Controle de Failover adicional para Amazon Aurora
O Amazon Aurora é um mecanismo de banco de dados relacional, compatível com o MySQL.

O Amazon Aurora é um mecanismo de banco de dados relacional, compatível com o MySQL, que combina a velocidade e disponibilidade de bancos de dados comerciais avançados com a simplicidade e a economia de bancos de dados de código aberto (se quiser se inteirar mais, leia este meu artigo, em inglês: Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS).
O Aurora permite que você crie até 15 réplicas de leitura para aumentar a taxa de transferência de leitura e para uso como destinos de failover. As réplicas compartilham armazenamento com instâncias primárias e fornecem replicação compacta, de granulação fina que é quase síncrona, com um atraso de duplicação da ordem de 10 a 20 milissegundos.
Controle de Failover adicional
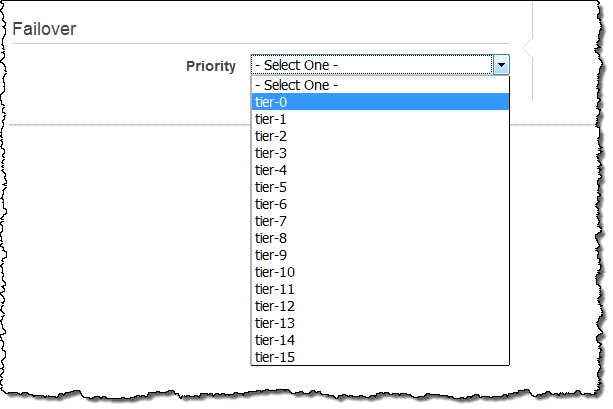
Hoje estamos tornando o Aurora ainda mais flexível, dando-lhe o controle sobre a prioridade de failover de cada réplica de leitura. Cada réplica de leitura agora está associada com uma camada de prioridade (0-15). No caso de um failover, o Amazon RDS irá promover a réplica de leitura que tem a prioridade mais alta (a camada de menor número). Se duas ou mais réplicas da mesma prioridade, o RDS promoverá a que for do mesmo tamanho que a instância primária anterior.
Você pode definir a prioridade quando você criar a instância do Aurora DB:
Este recurso já está disponível e você já pode começar a usá-lo. Para saber mais, leia Fault Tolerance for an Aurora DB Cluster.