Docker, e a maioria dessas declarações do Clouformation referencia os parâmetros (ex.: “InfraKitCore” e “ClusterSize”) definidos no início do template. Utilizando valores de parâmetros no template, ele traduz para uma única declaração como esta que irá executar durante a inicialização da instância:
docker run --rm infrakit/devbundle:0.4.1 infrakit template --url https://infrakit.github.io/examples/swarm/boot.sh --global /cluster/name=mystack --global /cluster/swarm/size=4 # many more ... | tee /var/lib/infrakit.boot | sh # tee just makes a copy on disk
Essa única declaração marca a entrega do Cloudformation para o InfraKit. Quando a instância seed iniciar (e instalar o Docker, se já não for parte do AMI), o container do InfraKit é rodado para executar o comando do template do InfraKit. O comando do template leva uma URL como a fonte do template (ex.: https://infrakit.github.io/examples/swarm/boot.sh ou um arquivo local com uma URL, como file://) e um conjunto de pré-condições (como as variáveis –global) e renderizadores. Com as flags –global, conseguimos passar um conjunto de parâmetros informados pelo usuário quando iniciando o Cloudformation. Isso permite que o IntraKit utilize o Cloudformation como autenticação e interface de usuário para configurar o cluster.
O InfraKit utiliza templates para simplificar scripts complexos e tarefas de configuração. Os templates podem ser qualquer texto que utilize tags {{}} , também conhecidas como sintaxe de “handle bar”. Aqui, o InfraKit recebe um conjunto de parâmetros de entrada do template Cloudformation e uma URL referenciando o scipt de inicialização. Ele então pega o template e renderiza um script que é executado para realizar o seguinte durante a inicialização da instância:
- Formatar o EBS se não estiver formatado.
- Para o Docker se estiver atualmente sendo executado e montar o volume /var/lib/docker.
- Configurar o motor do Docker com os rótulos corretos, reiniciando-o.
- Iniciar um plugin de metadados do InfraKit que pode examinar esse ambiente. O plugin de instância do AWS, na versão 0.4.1, pode examinar um ambiente formado pelo Cloudformation, assim como utilizando o serviço de instância de metadados disponível no AWS. Os plugins de metadados do InfraKit podem exportar parâmetros importantes em um namespace somente de leitura que pode ser referenciado em templates como caminhos de sistemas de arquivos.
- Iniciar os containers InfraKit tais como gerenciador, grupo, instâncias e plugins do Swarm.
- Inicializar o Swarm via docker swarm init.
- Gerar um JSON de configuração para o próprio InfraKit. Esse JSON também é renderizado por um template (https://github.com/infrakit/examples/blob/v0.4.1/swarm/groups.json) que referencia parâmetros ambientais como região, zona de disponibilidade, IDs de sub-rede e grupo de segurança que são exportados pelos plugins de metadados.
- Executar o infrakit manager commit para dizer ao InfraKit para iniciar o gerenciamento do cluster.
Veja https://github.com/infrakit/examples/blob/v0.4.1/swarm/boot.sh para detalhes.
Quando a réplica do InfraKit começa a rodar, ela nota que o estado atual da infraestrutura (de somente um nó) não está de acordo com as especificações de 3 gerenciadores e N-3 nós operadores. O InfraKit então levará a infraestrutura em direção das especificações do usuário criando o resto dos gerenciadores e operadores para completar o Swarm.
O tópico dos metadados e templates no InfraKit será temas de artigos futuros. Em resumo, metadado é a informação exposta por plugins compatíveis organizados e acessíveis em um namespace cluster-wide. Os metadados podem ser acessados do CLI InfraKit ou no template com nomes de caminho tipo arquivo. Você pode pensar nisso como um cluster-wide sysfs somente de leitura. O motor do template InfraKit, por outro lado, pode fazer uso desses dados para renderizar arquivos de script de configuração complexa ou documentos JSON. O motor do template suporta a busca por uma coleção de templates de um diretório local ou remoto, por exemplo o repositório GitHub, que foi configurado para servir os templates como um website estático ou S3 Bucket.
Executando o exemplo
Você pode tanto utilizar os exemplos no repositório ou esta URL para acessar o console AWS. Aqui, nós vamos primeiro carregar o Swarm com o template Clodformation, então o InfraKit assume e provisiona o resto do cluster. Então, vamos demonstrar a tolerância a falhas e autorrecuperação finalizando o nó gerenciador líder no Swarm e induzir uma falha e forçar a recuperação.
Quando você acessar, vai precisar responder a algumas perguntas:
- O tamanho do cluster. Esse script sempre iniciará um Swarm com 3 gerenciadores, então utilize um valor maior que 3.
- A chave SSH.
- Existe uma opção para instalar o Docker ou utilizar o AMI com o Docker pré-instalado. Um AMI com o Docker pré-instalado proporciona menor tempo de inicialização quando o InfraKit precisa adicionar uma instância substituta.

Quando você concordar e acessar, leva alguns minutos para o cluster estar pronto. Nesse caso, começamos com um cluster de 4 nós. No console do AWS, podemos verificar que o cluster foi completamente provisionado pelo InfraKit:
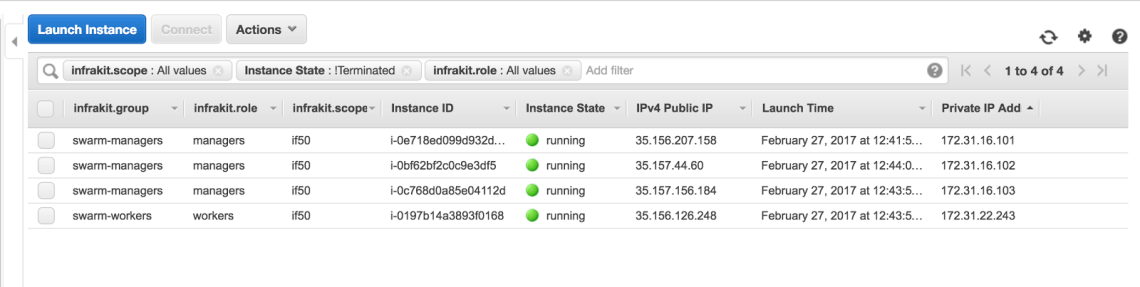
Note que os IPs privados 172.31.16.101, 172.31.16.102 e 172.31.16.103 foram fornecidos para os nós gerenciadores Swarm, e esses são os valores em nossa configuração. Nesse exemplo, os endereços IP públicos são atribuídos dinamicamente: 35.156.207.156 para a instância de gerenciamento 172.31.16.101.
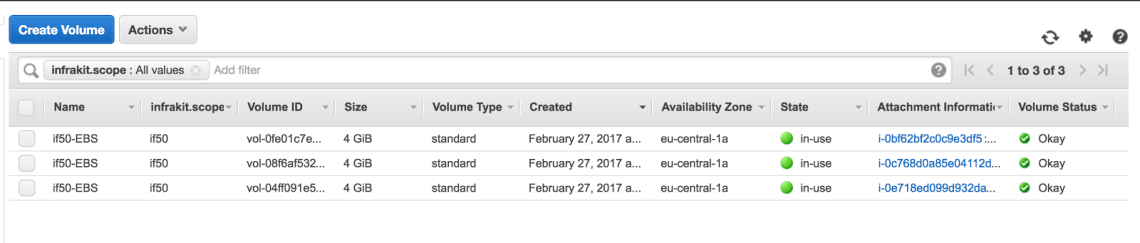
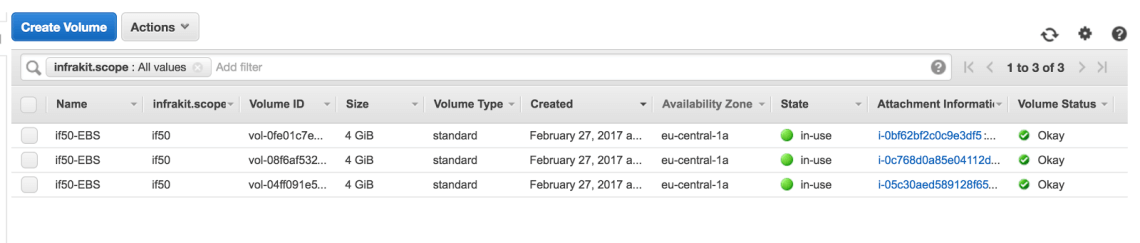
Também, nós vemos que o InfraKit anexou os 3 volumes aos nós de gerenciamento:
Pelo fato de o InfraKit ser configurado com o plugin Swarm Flavor, ele também se certificou de que as instâncias de gerenciamento e operação se juntaram com sucesso ao Swarm. Para ilustrar isso, podemos acessar as instâncias de gerenciamento e executar docker node ls. Como um meio de visualizar os membros do Swarm em tempo real, acessamos as três instâncias de gerenciamento e executamos
watch -d docker node ls
O comando watch por padrão atualizará docker node ls a cada 2 segundos. Isso nos permite não somente acompanhar as mudanças dos membros do Swarm em tempo real, mas também verificar a disponibilidade do Swarm completo.
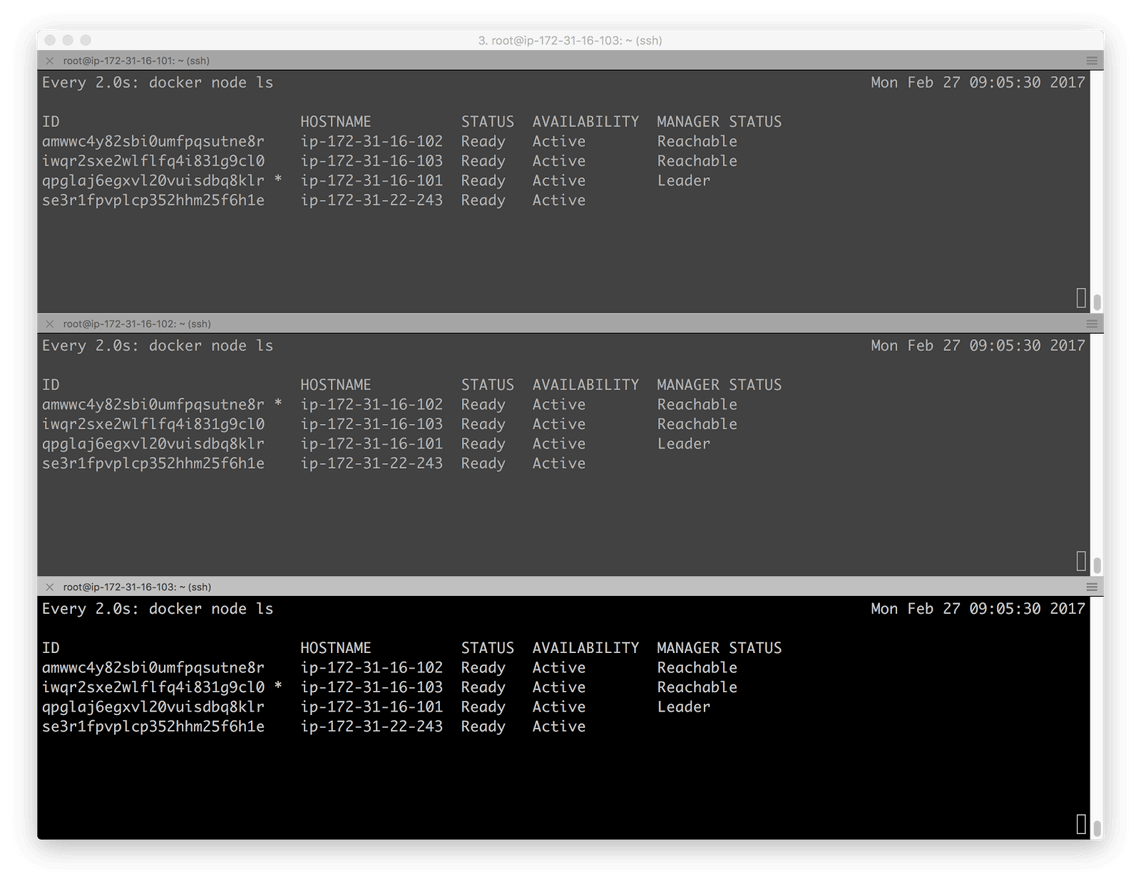
Note que, nesse momento, o líder do Swarm está como esperávamos, a instância de bootstrap, 172.31.16.101.
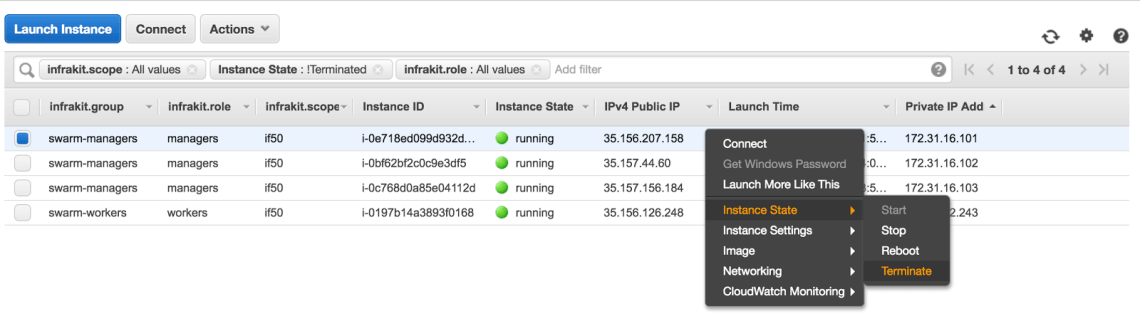
Vamos anotar o IP público dessa instância (35.156.207.156), o IP privado (172.31.16.101), e a identidade criptográfica desse nó no Swarm (qpglaj6egxvl20vuisdbq8klr). Agora, para testarmos a tolerância a falhas e autorrecuperação, vamos finalizar essa instância líder. Assim que essa instância for finalizada, esperaríamos que a liderança do quórum fosse para outro nó e, consequentemente, a réplica do InfraKit sendo executada nesse nó se tornaria o novo mestre.
Imediatamente a tela mostra que existe uma queda: no topo do terminal, a conexão para o host remoto 172.31.16.101 é perdida. No segundo e terceiro terminais abaixo, a lista de nós do Swarm está sendo atualizada em tempo real.
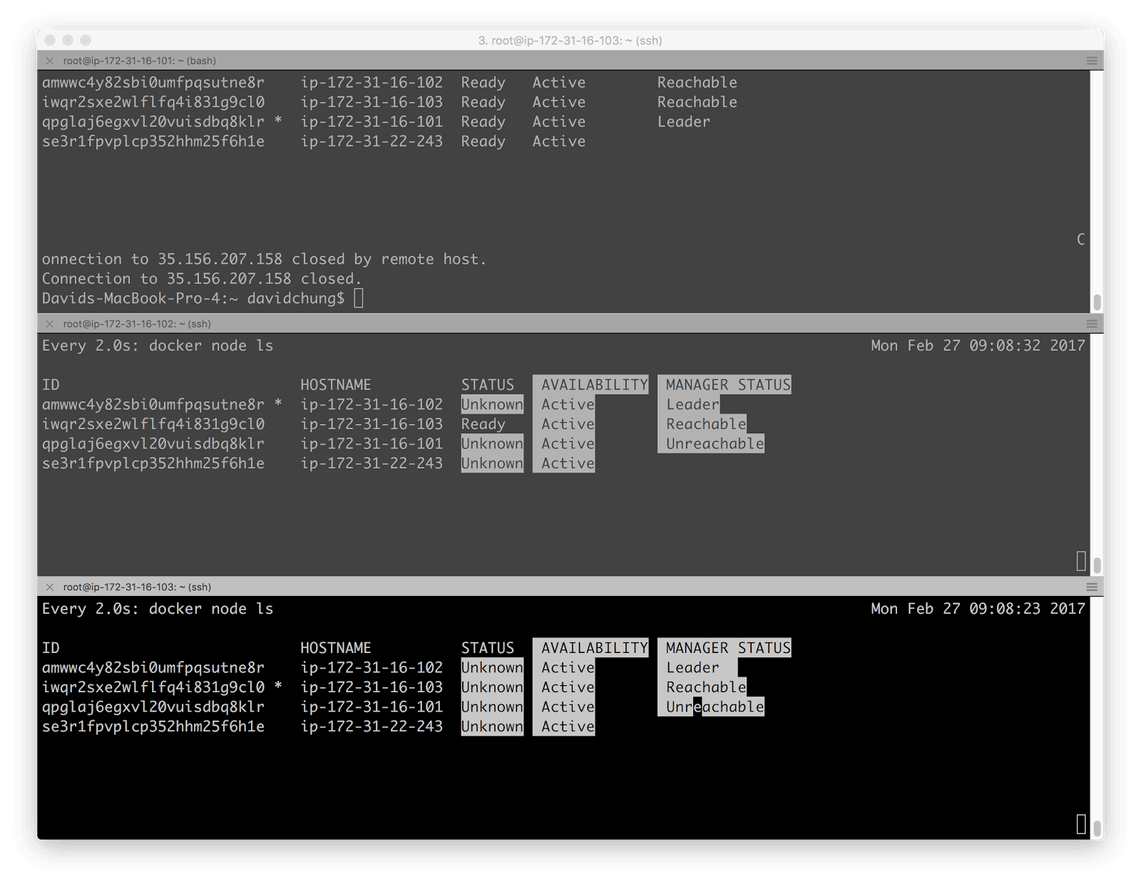
Quando a instância 172.31.16.101 é finalizada, a liderança do quórum é transferida para outro nó com o IP 172.31.16.102, o modo Docker Swarm pode tolerar a falha e continuar funcionando (como visto pela continuação da execução do docker node ls com os gerenciadores restantes). No entanto, o Swarm notou que a instância 172.31.16.101 agora está Down (fora) e Unreachable (inacessível).

Conforme configurado, um quórum de 3 gerenciadores pode tolerar a queda de uma instância. Nesse ponto, o cluster mantém a operação sem interrupção. Todos os aplicativos sendo executados no Swarm continuam em execução, e você pode utilizar os serviços normalmente. No entanto, sem alguma automação, o operador precisa intervir em algum momento e realizar algumas tarefas para restabelecer o cluster antes que outra queda nos nós restantes ocorra.
Por esse cluster ser gerenciado pelo InfraKit, a réplica sendo executada no 172.31.16.102 agora se torna a mestre quando a mesma instância assume a liderança no quórum. Devido ao InfraKit ter a tarefa de manter a especificação de 3 instâncias de gerenciamento com os endereços de IP 172.31.16.101, 172.31.16.102 e 172.31.16.103, ele vai tomar algumas ações quando notar que o 172.31.16.101 está faltando. Para corrigir a situação, ele vai:
- Criar uma nova instância com o IP 172.31.16.101;
- Anexar o volume EBS que foi previamente associado à instância que “caiu”;
- Restaurar o volume, para que o motor do Docker e o InfraKit comecem a executar nessa nova instância;
- Adicionar a nova instância ao Swarm.

Como visto acima, a nova instância no IP privado 172.31.16.101 agora tem um endereço de IP público efêmero 35.157.163.34, quando antes era 35.156.207.156. Nós também vemos que o volume EBS foi anexado novamente.
Devido ao re-anexamento do volume EBS em /var/lib/docker para a nova instância e utilização do mesmo endereço de IP, a nova instância vai aparecer exatamente como se a instância que foi finalizada tivesse sido restaurada e adicionada ao cluster. Então, para o Swarm, 172.31.16.101 pode ter passado por uma queda temporária de rede, foi restaurado e voltou a fazer parte do cluster:
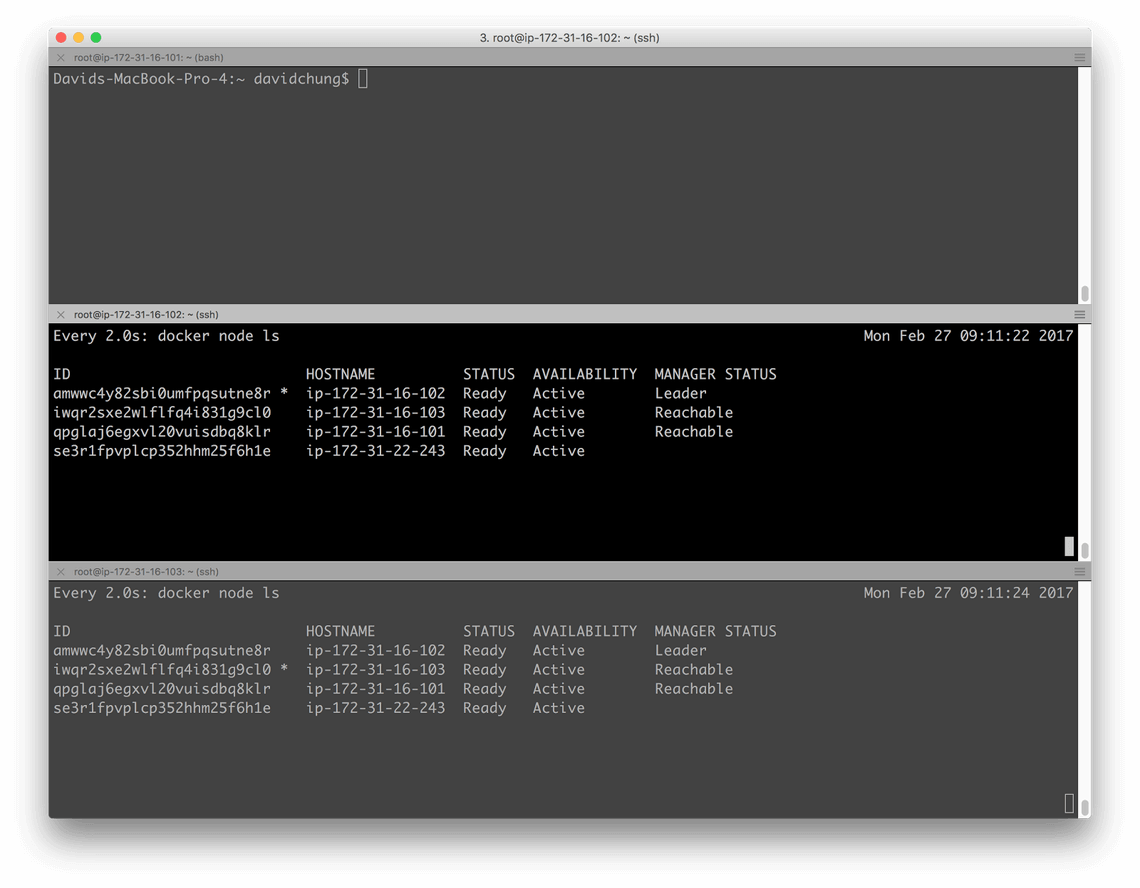
Nesse ponto, o cluster se recuperou sem qualquer intervenção manual. Os gerenciadores agora estão se apresentando saudáveis e o quórum continua vivo!
Conclusão
Enquanto esse exemplo é somente uma prova de conceito, esperamos que ele demonstre o potencial do InfraKit como um orquestrador ativo de infraestrutura que pode tornar um cluster distribuído tanto tolerante a falhas quanto autorecuperável. À medida que essas funcionalidades e capacidades amadurecem e se consolidam, vamos adicioná-las aos produtos do Docker como as edições do Docker para AWS e Azure.
O InfraKit é um projeto jovem e em rápido desenvolvimento, e estamos ativamente testando e construindo maneiras de proteger e automatizar as operações de grandes clusters distribuídos. Enquanto esse projeto está sendo desenvolvido aberto, suas ideias e feedback podem ajudar a nos guiar pelo caminho de tornar a computação distribuída resiliente e fácil de operar.
Veja o README no repositório do InfraKit para mais informações, um tutorial rápido e para começar a testar – desde arquivos simples até uma integração com Terraform para construir um conjunto Zookeeper. Dê uma olhada, explore, abra uma issue ou apenas diga “Olá”. Esperamos ouvir você.
***
Este artigo é do Docker Core Engineering. A tradução do artigo foi feita pela Redação iMasters com autorização, e você pode acompanhar o artigo em inglês no link: https://blog.docker.com/2017/03/infrakit-docker-swarm-mode-fault-tolerant-self-healing-cluster/.