

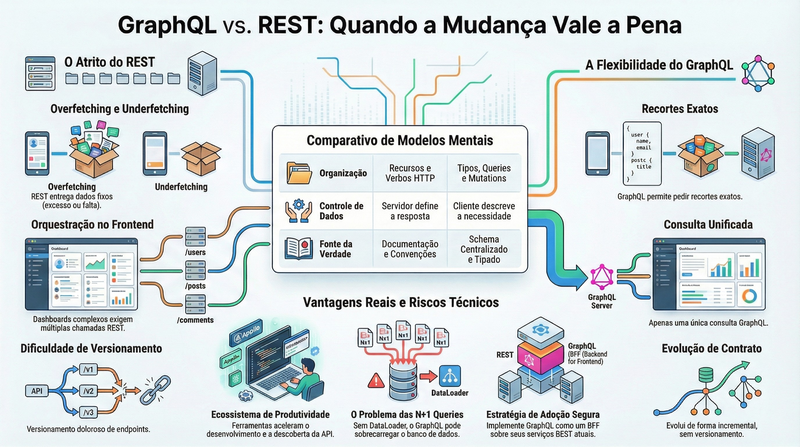
REST virou padrão por um motivo simples: ele funciona. Durante anos, foi a escolha natural para expor recursos, integrar sistemas, alimentar frontends e organizar contratos de APIs em praticamente qualquer stack. Para muita gente, ainda é.
Mas existe um ponto em que REST começa a cobrar um preço alto demais. E esse preço não aparece no primeiro endpoint. Ele aparece quando o produto cresce, quando o frontend precisa montar uma tela com dados de várias fontes, quando mobile e web querem payloads diferentes, quando o versionamento começa a doer e quando a API passa a servir mais o backend do que quem realmente a consome.
É nesse momento que GraphQL deixa de parecer “alternativa interessante” e passa a merecer atenção séria de qualquer desenvolvedor sênior.
Este artigo não é um manifesto contra REST. Também não é evangelização cega. A proposta aqui é mais madura do que isso: mostrar, com exemplos práticos, onde GraphQL pode substituir REST com vantagem real, onde ele complica desnecessariamente e por que tanta gente experiente ainda rejeita a abordagem sem ter testado em um problema concreto.
Minha opinião é direta: muito time sênior ainda não experimentou GraphQL por hábito, não por critério técnico. E isso talvez esteja custando flexibilidade, produtividade e qualidade de contrato em projetos que já poderiam estar evoluindo melhor.
O ponto não é trocar REST por moda, é reduzir atrito real
REST não está errado. Em muitos cenários, ele continua sendo a melhor escolha. Um CRUD previsível, uma integração simples, um serviço enxuto com poucos recursos bem definidos, tudo isso conversa muito bem com o modelo RESTful.
O problema aparece quando o consumo deixa de ser simples.
Imagine uma tela de dashboard que precisa mostrar:
- Dados do usuário
- Lista de pedidos
- Itens de cada pedido
- Status de pagamento
- Endereço de entrega
- Total consolidado
Em REST, é comum que isso se transforme em várias chamadas:
GET /users/123
GET /users/123/orders
GET /orders/9001/items
GET /orders/9001/payment
GET /orders/9001/shipping
GET /orders/9002/items
GET /orders/9002/payment
GET /orders/9002/shipping
No começo, parece aceitável. Depois vira um acúmulo de latência, orquestração demais no frontend, endpoints especializados demais no backend e uma sensação constante de que cada nova tela exige uma pequena negociação entre times.
Agora veja o mesmo cenário com GraphQL:
query GetUserDashboard {
user(id: "123") {
id
name
email
orders {
id
createdAt
total
payment {
status
method
}
shipping {
city
state
}
items {
productName
quantity
price
}
}
}
}
Uma consulta, um contrato, um payload ajustado ao que a tela realmente precisa.
Essa é a virada de chave. Em REST, o servidor define representações por endpoint. Em GraphQL, o cliente descreve a necessidade e o servidor responde a partir de um schema tipado e consistente.
Para um desenvolvedor sênior, isso deveria acender uma luz importante. O problema aqui não é só “buscar dados de outro jeito”. O problema é custo operacional, evolução de contrato e acoplamento entre backend e consumo.
REST e GraphQL resolvem problemas parecidos, mas com modelos mentais diferentes
REST organiza a API em torno de recursos e verbos HTTP. O raciocínio clássico é este:
- `GET /users/123`
- `POST /orders`
- `PUT /products/10`
- `DELETE /carts/88`
GraphQL organiza a comunicação em torno de tipos, queries, mutations e schema:
type User {
id: ID!
name: String!
email: String!
orders: [Order!]!
}
type Order {
id: ID!
createdAt: String!
total: Float!
payment: Payment
shipping: Shipping
items: [OrderItem!]!
}
type Payment {
status: String!
method: String!
}
type Shipping {
city: String!
state: String!
}
type OrderItem {
productName: String!
quantity: Int!
price: Float!
}
type Query {
user(id: ID!): User
}
A diferença parece sutil no papel, mas muda bastante na prática.
Em REST, o contrato fica espalhado entre endpoints, payloads, convenções e documentação. Em GraphQL, o schema se torna a fonte central da verdade. Isso melhora descoberta, tipagem, evolução e comunicação entre frontend e backend.
Para equipes maduras, isso pesa muito mais do que parece. Em projetos grandes, o maior problema não costuma ser escrever mais um endpoint. O maior problema é sustentar um contrato que envelhece bem.
O ponto onde GraphQL começa a fazer muito sentido
GraphQL brilha quando há diversidade de consumo e necessidade de composição.
Alguns cenários típicos:
- Frontend web e mobile com necessidades diferentes
- Dashboards e telas de resumo com múltiplas entidades
- Backend for Frontend, BFF
- Plataformas com evolução constante de interface
- Sistemas que agregam dados de vários domínios
- APIs consumidas por diferentes times ou parceiros
Nesses contextos, REST costuma começar simples e terminar com remendos: endpoints de conveniência, parâmetros extras para customização, versões paralelas e payloads que nunca são ideais para todo mundo.
GraphQL ataca esse atrito na raiz, permitindo que o consumo seja montado a partir da necessidade real da interface ou integração.
O exemplo clássico continua válido: overfetching e underfetching
Esse é o caso mais conhecido, mas continua relevante justamente porque continua acontecendo.
Suponha um endpoint REST:
GET /products/10
Com uma resposta assim:
{
"id": 10,
"name": "Teclado Mecânico",
"description": "Teclado mecânico RGB com switches azuis",
"price": 399.90,
"stock": 27,
"category": {
"id": 3,
"name": "Periféricos"
},
"supplier": {
"id": 9,
"name": "Tech Parts",
"cnpj": "00.000.000/0001-00"
},
"createdAt": "2026-03-23T10:00:00Z",
"updatedAt": "2026-03-23T12:00:00Z"
}
Se a tela só precisa de `id`, `name` e `price`, você recebeu dados demais. Overfetching.
Se, além disso, a mesma tela também precisa da avaliação média do produto, mas essa informação está em outro endpoint, você entra no problema oposto. Underfetching.
Em GraphQL, a consulta pode ser moldada exatamente ao caso de uso:
query GetProductCard {
product(id: "10") {
id
name
price
category {
name
}
reviewsSummary {
average
total
}
}
}
Esse é um ganho concreto. O cliente deixa de depender da representação fixa definida pelo backend e passa a pedir o recorte exato de que precisa.
Como isso fica em uma implementação real de GraphQL
Vamos a um exemplo pequeno em Node.js com Apollo Server. O objetivo aqui não é montar um projeto completo, e sim mostrar como a solução deveria ser pensada.
Primeiro, o schema:
const typeDefs = `#graphql
type Category {
id: ID!
name: String!
}
type ReviewsSummary {
average: Float!
total: Int!
}
type Product {
id: ID!
name: String!
description: String
price: Float!
stock: Int!
category: Category!
reviewsSummary: ReviewsSummary!
}
type Query {
product(id: ID!): Product
products: [Product!]!
}
`;
Agora os resolvers:
const products = [
{
id: "10",
name: "Teclado Mecânico",
description: "Teclado mecânico RGB com switches azuis",
price: 399.9,
stock: 27,
categoryId: "3"
}
];
const categories = [
{ id: "3", name: "Periféricos" }
];
const reviews = {
"10": { average: 4.7, total: 125 }
};
const resolvers = {
Query: {
product: (_, { id }) => products.find(p => p.id === id),
products: () => products
},
Product: {
category: parent => categories.find(c => c.id === parent.categoryId),
reviewsSummary: parent => reviews[parent.id] || { average: 0, total: 0 }
}
};
Subindo o servidor:
import { ApolloServer } from "@apollo/server";
import { startStandaloneServer } from "@apollo/server/standalone";
const server = new ApolloServer({
typeDefs,
resolvers
});
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 }
});
console.log(`GraphQL running at ${url}`);
E a consulta:
query {
product(id: "10") {
id
name
price
category {
name
}
reviewsSummary {
average
total
}
}
}
Resposta:
{
"data": {
"product": {
"id": "10",
"name": "Teclado Mecânico",
"price": 399.9,
"category": {
"name": "Periféricos"
},
"reviewsSummary": {
"average": 4.7,
"total": 125
}
}
}
}
Aqui já aparece um dos maiores ganhos do GraphQL. O contrato não é uma resposta estática, ele é uma superfície consultável.
Criando dados: como a comparação fica entre REST e GraphQL
Vamos comparar a criação de um pedido.
Em REST:
POST /orders
Content-Type: application/json
{
"customerId": 123,
"items": [
{ "productId": 10, "quantity": 2 },
{ "productId": 11, "quantity": 1 }
],
"couponCode": "PROMO10"
}
Resposta:
{
"id": 9001,
"status": "CREATED",
"total": 799.80
}
Nada errado aqui. Em muitos casos, isso continua excelente.
Agora em GraphQL.
Schema:
input OrderItemInput {
productId: ID!
quantity: Int!
}
input CreateOrderInput {
customerId: ID!
items: [OrderItemInput!]!
couponCode: String
}
type Order {
id: ID!
status: String!
total: Float!
}
type Mutation {
createOrder(input: CreateOrderInput!): Order!
}
Resolver:
const resolvers = {
Mutation: {
createOrder: (_, { input }) => {
const total = 799.8;
return {
id: "9001",
status: "CREATED",
total
};
}
}
};
Mutation:
mutation CreateOrder {
createOrder(
input: {
customerId: "123"
items: [
{ productId: "10", quantity: 2 }
{ productId: "11", quantity: 1 }
]
couponCode: "PROMO10"
}
) {
id
status
total
}
}
O ponto não é dizer que isso é “mais bonito”. O ponto é que o contrato fica mais claro, tipado e introspectivo. Isso melhora muito a experiência de consumo e evolução.
O que muda de verdade para times sênior: evolução sem guerra de versionamento
Quem já liderou APIs usadas por vários times conhece bem esse cenário: novas telas pedem campos novos, consumidores antigos não podem quebrar, versões passam a coexistir por tempo demais e a API começa a carregar camadas de legado.
O fluxo clássico em REST costuma virar isso:
- `/v1/users`
- `/v2/users`
- `/v3/users`
A partir daí, o esforço deixa de ser só técnico. Ele vira custo operacional e político entre times.
Com GraphQL, a evolução costuma ser menos traumática. Em vez de quebrar contratos via versão, o schema pode crescer de forma incremental. Campos antigos podem ser descontinuados explicitamente.
Exemplo:
type User {
id: ID!
fullName: String!
name: String @deprecated(reason: "Use fullName")
}
Isso não elimina a necessidade de governança, mas melhora muito a forma como a API envelhece.
As vantagens reais do GraphQL
Aqui vale separar o discurso técnico sério da empolgação vazia.
GraphQL tem vantagens muito concretas.
A primeira é o contrato fortemente tipado. O schema centraliza tipos, campos, argumentos e relações. Isso melhora descoberta, documentação, geração de tipos e validação.
A segunda é reduzir overfetching e underfetching. Em interfaces complexas, esse ganho deixa de ser detalhe e passa a impactar diretamente latência e simplicidade de consumo.
A terceira é servir bem múltiplos clientes. Web, mobile, painéis internos e integrações podem consumir a mesma API com recortes diferentes.
A quarta é a evolução. Adicionar campos é barato, descontinuar também fica mais claro e controlado.
A quinta é a composição de domínios. GraphQL funciona muito bem como camada agregadora sobre múltiplas fontes, como banco relacional, banco documental, microserviços, APIs legadas ou serviços externos.
A sexta é a produtividade. Ferramentas como Apollo, GraphQL Yoga, Mercurius, Relay, urql, code generation e introspection já colocaram o ecossistema em um nível muito mais maduro do que muita gente ainda imagina.
As desvantagens também são reais, e ignorá-las é erro de arquitetura
Aqui está a parte que separa uso maduro de adoção por hype.
GraphQL não resolve tudo. Em alguns casos, ele realmente complica.
A primeira desvantagem é a modelagem. Criar um bom schema exige maturidade. Se o time não entende bem o domínio, o schema degrada rápido.
A segunda é o famoso problema de N+1 queries. Resolver relacionamentos sem cuidado pode explodir o número de consultas ao banco.
Exemplo ingênuo:
const resolvers = {
Query: {
users: async () => db.user.findMany()
},
User: {
orders: async parent => db.order.findMany({
where: { userId: parent.id }
})
}
};
Se vierem 100 usuários, isso pode virar 101 consultas.
O jeito certo normalmente envolve batching com DataLoader:
import DataLoader from "dataloader";
const orderLoader = new DataLoader(async userIds => {
const orders = await db.order.findMany({
where: { userId: { in: userIds } }
});
return userIds.map(userId =>
orders.filter(order => order.userId === userId)
);
});
const resolvers = {
User: {
orders: parent => orderLoader.load(parent.id)
}
};
A terceira desvantagem é o cache. Em REST, cache HTTP costuma ser mais direto. Em GraphQL, como muitas requisições passam por um endpoint único, a estratégia precisa ser mais sofisticada.
A quarta é segurança. Como o cliente controla a forma da consulta, você precisa tratar profundidade, complexidade, limites e abuso com muito mais atenção.
Exemplo simples de limitação por profundidade:
import depthLimit from "graphql-depth-limit";
const server = new ApolloServer({
typeDefs,
resolvers,
validationRules: [depthLimit(5)]
});
A quinta desvantagem é a mais honesta de todas: nem todo sistema precisa disso. Em APIs simples, lineares e estáveis, GraphQL pode ser mais engenharia do que valor.
A melhor forma de introduzir GraphQL sem traumatizar o projeto
A pior decisão é tentar substituir tudo de uma vez.
A melhor abordagem, na maioria dos casos, é introduzir GraphQL como camada de agregação, especialmente no modelo de BFF.
Em vez de reescrever todos os serviços, você cria uma camada GraphQL na frente do que já existe:
const resolvers = {
Query: {
async dashboard(_, { userId }, { dataSources }) {
const user = await dataSources.usersApi.getUser(userId);
const orders = await dataSources.ordersApi.getOrdersByUser(userId);
return {
user,
orders
};
}
}
};
Essa é uma porta de entrada muito saudável. Você mantém o ecossistema atual, mas oferece uma superfície de consumo melhor para os clientes que mais sofrem com a composição de dados.
Outra boa estratégia é escolher uma tela problemática e provar valor ali. Dashboard, home administrativa, resumo de cliente, perfil de usuário com múltiplas seções, todos esses cenários costumam ser bons pilotos.
E existe uma regra importante que muita equipe backend-heavy ignora: o schema não deve ser um espelho do banco. O schema deve refletir o domínio e a necessidade de consumo. Banco é persistência. Schema é contrato.
Onde eu manteria REST com a consciência tranquila
Também vale dizer com todas as letras: há vários cenários em que eu manteria REST sem culpa nenhuma.
APIs simples de CRUD continuam funcionando muito bem em REST. Integrações B2B com operações previsíveis também. Serviços com pouca composição, workloads fortemente cacheáveis por HTTP e times sem maturidade para governança de schema provavelmente se beneficiam mais de REST do que de GraphQL.
Essa é a discussão adulta. Não é “GraphQL substitui REST em tudo?”. A pergunta certa é “onde GraphQL reduz atrito de forma objetiva?”.
O erro mais comum de quem rejeita GraphQL cedo demais
Aqui vai a provocação que importa.
Muito desenvolvedor sênior rejeita GraphQL sem ter testado num caso real. Não porque analisou profundamente o contexto e concluiu que REST era melhor. Isso seria ótimo. Mas porque já conhece REST, já sofreu com ele e aprendeu a conviver com o desconforto.
Na prática, muita rejeição vem de três coisas:
- Conforto com o modelo atual
- Contato superficial com exemplos ruins
- Impressão de que GraphQL é “complexidade desnecessária”
Só que experiência sênior não deveria significar apego a ferramenta conhecida. Deveria significar critério para experimentar a ferramenta certa no problema certo.
Conclusão: o melhor momento para testar GraphQL é antes da dor virar normal
GraphQL não é remédio milagroso. Não substitui boa modelagem, não corrige arquitetura ruim e não elimina a necessidade de disciplina. Mas ele resolve, com bastante elegância, vários problemas que times experientes aceitaram por anos como inevitáveis.
Se você trabalha com frontends complexos, múltiplos consumidores, APIs compostas, evolução constante de produto e atrito frequente entre backend e consumo, já existe motivo suficiente para experimentar GraphQL de forma séria.
O caminho mais inteligente não é transformar isso em guerra religiosa entre abordagens. É escolher um fluxo real do seu sistema, implementar uma camada GraphQL pequena, medir impacto e avaliar com honestidade técnica.
Para muitos projetos, REST continuará sendo a escolha certa. Para outros, GraphQL pode ser exatamente a peça que faltava para reduzir fricção, melhorar contrato e acelerar evolução sem transformar cada nova necessidade de consumo em uma negociação entre times.
E aqui fica a provocação final, especialmente para quem já é sênior há algum tempo: se você já passou anos lidando com overfetching, endpoints de conveniência, versionamento doloroso e payloads que nunca servem perfeitamente para ninguém, talvez o conservadorismo esteja custando mais do que a curva de aprendizado.
Experimentar GraphQL hoje, com critério, pode ser menos uma aposta em novidade e mais uma decisão madura de arquitetura.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?