Arquiteturas de DR (Disaster Recovery) – Casos Práticos
O intuito desse artigo é expor conceitos de Disaster Recovery, algumas arquiteturas utilizadas no modelo de computação em nuvem, assim como casos práticos.

Para a grande maioria das corporações, questões de continuidade de negócios e backup são bastante críticas. Hoje em dia, diversas empresas estão utilizando a computação em nuvem para esse tipo de demanda, pois além da praticidade e flexibilidade, está aliada a otimização de custo.
O intuito desse artigo é expor conceitos de Disaster Recovery, algumas arquiteturas utilizadas no modelo de computação em nuvem, assim como casos práticos, expondo a intercomunicação com o ambiente on-premises e nuvem, para o melhor entendimento da aplicabilidade dos serviços para esse fim.
ConceitosO intuito desse tópico é expor alguns conceitos, os quais serão utilizados no decorrer desse artigo.
Ambiente de Recovery – Ambiente que ficará ativo/disponível no caso de desastre.
Continuidade do Negócio – Garante que uma corporação mantenha ou restaura as funções críticas do negócio após algum incidente grave.
DR – Disaster Recovery – Consiste em uma série de políticas e procedimentos com o intuito de restaurar o estado original de alguma aplicação ou serviço, após catástrofe.
On-Premises – Refere-se ao ambiente fora de nuvem computacional, geralmente utilizando-se de modalidades como hosting, colocation ou infraestrutura de computação dentro da corporação.
PCO – Plano de Continuidade Operacional – Plano de ação, o qual define procedimentos visando garantir que no caso de incidente, serviços essenciais sejam preservados.
RP – Recovery Point
RPO – Recovery Point Objective – A quantidade de dados perdida em um determinado período de tempo, após interrupção. Por exemplo, se um desastre acontece às 01:00 e o RPO é de uma (1) hora, o workload deve ser restaurado de forma íntegra, com os dados de até 00:00, ou seja, a perda de dados, será de no máximo uma (1) hora.
RT – Recovery Time
RTO – Recovery Time Objective – O tempo acordado no plano de continuidade operacional que leva, após interrupção, para restaurar o workload para o nível de serviço aceitável, após evento de desastre. Por exemplo, se um desastre acontece as 00:00 e o RTO é de oito (8) horas, o ambiente precisa ser restaurado aos níveis aceitáveis até 8:00.
Serviços da AWS
Antes de discutir as várias abordagens de DR, é importante listar os serviços da AWS com maior relevância para implementação de Arquiteturas de Disaster Recovery.
Banco de dados
Computação
Networking
Storage
Arquiteturas de DR
Nesse tópico serão apresentadas as principais estratégias de DR em nuvem computacional. As estratégias de DR diferenciam-se de cada uma pela complexidade de implementação, RT e RP e orçamento disponível.
Caso queira aprofundar ainda mais nesse tópico, sugerimos a leitura do artigo: Using Amazon Web Services for Disaster Recovery, conforme mencionado no tópico leitura adicional.
Backup e restore
O intuito dessa estratégia é realizar o armazenamento dos backups remotamente, para que no caso de algum incidente, esses dados estarão salvaguardados e poderão ser restaurados. Caso não possua nenhum tipo de estratégia de DR, pode ser um bom inicio. Essa estratégia, possui uma adesão rápida e fácil, além de bastante econômica, pois somente incorrerá custos de armazenamento.
Apesar do custo reduzido, possuem RT e RP elevados, devido a periodicidade do processo de backup e ao tempo de transferência de entrada e saída de dados realizados.
Normalmente os serviços utilizados nessa estratégia são: Amazon S3 e Amazon Glacier para armazenamento, AWS Storage Gateway, como appliance de armazenamento. Para conectividade entre os sites, Direct Connect ou VPC/VPN[1].
Existem serviços, os quais acelerarão o envio de dados, ideal para fazer as cargas iniciais, que são AWS Import/Export/Snowball.
Pilot Light
Nessa estratégia teremos parte do workload, normalmente uma replicação de dados, no ambiente de DR.
Em linhas gerais, consiste no sincronismo dos principais dados do workload e os outros componentes da arquitetura (servidores, balanceadores de carga, dentre outros) são também disponibilizados, porém não estão operacionais, aguardando algum incidente para a sua devida ativação.
O custo dessa arquitetura é um pouco mais elevada, quando se compara com a estratégia anterior. No entanto, haverá redução de RT e RP, pois os principais dados já estão replicados no ambiente de DR.
Os principais serviços utilizados nessa estratégia são: EC2 para computação, EBS para armazenamento de blocos ligados nas EC2, para questões de rede VPC, RDS, o qual atuará como banco de dados relacional como serviço, o balanceador de carga ELB, serviço de DNS Route 53 e Elastic Beanstalk.
Warm Standby
Com o uso dessa estratégia, teremos o ambiente de DR operacional, no entanto, com poder computacional reduzido. Em caso de incidente, basta ajustar as capacidades necessárias e realizar os devidos apontamentos para o ambiente de DR.
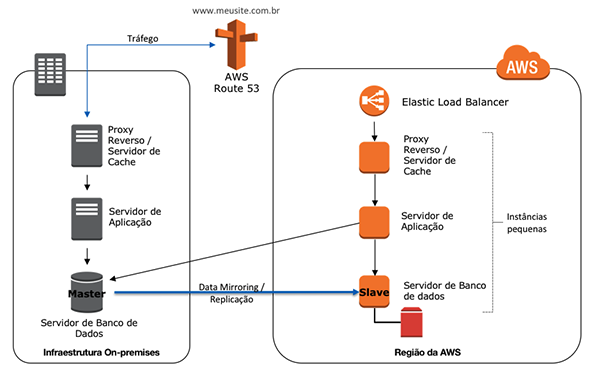
O RT e RP nessa estratégia serão ainda menores comparando com a pilot-light, visto que existirá dois ambientes operacionais, mas o custo também será, necessariamente, maior, visto que teremos mais componentes ativos.
Os serviços utilizados nessa estratégia são semelhantes aos da estratégia de Pilot Light: EC2 para computação, EBS para armazenamento de blocos ligados nas EC2, para questões de rede VPC, RDS, que atuará como banco de dados relacional como serviço, o balanceador de carga ELB, serviço de DNS Route 53 e Elastic Beanstalk.
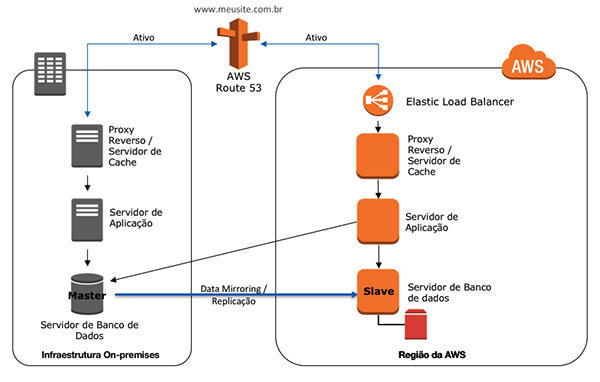
Multi-site
Consiste em ter dois ambiente completamente operacionais, utilizando ambos de forma ativa. No caso de algum incidente, basta não mais enviar requisição para o ambiente afetado. Dessa forma, a sua interrupção poderá ser imperceptível, pois as requisições começarão a ser enviadas para o ambiente em DR, pois, teremos dois ambientes em pleno funcionamento. Dependendo da carga existente, o ambiente de recovery sofrerá ajustes necessários de escalação para suportar a carga existente.
Nessa estratégia, o RT e RP são mínimos, pois os dois ambiente estarão em plena atividade. O custo dentre todas as estratégias, tende a ser o maior, visto que todos os componentes da arquitetura estarão ligados.
Vale salientar, devido a complexidade da implementação desse tipo de estratégia, que em alguns momentos não será possível a utilização em determinados workloads.
Os serviços utilizados nessa estratégia são semelhantes aos da estratégia Warm Standby: EC2 para computação, EBS para armazenamento de blocos ligados nas EC2, para questões de rede VPC, RDS o qual atuará como banco de dados relacional como serviço, o balanceador de cargas ELB, serviço de DNS Route 53 e Elastic Beanstalk.
Casos de uso de DR
Neste tópico, abordaremos alguns casos de DR e suas arquiteturas. Cada caso será analisado em função das camadas que compõe a sua arquitetura e, para cada uma, serão detalhados os mecanismos de preparação e recuperação, de modo a satisfazer o RPO e RTO da organização.
Perceba que nem sempre será possível criar um ambiente de DR na AWS que seja idêntico ao ambiente on-premises. Assim, adequações devem ser feitas de modo a aproveitar as funcionalidades dos serviços da AWS.
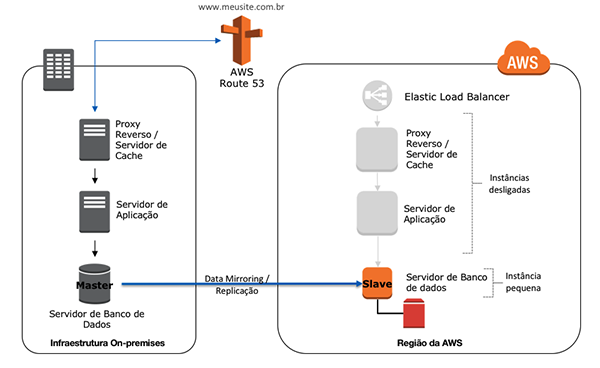
Arquitetura Web – Warm Standby
Este cenário refere-se a uma arquitetura de um sistema web rodando em uma estrutura on-premises, com estratégia de DR Warm Standby.
A arquitetura está dividida nos seguintes componentes: DNS, camada de computação com balanceadores de carga, servidores web de front-end, servidores de aplicação de back-end, camada de persistência com banco de dados relacional MySQL, NoSQL MongoDB e cache em memória Redis.
Será utilizada a estratégia de Warm Standby, onde o ambiente de recovery é mínimo, mas perfeitamente funcional. Em caso de desastre, o ambiente será escalado para suportar a carga de produção.
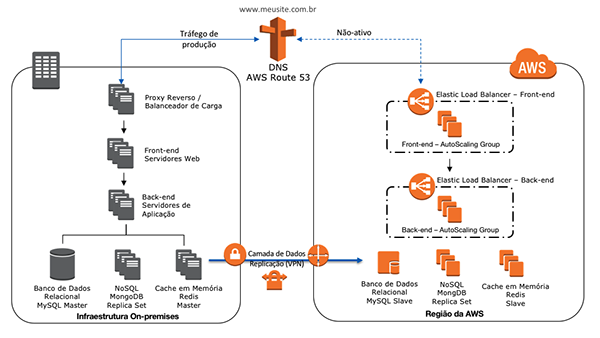
Camada de redes e comunicação
A camada de redes e comunicação define como os sistemas e recursos serão disponibilizados e acessados de maneira segura pelos usuários. Em caso de desastre, é desejável que a experiência de como os usuários acessam um serviço não sofra grandes impactos, sendo os acessos redirecionados para o ambiente de recovery.
É possível implementar um mecanismo de comunicação segura através de uma VPN entre o ambiente on-premises e a AWS.
DNS
Para redirecionar os acessos para o ambiente de recovery, deve-se realizar o failover de DNS.
Com o AWS Route 53 [2] é possível realizar o failover de DNS de maneira manual ou de maneira automática, através de health checks[3], que redireciona o tráfego em função da disponibilidade dos ambientes. Você também pode utilizar seu serviço de DNS on-premises para realizar o failover.
Camada de computação
O grande desafio da camada de servidores está em manter o ambiente de recovery atualizado em relação ao ambiente de origem. Atividades como aplicações de patch, atualizações de software e arquivos de configurações, devem ser refletidas de modo a garantir a perfeita operacionalização do ambiente de recovery.
Balanceador de carga
Para realizar o balanceamento de cargas de suas aplicações no ambiente de recovery é possível criar uma solução com a implantação de proxys em instâncias EC2.
O Amazon Elastic Load Balancing é outra opção para o balanceamento de cargas. Junto com o Auto Scaling[4] é possível montar uma estrutura capaz de escalar o ambiente mínimo de recovery, adicionando novas instâncias EC2 de forma automática.
Desta maneira, em um cenário de desastre, ELBs e Auto Scalings já estarão devidamente configurados e as aplicações estarão preparadas para suportar a carga do ambiente de origem.
Servidores de front-end e back-end
De modo a satisfazer RPO e RTO da arquitetura Warm Standby, suas aplicações no ambiente de recovery devem ser perfeitamente funcionais, sendo uma versão mínima da infraestrutura do ambiente de origem.
Crie e mantenha imagens atualizadas de seus servidores de modo a lançar seu ambiente de recovery de maneira rápida. As Amazon Machine Images (AMIs) são imagens que fornecem as informações necessárias para lançar instâncias EC2 com serviços totalmente funcionais.
Você também pode iniciar instâncias EC2 de uma máquina virtual que você importou de um ambiente virtualizado com Citrix Xen, Microsoft Hyper-V ou VMWare através do AWS VM Import Export.
Realize o escalonamento vertical[5] de maneira manual, iniciando suas aplicações em instâncias EC2 maiores, conforme o necessário. O escalonamento vertical implica em downtime, necessário para que as instâncias EC2 sejam paradas e reiniciadas com um tamanho maior, causando impacto no RTO. Para realizar o escalonamento horizontal através de um balanceador de carga, aumente a sua frota de instâncias EC2 de maneira manual ou deixe o Auto Scaling adicionar novas instâncias de maneira automática.
Utilize o Amazon CloudWatch para realizar o monitoramento de seu ambiente. Você pode utilizá-lo para colher métricas, obter visibilidade da utilização de seus recursos e reagir de modo a manter suas aplicações funcionando.
Camada de dados
A camada de dados é a mais sensível em um projeto de Disaster Recovery. RPO e RTO são influenciados diretamente pelo mecanismo utilizado na replicação desta camada para o ambiente de recovery. Em linhas gerais, quanto mais sofisticado for o mecanismo, menores serão os RPO e RTO alcançados. Em um extremo estão as estratégias de backup e recuperação dos dados e em outro estão os mecanismos para montagem de clusters de base de dados com múltiplos nós mestre ativos.
Banco de dados relacional – MySQL
O objetivo é replicar e manter sincronizado o estado do banco de dados relacional MySQL para o ambiente derecovery. O MySQL permite implementar diversos métodos de replicação[6] com diferentes tipos de sincronização.
O DR Warm Standby pode ser implementado através de uma arquitetura master/slave, com o nó master rodando e replicando dados do ambiente on-premises para o nó slave em uma instância EC2 na AWS. Também é possível utilizar o Amazon RDS para MySQL como o nó slave dessa replicação[7].
Quando o desastre ocorrer, é necessário escalar o ambiente mínimo de recovery para suportar a transferência de carga. Para tal, redimensione[8] a instância EC2 utilizada como nó slave (implica em downtime do banco de dados).
O nó slave deve ser promovido para se tornar o novo master. Uma maneira de manter as aplicações informadas sobre a localização do nó master de maneira transparente é ter uma entrada de DNS dinâmico.
Banco de dados NoSQL – MongoDB
Em geral, bancos de dados NoSQL possuem mecanismos de replicação de dados, com o objetivo de prover alta disponibilidade do serviço.
Com o MongoDB é possível montar diferentes arquiteturas de replicação de dados. A principal estrutura da replicação é o MongoDB Replica Set[9], que mantém o mesmo conjunto de dados e provêm redundância e alta disponibilidade ao ambiente. Para maiores detalhes, verifique a documentação oficial do MongoDB[10].
Cache em memória – Redis
Para manter sincronizado o estado do cache em memória, será feita replicação[11] em uma arquiteturamaster/slave do Redis. Em caso de desastre, será necessário forçar[12] manualmente para que o nó slave do cluster torne-se o novo master, realizando o cluster failover.
Arquitetura cliente servidor – Warm Standby
Nesse tópico será discutido a DR de aplicação do tipo Cliente Servidor.
Consideramos que esse workload será dividido nas seguintes camadas, DNS, aplicação/acesso dos usuários (Terminal Services), banco de dados e repositório de usuários (LDAP).
Utilizaremos a estratégia de Warm Standby; sendo assim, a ideia é disponibilizar todos os componentes da arquitetura no ambiente de DR, mantendo-os desligados e replicar a camada de banco de dados entre os dois ambiente.
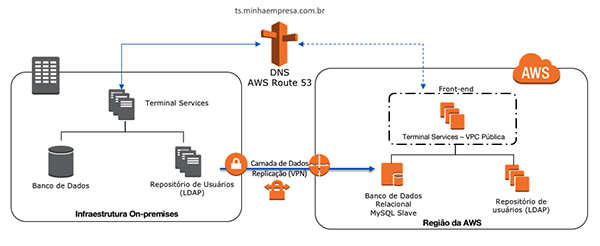
Camada de DNS
No que tange as questões de DNS, com a utilização do Route 53, como já mencionado anteriormente, utilizaremos a funcionalidade de health check.
Para os apontamentos tanto do concentrador de conexões de usuário (Terminal Services), o qual é a porta de entrada dos usuários, quanto para o banco de dados. Dessa forma, ao acontecer o incidente, o acesso será direcionado para o host que estará apto para receber as conexão.
Camada de servidores de autenticação
Para essa camada específica, realizaremos a replicação do repositório de usuário, utilizando servidor de réplica EC2 para que no caso de incidente, teremos sempre pelo menos um disponível, utilizando-se dessa replicação, teremos repositórios com os mesmos usuários.
É necessário realizar os apontamentos na aplicação em questão para os dois repositórios de usuário, pois no caso de incidente, pelo menos um deles estará apto para atender as solicitações.
Camada de dados
Em se tratando de banco de dados, é necessário realizar replicação dos dados entre os bancos dos ambientes envolvidos.
O intuito desse artigo, não é entrar profundamente nas estratégias de replicação, deixando a cargo do implementador a escolha da melhor forma de manter os dados sincronizados.
Repositório de arquivos – backup e restore
A AWS fornece diversos serviços que ajudarão a atender os requisitos das arquiteturas de backup and restore.
Podemos desde utilizar ferramentas de parceiros/terceiros, até construir as próprias ferramentas para realização de backup.
Conforme mencionado anteriormente, o serviço de Storage Gateway facilita a integração entre os ambientes para a realização de backup, dessa forma, podemos persistir dados no S3 e/ou Glacier.
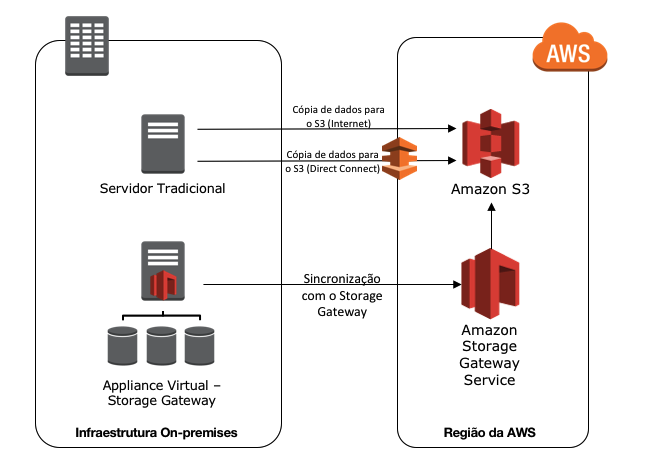
A figura abaixo é um exemplo de workload, que possui uma infraestrutura on-premises e os backups de dados enviados para a infraestrutura em nuvem. Caso aconteça algum desastre, como o backup dos dados, já estão persistidos em nuvem computacional e pode ser inicializada rapidamente a instalação desse ambiente em nuvem e direcionar os usuários para esse novo ambiente operacional.
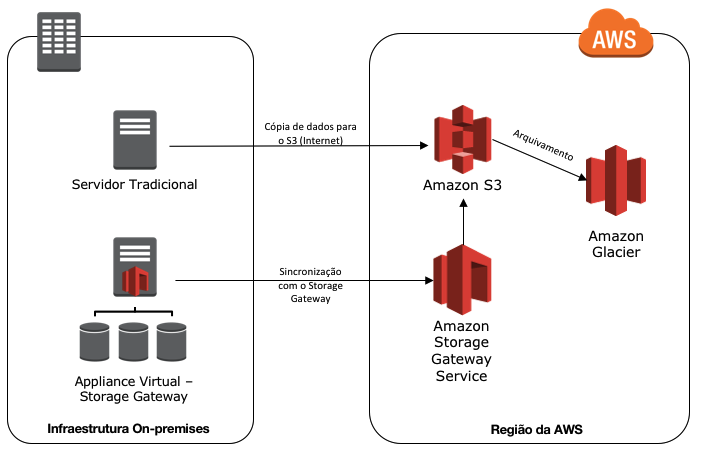
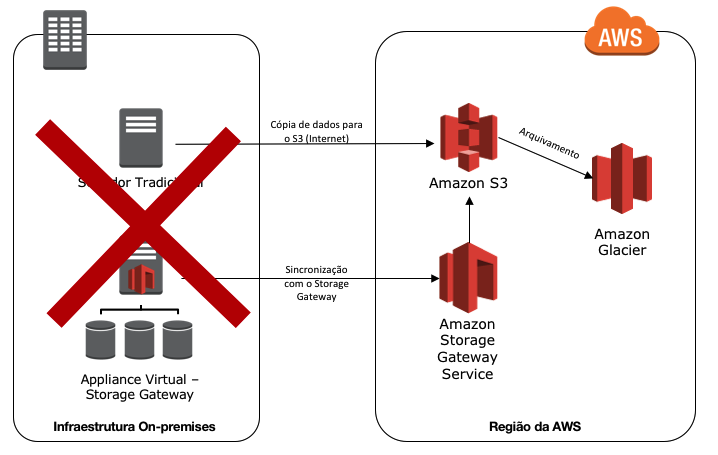
Utilizando storage gateway
O serviço de Storage Gateway facilita a comunicação com a nuvem computacional. Com isso, você consegue escolher entre as três modalidades existente, qual mais se adequa para a sua necessidade. O detalhamento das modalidades será exposto abaixo:
- Gateway-Cached Volumes: Pode armazenar seus dados no Amazon S3 e reter os dados mais acessados em seus discos locais. Nessa modalidade, o tamanho do seu repositório, pode ser maior que o disco físico disponível. É uma excelente opção, caso você queira economizar com armazenamento e deseja ter uma latência menor para os dados mais acessados.
- Gateway-Stored Volumes: Nessa modalidade, caso deseje uma baixa latência à todos os dados armazenados on-premises e de forma assíncrona realizar backups para o Amazon S3.
- Gateway-Virtual Tape Library (VTL): Utilizando dessa modalidade, você possuirá uma biblioteca virtual de fitas, as quais podem ser plugadas em seus softwares de backup. A persistência dos dados será feita em Amazon S3 ou em Glacier.
Utilizando ferramentas de parceiros
Para realizar backup de dados, existem ferramentas de parceiros da AWS[13], que facilitam o sincronismo de dados. Fornecendo diversas funcionalidades, desde de possibilidade de persistência dos dados em S3 e/ou Glacier, assim como a realização de agendamentos de backups ou envio de dados em tempo real.
Dessa forma, você pode realizar schedule do sincronismos de pastas específicas existentes no ambiente de forma simples e rápida. No entanto, com a utilização de ferramentas de parceiros, caso a funcionalidade desejada, não esteja disponível, não terá flexibilidade de customizar algo para atender as suas necessidades.
Desenvolvendo suas aplicações/scripts
A AWS possui ricas API[14] e CLI[15], sendo assim, você poderá construir suas aplicações e scripts da forma que desejar, atendendo aos requisitos necessários do seu negócio.
Conclusão
A Amazon Web Services e seus parceiros fornecem uma série de serviços e ferramentas os quais permitem a realização de Disaster and Recovery.
A AWS possui serviços os quais são pagos sob regime de demanda, onde paga-se apenas pelos recursos os quais foram utilizados. Sendo isso, um dos principais benefícios para utilizar em workloads de DR.
É interessante que tenha em mente que os principais pontos, os quais guiarão na elaboração da arquitetura ideal serão o RTO, RPO e o investimento.
Leitura adicional
Para maior aprofundamento do assunto abordado nesse artigo, sugerimos as leituras de:
- AWS Security and Compliance Center
- AWS Architecture Center
- Utilizando AWS para Disaster Recovery
- [1] http://docs.aws.amazon.com/pt_br/AmazonVPC/latest/UserGuide/VPC_VPN.html
- [2] http://docs.aws.amazon.com/pt_br/Route53/latest/DeveloperGuide/creating-migrating.html
- [3] http://docs.aws.amazon.com/pt_br/Route53/latest/DeveloperGuide/dns-failover-configuring.html
- [4] http://docs.aws.amazon.com/pt_br/AutoScaling/latest/DeveloperGuide/as-register-lbs-with-asg.html
- [5] http://docs.aws.amazon.com/pt_br/AWSEC2/latest/UserGuide/ec2-instance-resize.html
- [6] http://dev.mysql.com/doc/refman/5.7/en/replication.html
- [7]http://docs.aws.amazon.com/pt_br/AmazonRDS/latest/UserGuide/MySQL.Procedural.Importing.External.Repl.html
- [8] http://docs.aws.amazon.com/pt_br/AWSEC2/latest/UserGuide/ec2-instance-resize.html
- [9] https://docs.mongodb.org/manual/replication/
- [10] https://docs.mongodb.org/manual/tutorial/deploy-geographically-distributed-replica-set/
- [11] http://redis.io/topics/replication
- [12] http://redis.io/commands/cluster-failover
- [13] https://aws.amazon.com/pt/backup-recovery/partner-solutions/
- [14] http://docs.aws.amazon.com/pt_br/AmazonS3/latest/API/Welcome.html
- [15] https://aws.amazon.com/pt/cli/
***
Artigo escrito por Cláudio Freire Jr.
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.