Arquitetura Lambda para processamento Batch e Tempo Real na AWS com Spark Streaming e Spark SQL
Você aprenderá quais artefatos utilizar e como configurar itens de infraestrutura como instâncias de computação, ações de bootstrap, armazenamento, segurança e rede.

Neste artigo, você aprenderá quais artefatos utilizar e como configurar itens de infraestrutura como instâncias de computação, ações de bootstrap, armazenamento, segurança e rede. Ao final, você deve possuir uma boa ideia de como configurar, implementar e entregar os componentes de uma Arquitetura Lambda típica através da AWS.
Introdução
Quando do processamento de um alto volume de dados semiestruturados, sempre há um atraso entre o momento em que um dado é coletado e sua disponibilidade nos dashboards. Frequentemente, o atraso é resultado da necessidade de validação ou da identificação de dados volumosos. Em alguns casos, contudo, ser capaz de reagir imediatamente a novos dados é mais importante que estar 100% certo sobre sua validade.
A ferramenta da AWS frequentemente utilizada para lidar com grandes volumes de dados semiestruturados, ou não, é o Amazon Elastic MapReduce (Amazon EMR). Através de processamento em tempo real (ou streaming), a ingestão de um alto fluxo de dados é possível com soluções de Arquitetura Lambda, que incluem os serviços Amazon Kinesis, Amazon Simple Storage Service (Amazon S3), Spark Streaming e o Spark SQL sendo executados em um cluster do Amazon EMR cluster.
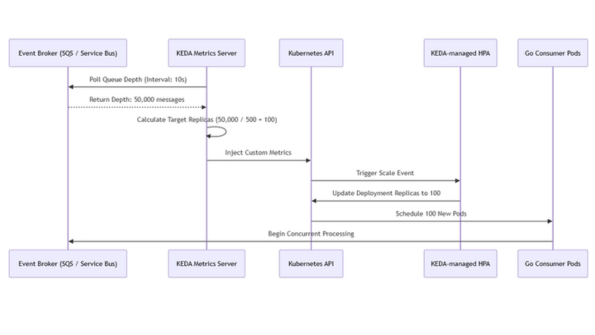
A abordagem de Arquitetura Lambda mistura recursos de processamento de dados em batch (lote) e tempo real (streaming) e é dividida em três camadas de processamento: camada batch (lote), camada serving (servidora) e camada speed (tempo real), conforme mostra a figura a seguir.
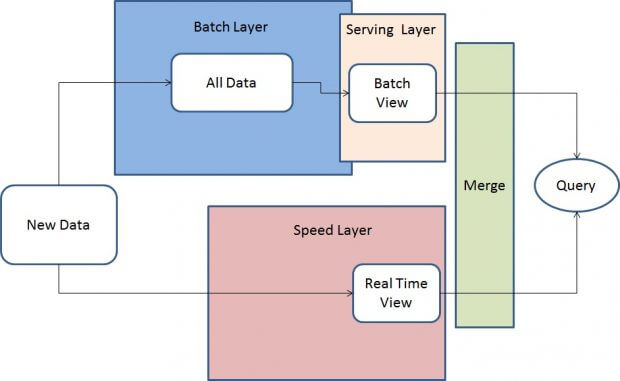
Todos os novos dados (em formato JSON) são enviados tanto para a Camada Batch (Amazon Kinesis, Amazon EMR, Amazon S3) quanto para a Camada Speed (Amazon Kinesis, Amazon EMR, Spark Streaming). Na Camada Batch, novos dados são adicionados ao data set principal, um conjunto de arquivos que contém informações que não são derivadas de outras fontes de informação. Ele é um conjunto de dados imutável que aceita apenas incrementos e é armazenado em um bucket S3. A Camada Batch pré-processa funções de query continuamente em um loop ‘while (true)’. Esse processo é análogo ao de de extração, transformação e carga (ETL) realizado no Amazon EMR pelo Spark SQL.
- Camada Batch: Os resultados desta camada são chamados de visões batch e são armazenados no Amazon S3 como um arquivo texto separado por tabulações;
- Camada Serving: Esta camada indexa as visões batch produzidas pela Camada Batch. Basicamente, a Camada Serving é uma base de dados escalável que se atualiza nas visões batch quando estas se tornam disponíveis. Devido a latência da Camada Batch, os resultados da Camada Serving sempre possuem um atraso de algumas horas;
- Camada Speed: Esta camada compensa a alta latência de atualização da Camada Serving. Ela utiliza um engine Spark em memória de alta velocidade para processar dados que ainda não foram processados pelo último lote da Camada Batch. Ela produz visões em tempo real que estão sempre atualizadas e as armazena em bases de dados tanto para operações de leitura quanto escrita. A Camada Speed é mais complexa que a Camada Batch porque as visões em tempo real são continuamente descartadas quando os novos dados são processados e entregues pelas as Camadas Batch e Serving.
Queries são disponibilizadas através da junção das visões batch e tempo real, que podem se implementadas via aplicações Spark, serviços AWS como DynamoDB, RDS, Redshift, EMR com HBase ou ferramentas open-source. Como as visões batch são sempre recalculadas, é possível ajustar a granularidade do dado em função de sua idade. Outro benefício do recálculo dos dados a partir do início é que, se as visões batch e/ou tempo real ficarem corrompidas, como o data set principal é somente leitura, porém incremental, é simples reiniciar o processamento das visões e recuperá-las de um estado não confiável. Finalmente, o usuário final pode obter a última versão dos dados, que estão sempre disponíveis na Camada Speed.
Uma abordagem bem estabelecida para unificar dados históricos com dados em tempo real é utilizar conjuntamente Hadoop e Apache Storm. Estes engine produzem tabelas específicas na Camada Serving e quando uma aplicação faz uma query, ela pode unificar os resultados, conforme mostra a figura a seguir.

Uma característica ruim das Arquiteturas Lambda tradicionais é que você deve manter o código responsável por produzir queries em dois sistemas complexos, distribuídos e diferentes.
Componentes de uma Arquitetura Lambda na AWS
O serviço Amazon EMR simplifica o processamento de informação para big data provendo um framework Hadoop gerenciado pela AWS que é simples, veloz e de custo controlado que permite a distribuição e o processamento de um grande volume de dados em instâncias EC2 dinamicamente escaláveis. A aplicação responsável pelo processamento pode ser escrita em linguagens de programação de alto nível como Java, Scala e Python.
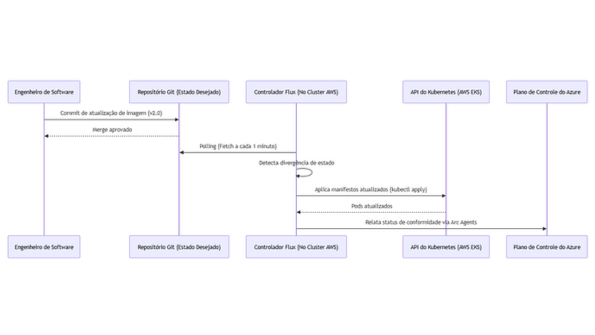
A figura a seguir mostra uma implementação de Arquitetura Lambda na AWS:
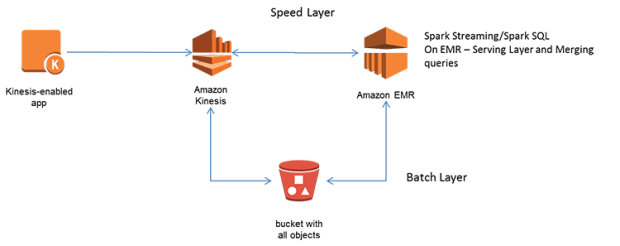
Os dados em tempo real são ingeridos pelo sistema através do Amazon Kinesis e agregados e armazenados em um bucket S3. Assim, todos os dados históricos residem no Amazon S3.
Esta arquitetura inclui uma Camada Speed com Spark Streaming implementado em um cluster Amazon EMR que consome dados a partir dos streams do Amazon Kinesis. A Camada Batch com Spark SQL no cluster Amazon EMR consome dados do Amazon S3. Ambos componentes são parte de uma mesma base de código, que pode ser acionada sob demanda, reduzindo assim o overhead da manutenção de múltiplas bases de código.
Esta sessão descreve cada componente desta implementação de Arquitetura Lambda.
Amazon Kinesis e KCL (Kinesis Client Library)
O Amazon Kinesis é um serviço gerenciado pela AWS que pode armazenar e processar terabytes de dados na forma de streams. Com o Amazon Kinesis, desenvolvedores podem continuamente capturar os dados de milhares de fontes, incluindo clickstreams de websites, dados de transações financeiras, feeds de mídia social, logs de servidores etc. É possível utilizar o Amazon Kinesis Client Library (KCL) para desenvolver aplicações que processam estes streams. Estas aplicações podem consumir os streams de dados e tomar ações em tempo real, como prover dados para dashboards, implementar lógica de tomada de decisões, gerar alertas e ingerir dados para alimentar outros serviços como o Amazon S3 e o Amazon Redshift, entre outros.
O KCL possui suporte para lidar com decisões complexas como adaptações a mudanças no volume do stream, balanceamento de carga dos streams, coordenar serviços de workers distribuídos e processamento de dados com tolerância a falhas. O KCL auxilia o desenvolvedor a integrar o Amazon Kinesis com outros serviços como o Amazon DynamoDB, Amazon Redshift e o Amazon S3.
Amazon EMR
O Amazon EMR prove acesso ao Hadoop, um framework open-source que pode ser utilizado para distribuir e processar dados e um cluster escalável de instâncias de computação do Amazon EC2. O Amazon EMR também pode executar outros frameworks de processamento distribuído como o Apache Spark, que provê um engine de computação em memória de alta velocidade.
Amazon S3
O Amazon S3 provê aos desenvolvedores um repositório de armazenamento de objetos seguro e durável.
Spark Streaming
O Spark Streaming é uma extensão da API do Spark que pode ser instalada em um cluster Amazon EMR através de recursos de bootstrapping. Ele habilita processamento tolerante a falhas de dados em tempo real. Dados são ingeridos pelo Amazon Kinesis e processados utilizando algoritmos complexos. Algoritmos do Spark para aprendizado de máquina e processamento de grafos podem ser aplicados nos streams de dados. E os dados processados podem ser enviados para dashboards, sistemas de arquivos como HDFS e para o Amazon S3.
Spark SQL
Assim como o Spark Streaming, o Spark SQL também é uma extensão importante da API do Spark e pode ser instalada em um cluster Amazon EMR através de recursos de bootstrapping. Ele permite a execução de consultas relacionais expressas em SQL ou HiveQL no código Spark e com integração de APIs em Java, Scala ou Python. Esta integração significa a possibilidade de execução de queries SQL junto com algoritmos analíticos bastante complexos.
Instalação de Arquitetura Lambda na AWS
O primeiro passo da instalação é configurar um cluster Amazon EMR com a API do Spark. Execute o comando a seguir para criar um cluster de três nós do Amazon EMR, instalar o Spark e instalar o pacote do SBT (Simple Built Tool).
./elastic-mapreduce –create –alive –name SparkCluster \ –hive-interactive –instance-type m3.xlarge \ –instance-count 3 –ami-version 3.2.1 \ –bootstrap-action “s3://support.elasticmapreduce/spark/install-spark” \ –bootstrap-name “Install Spark” –jar s3://elasticmapreduce/libs/script-runner/scriptrunner. jar \ –args “s3://elasticmapreduce.bootstrapactions/sbt/installsbt”
ou
aws emr create-cluster –name SparkCluster \ –ami-version 3.2 –instance-type m3.xlarge –instancecount 3 \ –ec2-attributes KeyName=<<MYKEY>> \ –bootstrap-actions Path=s3://support.elasticmapreduce/spark/installspark, Name=Install_Spark \ –steps Name=Install_Sbt,Jar=s3://elasticmapreduce/libs/scriptrunner/ scriptrunner. jar,ActionOnFailure=CONTINUE,Args=s3://elasticmapred uce.bootstrapactions/sbt/install-sbt \ –termination-protected
Compile o pacote no nó mestre do Amazon EMR.
mkdir ~/workspace cd ~/workspace wget https://s3.amazonaws.com/chayelpublic/ LambdaArchitecturePattern.zip unzip LambdaArchitecturePattern.zip sbt package
Enviando dados para o Amazon Kinesis
Um produtor do Amazon Kinesis gera dados em JSON e os envia para o Amazon Kinesis através do KCL.
// Download JAR: wget http://chayelpublic. s3.amazonaws.com/KinesisProducer.jar java –jar KinesisProducer.jar //Publishes 10K events to Kinesis stream myStream
A seguir, um trecho do stream JSON gerado pelo produtor:
{“zipcode”:95126,”ProductName”:”product2″,”price”:16,”times
tamp”:”2014-11-01 19:35:41.158″}
{“zipcode”:98029,”ProductName”:”product4″,”price”:51,”times
tamp”:”2014-11-01 19:35:41.323″}
{“zipcode”:96194,”ProductName”:”product40″,”price”:11,”time
stamp”:”2014-11-01 19:35:41.438″}
………
Processamento em tempo real com Spark Streaming
Para se conectar no nó mestre, abra um terminal em sua máquina e execute o comando a seguir:
/home/hadoop/spark/bin/spark-submit –master local[3] – class “RealTime” /home/hadoop/workspace/target/scala- 2.10/simple-project_2.10-1.0.jar myStream https://kinesis.us-east-1.amazonaws.com
O objeto de streaming RealTime recebe o stream do Amazon Kinesis em intervalos de um segundo e, através de sintaxe SQL, consulta o Resilient Distributed Dataset (RDD). Ele então escreve os dados em um arquivo (HDFS ou Amazon S3). O dado é movido de sua localização histórica (mostrado no exemplo a seguir comomyS3Bucket) através da API do Hadoop.
Processamento batch com Spark SQL
Abra um terminal em sua máquina e execute o comando a seguir:
/home/hadoop/spark/bin/spark-submit –master yarn-client – class “Historical” /home/hadoop/workspace/target/scala- 2.10/simple-project_2.10-1.0.jar myS3Bucket
Neste momento, você configurou e executou com sucesso todos os componentes da Arquitetura Lambda. A partir daqui é possível iniciar o desenvolvimento de uma aplicação unificada que integra processamento batch e tempo real em uma única base de código.
Removendo os componentes
Depois de executar queries com o Spark SQL, você pode desligar o seu cluster para eliminar custos adicionais.
- Em sua maquina local, execute o comando a seguir para eliminar o cluster Amazon EMR. Substitua o trecho j-xxxxxx com o identificador do seu cluster.
elastic-mapreduce –terminate -j j-xxxxxx
- Remova todos os arquivos de log armazenados no bucket Amazon S3 s3://myS3bucket, onde myS3bucket é o nome do bucket especificado no lançamento do fluxo de trabalho. Para mais informações, veja Deletando um Objeto.
Conclusão
A Arquitetura Lambda descrita neste artigo é um padrão arquitetural unificado para processamento batch (lote) e tempo real (stream) utilizando uma única base de código. Através das APIs do Spark Streaming e Spark SQL é possível implementar lógica de negócios uma única vez e reutilizá-la em processos batch e processos em tempo real. Assim, você pode implementar facilmente uma camada em tempo real para complementar a de processamento batch. No longo prazo, esta arquitetura pode reduzir custos de manutenção, mas também o risco de erros resultantes de bases de código duplicadas.
***
Artigo escrito por Glauber Gallego.
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.