Dredd: faça justiça à sua API HTTP
Este artigo vai ajudá-lo a garantir que a documentação da sua API fique de acordo com a implementação, utilizando duas ferramentas: API Blueprint and Dredd.

Se você tiver documentação para qualquer tipo de API baseada em HTTP, a partir de um micro-serviço até uma API RESTful não-trivial, se ela já existe há mais de uma semana, então ela possui alguns erros. Documentação degrada ao longo do tempo. Este artigo tem como objetivo ajudá-lo a garantir que a documentação da sua API fique totalmente de acordo com a implementação, utilizando duas ferramentas: API Blueprint and Dredd.
Se você não estiver familiarizado com API Blueprint, talvez você entenda de Apiary. API Blueprint é o formato baseado em Markdown usado por Apiary para criar sua documentação API – juntamente com outros recursos. Dredd é uma ferramenta que vai verificar se existem discrepâncias entre a documentação e a implementação real.
Documentação de erros da APIOs erros de documentação podem ser um novo campo adicionado ou removido da solicitação da API ou da resposta, mas que não refletiu na documentação. Utilizar serializadores como Fractal (PHP), Active Model Serializers (Rails) or Marshmallow (Python) pode ajudá-lo a perceber a mudança nos campos, mas há muitas outras áreas em que pensar. Talvez uma nova query string que não tenha sido listada foi adicionada, ou um novo link estilo JSON-API (relacionamento) que não estava disponível antes está sendo apresentado. E quanto aos cabeçalhos de resposta? Muitas coisas podem mudar.
Para certificar-se de que a documentação da API está 100% correspondente à realização no Ride e evitar uma série de Colombianos irritados chutando a minha bunda na próxima vez que estiverem em NYC em uma viagem de formação de equipe, eu gastei muito tempo na implementação de Dredd.
Testando com DreddMinha explicação anterior de Dredd pode parecer um pouco de magia. Para mim, em primeiro lugar, é exatamente assim que pareceu, mas na verdade ela é muito simples. O Dredd é apenas um aplicativo CLI em NodeJS que analisa cada solicitação e resposta documentada em seu arquivo API Blueprint e o trata como um teste de integração. O arquivo API Blueprint é colocado no repositório git por Apiary mexendo com as configurações, o que significa que ele pode ser atualizado em pull requests junto com o código que está sendo alterado, o que torna a integração CI muito mais fácil.
O Dredd vai dar uma olhada nos headers, no código de status, formato de resposta e o no corpo exato que voltou, e te informar se existem diferenças em qualquer dessas áreas. Uma mensagem de erro será mostrada, ou seja, você pode fazer debug de um aplicativo localmente ou fazer justiça rápida e brutalmente no build da sua integração contínua.
Essa configuração levou, para mim, cerca de três semanas, mas temos uma API incrivelmente não-trivial em Ride. Existem funções de usuário complexas, estamos em uma versão pré-1.0, o que significa que havia um monte de erros para corrigir e que estão em fase de desenvolvimento rápido, o que também significa que eu estava programando contra as metas estabelecidas.
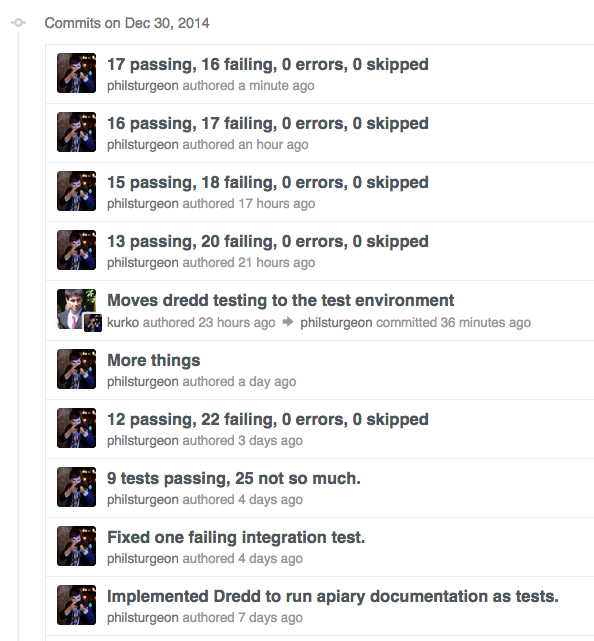
Você pode fazer isso muito mais rápido.
Primeiro, leia Como testar API REST com API Blueprint e Dredd.
Em seguida, eu vou descrever tudo o que eu tinha que considerar e implementar para fazer o trabalho que não está listado lá.
Passo 1: Um script útil em execução
No artigo Apiary, eles têm um arquivo de exemplos de scripts/test:
#!/bin/sh ./node_modules/coffee-script/bin/coffee app.coffee & sleep 5 PID=$! dredd apiary.apib http://localhost:3000/ RESULT=$? kill -9 $PID exit $RESULT
Eu ajustei isso e fiz um bin/run_dredd para se encaixar com os outros executáveis Rails:
#!/bin/sh RAILS_ENV=test bundle exec rake db:reset RAILS_ENV=test bundle exec rake db:fixtures:load RAILS_ENV=test bundle exec rake db:seed RAILS_ENV=test bundle exec rails server -p 3001 & sleep 5 PID=$! dredd apiary.apib http://localhost:3001/ --sorted RESULT=$? kill -9 $PID exit $RESULT
Isso ajudou o Dredd a se instalar com um banco de dados útil, executar um servidor no ambiente de teste, examinar o arquivo apiary.apib e depois matar o seu processo. Um script muito útil.
Passo 2: Dados de teste
Eu escrevi sobre semear um banco de dados em PHP/Laravel e há algumas novas ferramentas novas como Factory Muffin para tornar isso realmente fácil. Independentemente do idioma ou framework, você propagar seu banco de dados para outros testes de integração provavelmente vai funcionar razoavelmente bem como um começo.
Em Ride, como você pode ver acima, já usávamos fixtures de Rails para testes, então eu tenho um longo caminho fora desse. Acabei escrevendo um db:seed personalizado lógico que tornaria os usuários personalizados, tokens OAuth personalizado e os dados básicos relacionados para serem utilizados exclusivamente por Dredd.
Passo 3: Executando usuários diferentes
Quando comecei com o Dredd, eu estava tentando enviá-lo no mesmo token de acesso para tudo usando dredd apiary.apib –header FOO-TOKEN, esquecendo que vários endpoints esperam que os tokens pertençam a usuários, ou a um dos poucos clientes OAuth diferentes que representam os serviços internos.
Nossa API reclamaria que o token não era para um usuário, ou não era para esse serviço específico.
Para fazer este trabalho, eu adicionei isto:
## Credit Card collection [/credit_cards]
### Create a Credit Card [POST]
+ Request (application/json; charset=utf-8)
+ Headers
Authorization: Bearer passenger_access_token
Temos também driver_access_token e foo_service_access_token. Isso pode ser um pouco enganoso, já que parece que estamos dizendo que só os usuários em um endpoitn podem permitir usuários e serviços, mas isso pode ser explicado para os humanos na descrição.
Passo 4: Dados com vazamento
Alguns frameworks de teste de integração vão deixar que você insira fixtures no banco de dados antes de cada teste, em seguida que retorne o banco de dados ao seu estado anterior via transações ou o que garanta um estado novo para cada teste. O Dredd não vai tornar a sua vida tão fácil. Ele continuará tendo efeitos indiretos em outros endpoints na ordem em que ele é executado.
Usar a opção dredd–sorted irá, muito provavelmente, reduzir o número de recursos que tentam apagar o conteúdo antes de lê-lo. Os testes serão executados nesta ordem: CONNECT, OPTIONS, POST, GET, HEAD, PUT, PATCH, DELETE, TRACE. Isso provavelmente não é uma varinha mágica, mas reduziu meus erros em cerca de 30%.
Para combater os outros 70%, eu experimentei escrever alguns hooks para Dredd, que são uma maneira que você pode usar CoffeeScript – UCK – para executar NodeJS script – UCK – antes e depois de vários testes. Eu encontrei alguns exemplos para executar o código antes de cada teste, então perguntei se eu poderia conectar um db:reset e um db:seed antes de cada teste Dredd.
Eu sabia que, se funcionasse, isso seria lento, mas acabou executando os processos filhos de forma assíncrona, ou seja, as seeds não terminariam antes que ele tentasse executar o teste. Depois de algumas horas brincando, eu desisti dessa abordagem, e passei a focar em compartimentalizar os usuários para que as suas ações não tivessem efeito um sobre o outro.
Seguindo a abordagem da passo 3, eu fiz apenas um billy_no_mates_access_token que não tinha usuários combinados, o que significa que eu poderia adicionar e alterar os endereços sem excluir quaisquer outros dados.
Passo 5: Integração Contínua
CircleCI ficava perfeitamente feliz ao executar Dredd com o mínimo possível:
dependencies:
post:
- npm install -g dredd
test:
override:
- bundle exec rake test
- bundle exec ./bin/run_dredd
Eu tive que substituir o comando padrão para permitir vários comandos e, obviamente, dredd tinha que ser instalado via npm, mas, depois disso, ele simplesmente usou o mesmo ./bin/run_dredd que eu estava usando localmente.
Extras: Erros de sintaxe
Erros de sintaxe JSON em exemplos, erros de sintaxe Markdown e outros problemas podem realmente atrapalhar você, e Dredd não é sempre o cara certo para denunciá-los. Existe outra ferramenta chamada Snowcrash, que você, uma vez instalada, pode usar diretamente. Se alguma coisa ficar estranha em seus testes, tente o seguinte comando:
$ snowcrash apiary.apib
Isso dá um grande feedback sobre todos os tipos de potenciais asneiras em sua documentação, o que de outra forma poderia não serem reportadas.
LimitaçõesSe você não tem testes de integração, então isso pode ser um bom começo, mas não deve ser considerado sua suíte de testes completa. Existem algumas razões, mas, em parte, elas se resumem a API Blueprint; é ótimo, mas tem limitações.
Por exemplo, você só pode ter um pedido para cada combinação “URL” + “HTTP Method”. Isso foi doloroso no passado, quando eu queria documentar várias solicitações POST /oauth/tokens mostrando as várias entradas e saídas para diferentes tipos de permissões OAuth, mas a API Blueprint não me deixava.
Além disso, documentar vários erros pode ser complicado. Você só pode ter um exemplo de erro de resposta por código de status HTTP. Por exemplo, você pode ter apenas uma resposta 422 para todos os erros de validação naquele endpoint.
Isso torna o Dredd terrível para testes de integração adequados, e isso é bom, pois não é para isso que o Dredd foi feito. Dredd está testando sua documentação, é preciso ao usar a API, não é para testar a sua API. Isso é só um efeito colateral útil. Dredd pegou erros reais que nossos testes unitários e de integração não captaram, mas, novamente, você não pode usar só o Dredd. Você precisa de um conjunto de testes real também.
ResumoFazer a configuração do Dredd pode ser um trabalho bastante difícil, dependendo do tamanho de sua API HTTP, mas vale muito a pena. Isso me ajudou a evitar um chute dos clientes da API uma ou duas vezes, e, sem dúvida, vai ajudar mais no futuro. Dito isto, eu preferia ter que passar três semanas trabalhando em características em vez de tentar fazer um crowbar disso em nosso fluxo de trabalho.
Espero que você consiga fazê-lo um pouco mais rápido com este conselho.
***
Phil Sturgeon faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://philsturgeon.uk/api/2015/01/28/dredd-api-testing-documentation/
Programa em PHP desde os 12 anos. Gosta de explorar novas tecnologias, testar novas metodologias e construir coisas maiores e melhores. Atualmente, trabalha na Ride, uma empresa de transporte solidário.