

Amazon DynamoDB é um serviço de banco de dados NoSQL rápido e flexível para todas as aplicações que necessitam de latência consistente de um dígito de milissegundo em qualquer escala. Nossos clientes amam o fato de que podem começar rapidamente e de forma simples (e muitas vezes sem nenhum custo, dentro do AWS Free Tier) e, em seguida, dimensionar sem preocupações para armazenar qualquer quantidade de dados e lidar com qualquer taxa de requisição desejada, tudo com desempenho consistente e SSD-driven.
Atualmente temos tornado o DynamoDB ainda mais útil, com quatro adições importantes: suporte para dados JSON, expansão da camada gratuita (free tier), opções de escala adicionais e a capacidade de armazenar itens maiores. Também temos um novo vídeo de demonstração e algumas referências de clientes novos.
Suporte a documentos JSON
Agora é possível armazenar documentos inteiros formatados em JSON como itens DynamoDB individuais (sujeitos ao recente aumento do tamanho limite de 400 KB, que comentaremos mais à frente neste artigo).
Este novo suporte orientado a documentos é implementado nas SDKs da AWS e faz uso de alguns novos tipos de dados DynamoDB. O suporte a documentos (disponível agora no AWS SDK for Java, SDK for .NET e SDK for Ruby e uma extensão do SDK for JavaScript in the Browser) faz com que seja fácil mapear dados JSON ou objeto de língua nativa para tipos de dados nativos do DynamoDB e para suportar queries baseadas na estrutura do documento. Também é possível visualizar e editar documentos JSON de dentro do AWS Management Console.
Com esta adição, o DynamoDB torna-se uma sólida loja de documentos. Usando os SDKs da AWS é fácil armazenar documentos JSON em uma tabela DynamoDB, preservando uma “forma” complexa e possivelmente aninhada. Os novos tipos de dados também podem ser usados para armazenar outros formatos estruturados, como HTML ou XML, através da construção de uma camada muito fina de tradução.
Vamos trabalhar com alguns exemplos. Começaremos com o seguinte documento JSON:
{
"person_id" : 123,
"last_name" : "Barr",
"first_name" : "Jeff",
"current_city" : "Tokyo",
"next_haircut" :
{
"year" : 2014,
"month" : 10,
"day" : 30
},
"children" :
[ "SJB", "ASB", "CGB", "BGB", "GTB" ]
}
Isso precisa de alguma alternativa para ser usado como uma Java String literal:
String json = "{"
+ "\"person_id\" : 123 ,"
+ "\"last_name\" : \"Barr\" ,"
+ "\"first_name\" : \"Jeff\" ,"
+ "\"current_city\" : \"Tokyo\" ,"
+ "\"next_haircut\" : {"
+ "\"year\" : 2014 ,"
+ "\"month\" : 10 ,"
+ "\"day\" : 30"
+ "} ,"
+ "\"children\" :"
+ "[ \"SJB\" , \"ASB\" , \"CGB\" , \"BGB\" , \"GTB\" ]"
+ "}"
;
Abaixo mostro como armazenaríamos esse documento JSON em nossa tabela people:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item item =
new Item()
.withPrimaryKey("person_id", 123)
.withJSON("document", json);
table.putItem(item);
E abaixo, como o recuperaríamos:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item documentItem =
table.getItem(new GetItemSpec()
.withPrimaryKey("person_id", 123)
.withAttributesToGet("document"));
System.out.println(documentItem.getJSONPretty("document"));
A AWS SDK for Java mapeia o documento para os tipos de dados do DynamoDB e os armazena da seguinte forma:
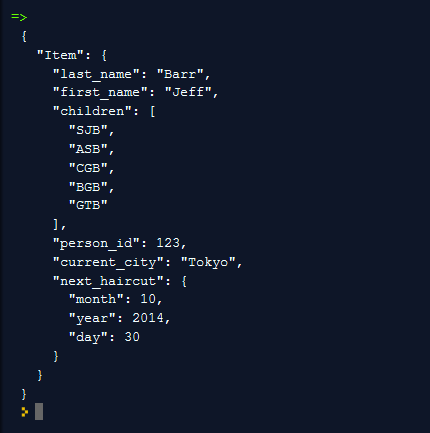
Também podemos representar e manipular o documento de forma estrutural e programática. Esse código faz referência explícita a novos tipos de dados de Map e List do DynamoDB, que descreveremos mais adiante:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item item =
new Item()
.withPrimaryKey("person_id", 123)
.withMap("document",
new ValueMap()
.withString("last_name", "Barr")
.withString("first_name", "Jeff")
.withString("current_city", "Tokyo")
.withMap("next_haircut",
new ValueMap()
.withInt("year", 2014)
.withInt("month", 10)
.withInt("day", 30))
.withList("children",
"SJB", "ASB", "CGB", "BGB", "GTB"));
table.putItem(item);
E como recuperaríamos o item por inteiro:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item documentItem =
table.getItem(new GetItemSpec()
.withPrimaryKey("person_id", 123)
.withAttributesToGet("document"));
System.out.println(documentItem.get("document"));
Podemos usar um Document Path para recuperar parte de um documento. Talvez precisemos do item next_haircut e nada mais. Da mesma forma, podemos atualizar parte de um documento. Abaixo, veja como alteraríamos a current_city para Seattle:
Como parte deste lançamento também estamos adicionando suporte para os quatro tipos de dados abaixo:
- List – Um atributo desse tipo de dado consiste de uma coleção ordenada de valores, semelhante a um array JSON. A seção children do documento de exemplo é armazenada em um List.
- Map – Um atributo desse tipo consiste de uma coleção desordenada de pares name-value, semelhante a um objeto JSON. A seção next_haircut do documento de exemplo é armazenada em um Map.
- Boolean – Um atributo desse tipo armazena um valor Boolean (true ou false).
- Null – Um atributo desse tipo representa um valor com um estado desconhecido ou indefinido.
O mapeamento do JSON para tipos de dados intrínsecos do DynamoDB é previsível e simples. Você pode, se quiser, armazenar um documento JSON em um DynamoDB e depois recuperá-lo usando as funções de nível inferior “nativas”. Também é possível recuperar um item existente como um documento JSON.
É importante notar que o sistema de tipo DynamoDB é um super conjunto do tipo de sistema JSON, e que os itens que contêm atributos do tipo Binary ou Set não podem ser fielmente representados em JSON. Os métodos Item.getJSON(String) e Item.toJSON() codificam dados binários em base-64 e mapeiam os conjuntos DynamoDB para listas JSON.
Expansão de camada gratuita
Ampliamos a capacidade disponível no DynamoDB como parte do AWS Free Tier. Agora é possível armazenar até 25GB de dados e processar até 200 milhões de requisições por mês, em até 25 unidades de capacidade de leitura e 25 unidades de capacidade de gravação. Em outras palavras, isso representa uma capacidade livre suficiente para a execução de um aplicativo de produção significativo sem nenhum custo adicional. Por exemplo, com base em nossa experiência, você pode executar um jogo para celular com mais de 15.000 jogadores, ou ainda executar uma plataforma de anúncios servindo 500 mil impressões por dia.
Opções de escala adicionais
Como você deve saber, o DynamoDB trabalha em um modelo provisionado de capacidade. Quando criamos cada uma das tabelas e os índices secundários globais associados, devemos especificar o nível desejado da capacidade de leitura e escrita, expressa em unidades de capacidade. A capacidade de cada unidade de leitura permite executar uma leitura fortemente consistente (de até 4KB por segundo) ou duas leituras eventualmente consistentes (também de até 4KB por segundo). Cada unidade de capacidade de escrita permite executar uma gravação (de até 1 KB por segundo).
Anteriormente, o DynamoDB permitia dobrar ou reduzir pela metade a quantidade de taxa de provisionada com cada operação de modificação. Com o lançamento de hoje, agora é possível ajustá-lo a qualquer quantidade desejada, limitada apenas pelos limites iniciais de transferência associados à conta AWS (que pode ser facilmente levantados). Para mais informações sobre esse limite, acesse o link DynamoDB Limits na documentação.
Itens maiores
Cada um dos itens DynamoDB agora podem ocupar até 400KB. O tamanho de um determinado item inclui o nome do atributo (em UTF-8) e o valor do atributo. O limite anterior era de 64KB.
Novo vídeo de demonstração
Nosso colega Khawaja Shams, chefe de Engenharia do DynamoDB, estrela o novo vídeo. Ele analisa os novos recursos e também revela um aplicativo de demonstração que faz uso do nosso novo suporte JSON:

DynamoDB em ação: os clientes estão falando
Clientes AWS em todo o mundo têm usado o DynamoDB como um elemento central das suas aplicações de missão crítica. Abaixo reportamos algumas dessas histórias de sucesso:
Talko é uma nova ferramenta de comunicação para grupos de trabalho e famílias. Ransom Richardson, Service Architect, explica por que eles usam o DynamoDB:
“O DynamoDB é uma parte essencial da arquitetura de armazenamento do Talko. Tem sido incrivelmente confiável, com 100% de uptime sobre nossos dois anos de uso. Seu desempenho consistente de baixa latência nos permitiu concentrar esforços no código do aplicativo ao invés de passar o tempo no ajuste fino do desempenho do banco de dados. Com o DynamoDB foi fácil dimensionar a capacidade para lidar com o lançamento do nosso produto”.
A Electronic Arts armazena dados de jogos para The Simpsons:Tapped Out (um aplicativo iOS top 20 nos EUA, com milhões de usuários ativos) no DynamoDB e na Amazon Simple Storage Service (S3). Eles mudaram de MySQL para DynamoDB e seus custos de armazenamento de dados despencaram em impressionantes 90%.
A equipe de desenvolvimento por trás desse jogo incrivelmente bem-sucedido conduzirá uma sessão no AWS re:Invent. Você pode participar do GAM302 para descobrir como eles migraram do MySQL para o DynamoDB “on the fly” e como usaram o AWS Elastic Beanstalk e o Auto Scaling para simplificar as implementações, além de reduzir os custos.
Indexação online (disponível em breve)
Estamos em planejamento para oferecer a capacidade de adicionar e remover índices para tabelas DynamoDB existentes. Isto fornecerá a flexibilidade desejada para ajustar os índices de forma a combinar padrões de query crescentes. Esse recurso estará disponível em breve, fique atento!
Comece agora!
Os novos recursos já estão disponíveis e você pode começar a usá-los hoje nas seguintes regiões: EUA (norte da Virgínia e norte da Califórnia), Europa (Irlanda), Ásia-Pacífico (Cingapura, Tóquio e Sydney) e América do Sul (Brasil). Eles estarão disponíveis em um futuro próximo em outras regiões da AWS. Desenvolvedores de outras regiões AWS podem baixar a versão mais recente do DynamoDB Local para desenvolver e testar aplicativos localmente (acesse o artigo DynamoDB Local for Desktop Development para saber mais).
***
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?