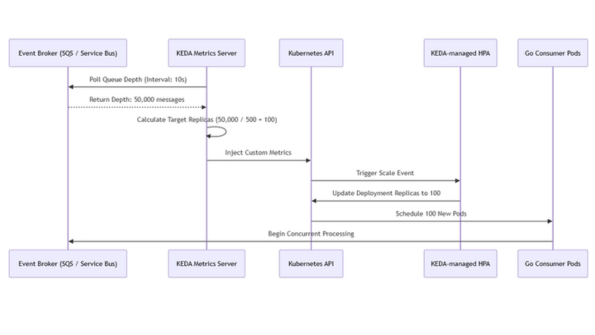
Amazon Machine Learning – Tomada de decisões orientadas por dados em escala
A ciência do Aprendizado de Máquina fornece os fundamentos matemáticos necessários para executar a análise e fazer com que os resultados tenham sentido.

Hoje, é relativamente simples e barato observar e coletar grandes quantidades de dados operacionais sobre um sistema, produto ou processo. Não surpreendentemente, pode haver enormes quantidades de informações enterradas dentro de gigabytes de dados relativos às compras dos clientes, trilhas de navegação em web sites, ou respostas a campanhas de e-mail. A boa notícia é que todos esses dados podem, quando analisados corretamente, levar a resultados estatisticamente significativos, que podem ser usados para tomar decisões de alta qualidade. A má notícia é que você precisa encontrar cientistas de dados com experiência relevante em aprendizado de máquina, e espero que a sua infra-estrutura seja capaz de suportar seu conjunto ferramenta, e espero (mais uma vez) que o conjunto de ferramentas seja suficientemente confiável e escalável para uso em produção.
A ciência do Aprendizado de Máquina (muitas vezes abreviado como ML, do inglês Machine Learning) fornece os fundamentos matemáticos necessários para executar a análise e fazer com que os resultados tenham sentido. Ela pode ajudá-lo a transformar todos esses dados em previsões de alta qualidade, encontrando e codificando padrões e relações dentro dos dados. Usado corretamente, o Aprendizado de Máquina pode servir como base para sistemas que realizam a detecção de fraudes (é esta transação legítima ou não?), previsão de demanda (quantas widgets esperamos vender?), segmentação de anúncios (quais anúncios devem ser mostrados para quais utilizadores?) e assim por diante…
Introduzindo o Amazon Machine LearningHoje introduziremos o Amazon Machine Learning, este novo serviço da AWS que ajuda você a usar todos os dados que tenha recolhido para melhorar a qualidade das suas decisões. Você pode construir e ajustar modelos preditivos usando grandes quantidades de dados e, em seguida, usar o Amazon Machine Learning para fazer previsões (em lote ou em tempo real) em grande escala. Você pode se beneficiar do aprendizado de máquina, mesmo se você não tem um grau avançado em estatísticas ou o desejo de configurar, executar e manter a sua própria infra-estrutura de processamento e armazenamento.
Entrarei nos detalhes em breve. Mas antes, eu gostaria de rever algumas das terminologias e conceitos que você precisa saber para entender completamente o que a aprendizagem de máquina faz e como você pode tirar vantagem disso.
Introdução ao Aprendizado de MáquinaA fim de se beneficiar do aprendizado de máquina, você precisa ter alguns dados existentes para que você possa usar para treinamento. É útil pensar nos dados de treinamento como linhas em um banco de dados ou uma planilha. Cada linha representa um elemento de dados único (uma compra, uma transferência, ou um item de catálogo). As colunas representam os atributos do elemento: CEP do cliente, preço de compra, tipo de cartão de crédito, tamanho do item, e assim por diante…
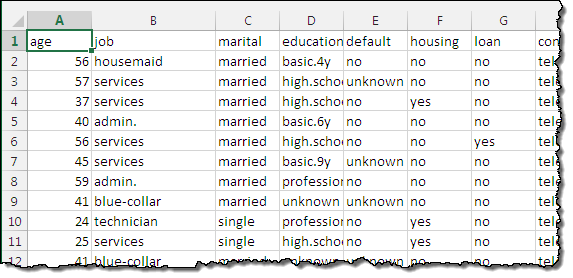
Estes dados de treinamento deve conter exemplos de resultados reais. Por exemplo, se houverem linhas que representam as operações concluídas, que foram, ou legítimas ou fraudulentas, cada linha deve conter uma coluna que indica esse resultado, que é também conhecido como variável de interesse. Esses dados são usados para criar um modelo de aprendizado de máquina que, quando alimentado com novos dados sobre a operação proposta, irá retornar uma previsão quanto à sua validade. O Amazon Machine Learning suporta três tipos distintos de previsões: classificação binária, a classificação de multiclasses, e de regressão. Vamos dar uma olhada em cada uma delas:
- Classificação binária é utilizada para prever um dos dois resultados possíveis. Esta transação é legítima, o cliente vai comprar este produto, ou este endereço de entrega é um complexo de apartamentos?
- Classificação de multiclasses é utilizada para prever um de três ou mais resultados possíveis, e a probabilidade de cada um. Este produto é um livro, um filme ou uma peça de roupa? Este filme é uma comédia, um documentário ou um filme de suspense? Qual categoria de produtos é de maior interesse para este cliente?
- A regressão é utilizada para prever um número. Quantas monitores de 27″ devemos colocar no inventário? Quanto devemos cobrar por eles? Qual porcentagem deles são susceptíveis a serem vendidos como presentes?
Um modelo devidamente treinado pode ser usado para responder a qualquer uma das perguntas acima. Em alguns casos, é adequado usar os mesmos dados de formação para construir dois ou mais modelos.
Você deve planejar passar algum tempo enriquecendo os seus dados, a fim de garantir uma boa correspondência para o processo de treinamento. Como um exemplo simples, você pode começar com os dados de localização, que é baseada em CEPs ou códigos postais. Depois de algumas análises, você pode descobrir que você pode melhorar a qualidade dos resultados usando uma representação local diferente que contém maior ou menor resolução. O processo de treinamento da ML é iterativo; você deve definitivamente passar algum tempo entendendo e avaliando seus resultados iniciais e, em seguida, usá-los para enriquecer seus dados.
Você pode medir a qualidade de cada um de seus modelos usando um conjunto de métricas de desempenho, que são computados e disponibilizados para você. Por exemplo, a área sob a curva (AUC, do inglês Area Under Curve) é uma métrica de desempenho de classificações binárias. Este é um valor de ponto flutuante na faixa de 0,0 a 1,0, que expressa a frequência com que o modelo prevê a resposta correta em dados que não foram usados no treinamento. Esses valores aumentam de 0,5 para 1,0 quando a qualidade do modelo aumenta. Uma pontuação de 0,5 não é melhor que de adivinhação aleatória, enquanto que 0,9 seria um modelo muito bom para a maioria dos casos. Mas uma pontuação de 0,9999 é provavelmente muito boa para ser verdade, e pode indicar um problema com os dados de treinamento.
Caso você construa seu modelo de previsão de binário, você terá que gastar algum tempo olhando para os resultados e ajustando um valor conhecido como o cut-off. Ele representa a probabilidade de que a predição é verdadeira; você pode ajustá-lo para cima ou para baixo com base na importância relativa de falsos positivos (predições que devem ser falsas, mas foram previstos como verdadeiras) e falsos negativos (previsões de que deve ser verdadeiras, mas foram previstas como falsas) em sua situação particular. Se você estiver construindo um filtro de spam para e-mail, um falso negativo encaminhará uma parte do spam para sua caixa de entrada e um falso positivo encaminhará uma parte dos e-mails legítimos para a pasta de lixo eletrônico. Nesse caso, falsos positivos são indesejáveis. O compromisso entre falsos positivos e falsos negativos vai depender do seu problema e como você pretende fazer uso do modelo em um ambiente de produção.
Amazon Machine Learning em açãoVamos percorrer o processo de criação de um modelo e gerando algumas previsões utilizando os passos descritos na seção tutorial do Guia do desenvolvedor do Amazon Machine Learning. Você pode se inscrever no Amazon Machine Learning e seguir os passos do guia por conta própria, caso queira. O guia usa uma cópia ligeiramente melhorada do conjunto de dados de marketing do banco de dados à disposição do público a partir do repositório UC Irvine Machine Learning. O modelo que vamos construir vai responder a pergunta “Será que o cliente vai assinar o meu novo produto?”.
Eu baixei uma cópia do banking.csv e carreguei-a no Amazon Simple Storage Service (S3), e, em seguida, concordei em permitir que o console adicione uma política IAM para que o Amazon Machine Learning tenha acesso ao arquivo.
Então eu crio um objeto Amazon Machine Learning Datasource referenciando o item no bucket e fornecendo um nome para o objeto. Este objecto contém o local dos dados, os nomes e tipos das variáveis, o nome da variável de interesse, e as estatísticas descritivas para cada variável. A maioria das operações dentro do Amazon Machine Learning referenciam uma fonte de dados. Aqui está como eu defini tudo:
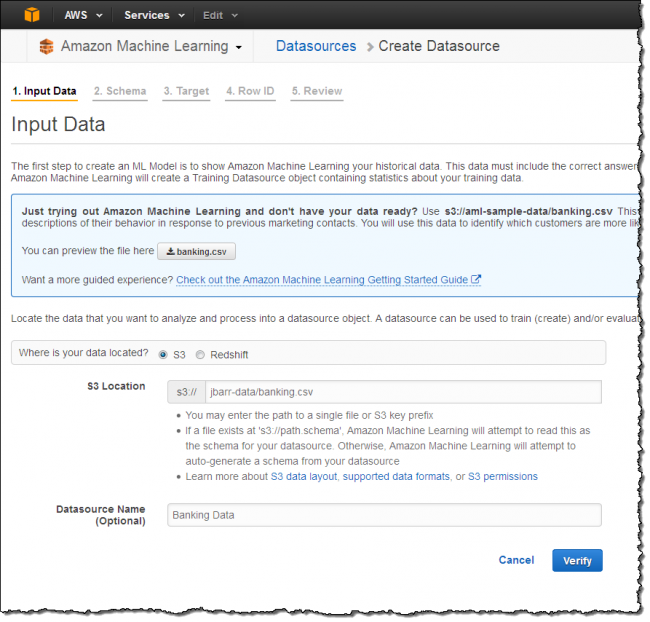
O Amazon Machine Learning também pode criar uma fonte de dados no Amazon Redshift ou um banco de dados no Amazon RDS MySQL. Selecionando a opção Redshift mostrada acima teria me dado a opção de inserir o nome do meu agrupamento Amazon Redshift, juntamente com um nome de banco de dados, as credenciais de acesso, e uma consulta SQL. A API do aprendizado máquina pode ser usada para criar uma fonte de dados a partir de um banco de dados do Amazon RDS for MySQL.
O Amazon Machine Learning abre e lê o arquivo, depois faz um palpite sobre os tipos de variáveis, e, em seguida, propõe o seguinte esquema:
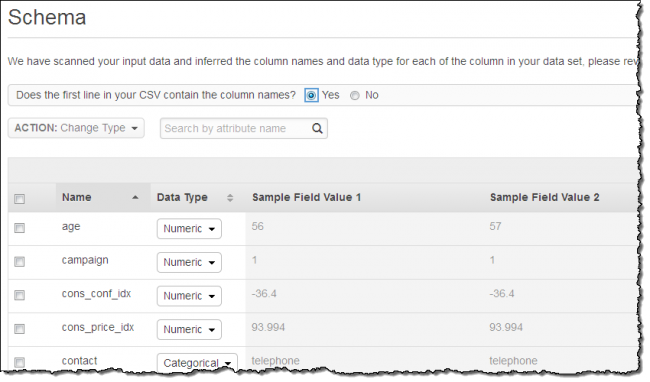
Neste caso, todas as suas suposições estavam corretas. Se não estivessem, eu poderia selecionar uma ou mais linhas e clicar em Change Type de corrigi-los.
Como eu vou usar a fonte de dados para criar e avaliar um modelo ML, eu preciso selecionar a variável de treinamento. Neste conjunto de dados, a variável de treinamento (y) tem o tipo de dados binários de modo que os modelos gerados a partir dela usará classificação binária.
Depois de mais alguns cliques, eu estava pronto para criar a minha fonte de dados:
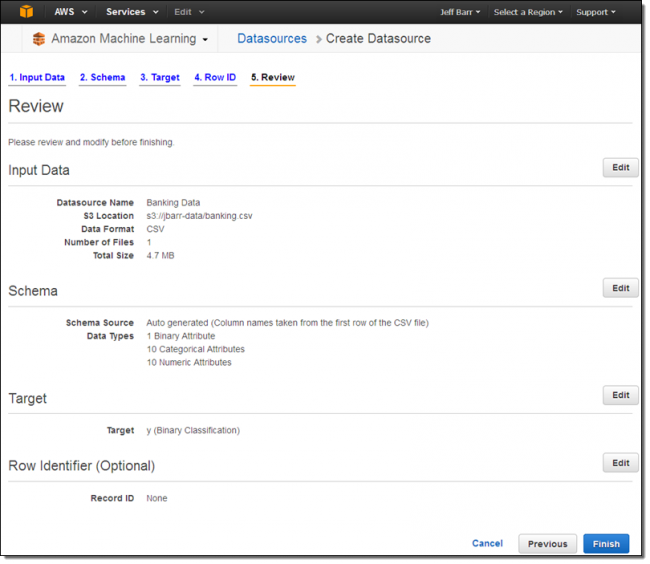
Minha fonte de dados estava pronta em um ou dois minutos:
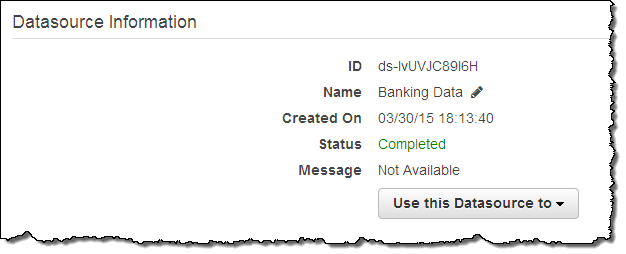
Como eu havia sugerido antes, você pode melhorar seus modelos conhecendo bem os seus dados. O Amazon Machine Learning Console oferece várias ferramentas diferentes que você pode usar para aprender mais. Por exemplo, você pode olhar para a distribuição dos valores para qualquer uma das variáveis em uma fonte de dados. Aqui está o que eu vi quando inspecionei a variável idade (age) da minha fonte de dados:

O próximo passo é criar o meu modelo:
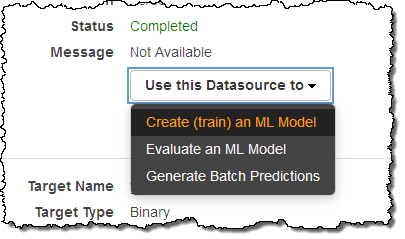
Preferi usar as configurações padrão. O Amazon Machine Learning usou 70% dos dados para treinamento e 30% para avaliar o modelo:

Se eu tivesse escolhido a opção Personalizar (Custom), eu teria tido a oportunidade de personalizar a “receita” que o Amazon Machine Learning usa para transformar e processar os dados da fonte de dados:
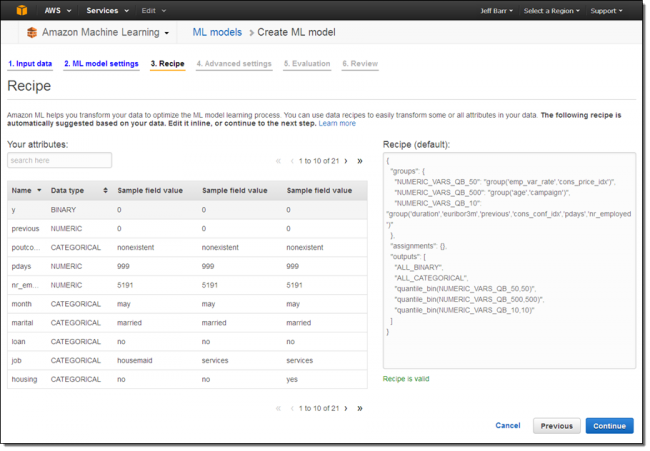
Após mais alguns cliques, o Amazon Machine Learning começa a criar o meu modelo. Eu dei uma pausa rápida para regar as verduras no meu jardim e quando voltei descobri que o meu modelo já estava pronto:
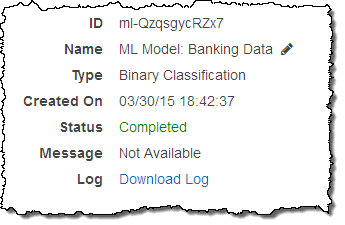
Dei uma olhada rápida nas métricas de desempenho:
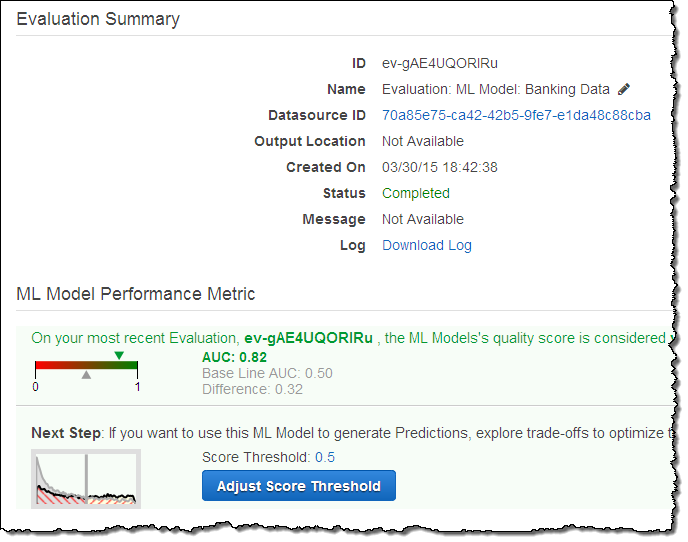
A fim de selecionar os melhores e mais interessante (aqueles com maior probabilidade de fazer uma compra), eu cliquei em Adjust Score Threshold e aumentei valor do cut-off até que 5% dos registros esperados passassem a prever um valor de “1” para y:
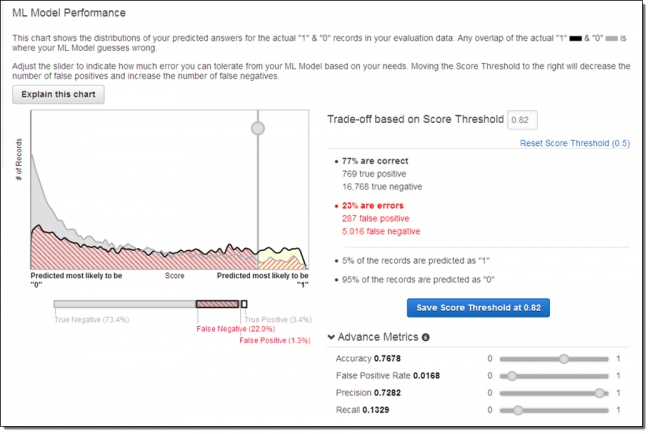
Com esta definição, apenas 1,3% das previsões serão falsos positivos, 22% serão falsos negativos, e 77% serão previsões corretas. Escolhi tornar o custo dos falsos positivos mais altos, fixando um valor mais alto de corte, a fim de evitá-los. Em termos, empresariais essa configuração me permite evitar o envio de materiais promocionais caros para os clientes “errados”.
Com o meu modelo construído, agora eu posso usá-lo para criar previsões em lote (em inglês, batch predictions), lembremos que o Amazon Machine Learning suporta previsões tanto em lote, quanto em tempo real. O modelo em lote me permite gerar um conjunto de previsões para um conjunto de observações de uma vez. Eu começo a partir do menu:
Criei uma outra fonte de dados usando o arquivo recomendado pelo Guia de Introdução. Este processo, ao contrário do primeira, não contém os valores para a variável y.
Então eu selecionei um local (no S3) para armazenar as previsões, revisei minhas escolhas, e iniciei a previsão em lote:
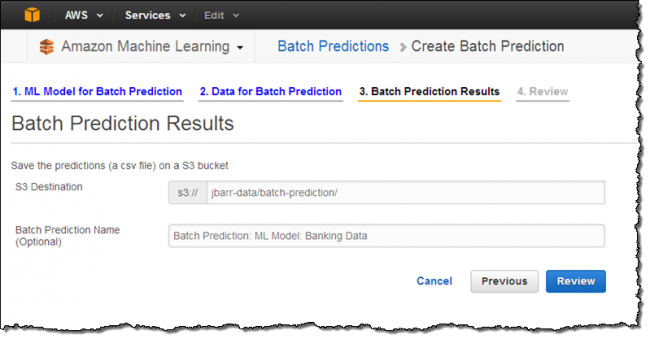
Depois de mais uma visita rápida ao meu jardim, minhas previsões estavam prontas! Baixei o arquivo para o bucket, descompactei e aqui está o que vi:
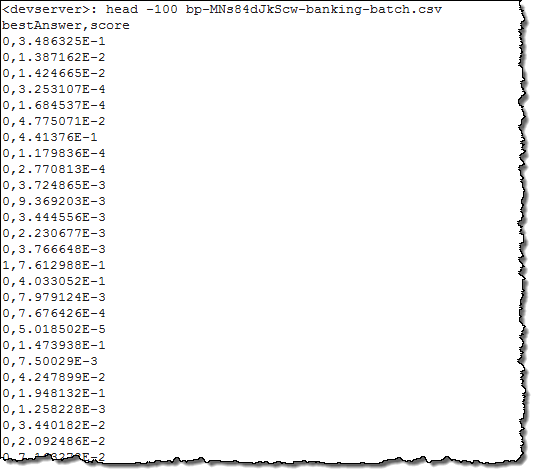
As linhas correspondem às do arquivo original. O primeiro valor é a variável y prevista (calculada através da comparação do escore de predição contra o corte que eu defini quando eu estava construindo o modelo) e, o segundo é a pontuação real. Se eu tivesse incluído um Identificador de Linha, cada previsão incluiria uma “chave primária” única que permite-me amarrar os resultados de volta para os dados de origem.
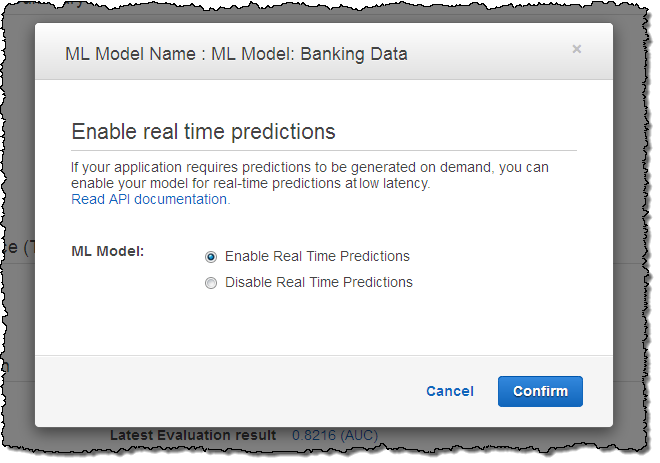
Se estou construindo uma aplicação em tempo real e preciso gerar previsões como parte de um ciclo de solicitação-resposta, eu posso habilitar um modelo de previsões em tempo real como este:

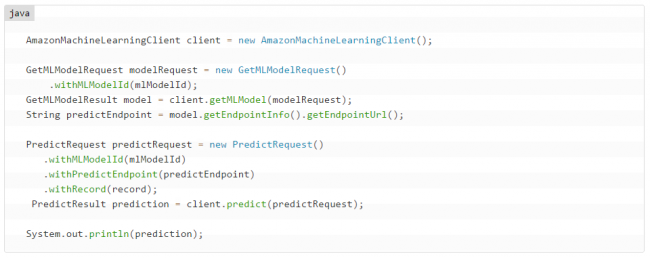
Depois que as previsões em tempo real forem habilitadas, posso escrever um código para chamar a função Predict do Amazon Machine Learning. Aqui está algum código Java que recupera os metadados associados a um modelo ML (mlModelId no código), encontra o terminal de serviço nos metadados, faz uma previsão em tempo real, e exibe o resultado:
O código produz um saída com esse formato:
![]()
Que significa que o modelo da ML é do tipo de classificação binária, a pontuação predita foi 0.10312237, e com base no limiar de previsão, relacionado com o modelo quando o código foi executado, a resposta prevista era ‘0’.
Confira nossos exemplos de Aprendizado de Máquina para ver alguns exemplos de código (Python e Java) para marketing direcionado, monitoramento de mídia social, e as previsões móveis.
Coisas para saberO Amazon Machine Learning já está disponível e você já pode começar a usá-li na região leste dos EUA (Norte da Virginia).
O preço, como de costume, está em uma base pay-as-you-go:
- A análise dos dados, o treinamento do modelo, e avaliação do modelo custará US $ 0,42 por hora de computação.
- Previsões em lote custarão US$ 0,10 para cada 1.000 previsões, arredondado para a próxima 1.000.
- Previsões em tempo real custão US$ 0,10 para cada 1.000 previsões mais uma taxa de capacidade horária reservada de US $ 0,001 por hora para cada 10 MB de memória provisionados para o seu modelo. Durante a criação do modelo, você deve especificar o tamanho máximo de memória de cada modelo para gerenciar o custo e para controlar o desempenho preditivo.
- Encargos de dados armazenados no S3, Amazon RDS e Amazon Redshift são cobradas separadamente.
Para saber mais sobre o Amazon Machine Learning, leia a documentação do Amazon Machine Learning!
***
Este artigo faz parte do AWSHUB, rede de profissionais AWS gerenciado pelo iMasters.