Como fazer mapeamento de posição social no Twitter
Muitos temos uma conta pessoal ou relacionada ao trabalho no Twitter, mas como saber onde sua conta está posicionada em um contexto social mais amplo?

Muitos de nós temos pelo menos uma conta pessoal ou relacionada ao trabalho no Twitter, mas como saber onde sua conta está posicionada em um contexto social mais amplo? Em particular, como você pode mapear onde a sua conta no Twitter está posicionada em relação a outros usuários do serviço?
Um recente artigo no blog de Catherine Howe, intitulado Birmingham maptastic, descreve um exercício de mapeamento com a intenção de “apoiar uma camada de descoberta para cidadãos NHS”. Várias observações me chamaram a atenção no texto:
A grande maioria [dos participantes] (não contei, mas em torno de 20/24, lembrando de cabeça) escolheu desenhar diagramas de suas redes em vez de simplesmente relatar os dados.
Então, as pessoas gostam da ideia de diagramas de rede. Alguém que já construiu um mapa mental vai saber que a forma incentiva você a fazer ligações entre coisas semelhantes, usar o espaço/layout para agrupar e diferenciar as coisas e avançar sobre o que você já tem ao preencher as lacunas.
Nós precisaremos fazer uma pesquisa para obter os endereços de Twitter e outras informações organizacionais que estávamos procurando.
Pesquisas? Contanto que você não queira dados demais do Twitter, a maneira mais fácil de obter informações do microblog é programaticamente…
Não estou certa de que podemos coletar os dados de relacionamento que queríamos, uma vez que poucos participantes até agora têm sido capazes de incluir isso com alguma confiança. Não estou certo do quanto isso representa um problema se estivermos apenas olhando para o mapeamento com o propósito de descobrir.
Então, o que está afetando a confiança? A falta de clareza sobre quais informações coletamos, como coletá-las, como afirmar com confiança as relações que existem ou talvez em que categorias as contas pertencem?
Precisamos nos esforçar para incluir os indivíduos que têm muitos perfis. Muitas das pessoas com quem falamos têm múltiplos papéis dentro do que será o sistema NHS de cidadãos. Carreiras e usuários de serviços também estão muitas vezes altamente ligados em rede dentro do sistema, e acho que isso precisa ser capturado no exercício de mapeamento de forma mais explícita. Estou pensando em fazer isso ao pedir que essas pessoas desenhem diversos mapas para cada um dos seus contextos, mas não estou certa de que isso reflete como as pessoas veem a si mesmas – elas são apenas “eu”. Esse é um aspecto importante para a compreensão do fluxo dentro do espaço de descobrimento no futuro – quanto de informação/conexão é passada institucionalmente e quanto é resultado de canais informais ou, pelo menos, pessoais. Isso é, talvez, algo a se considerar no que diz respeito à forma como pensamos sobre o gerenciamento de identidade e a distinção entre as pessoas que atuam institucionalmente e as pessoas que atuam como indivíduos.
As pessoas podem ter diferentes perfis, mas estes estão vinculados a uma identidade ou a muitas identidades? Se for uma única identidade, podemos ser capazes de identificar os diferentes perfis em virtude de diferentes redes que existem entre os membros da própria rede do indivíduo-alvo. Por exemplo, muitas das pessoas que eu conheço que trabalham com dados se conhecem, e todos os membros da minha família se conhecem. Mas há poucas conexões que não sejam eu, juntando essas redes. Se houver várias identidades, pode fazer sentido gerar mapas separados e, então, talvez numa fase posterior, procurar sobreposições.
Seja específico. Eu preciso ter certeza de que somos disciplinados na coleta de dados para distinguir entre instâncias específicas e genéricas de algo como Healthwatch. Nos mapas de rede, as pessoas estão simplesmente colocando ‘Healthwatch’ e não dizem qual.
Gerar um mapa do próprio “Healthwatch” pode ser um bom primeiro passo: como a própria organização Healthwatch se parece, e ela se divide em várias áreas distintas?
Em outro artigo recente, “#NHSSM #HWBlearn can you help shape some key social media guidelines?”, Dan Slee, disse:
Você pode não saber disso, mas há um ramo do governo local que tem grande força nas decisões que vão afetar a forma como sua família é tratada quando ela não está bem.
Eles são chamados de conselhos de saúde e bem-estar e se reúnem na Câmara Municipal, que abrange a intersecção entre GPs, autoridades locais e grupos de pacientes.
Eles também têm força para decidir sobre onde gastar £3,80 bilhões – uma soma invejável para a conta de qualquer um. […]
Muitos deles fazem um ótimo trabalho, mas há um sentimento crescente de que eles poderiam fazer mais ao usar mídia social para realmente se envolver com as comunidades que servem. Então, nós estamos ajudando a ver como algumas diretrizes de mídia social podem ajudar.
E talvez um exercício de mapeamento ou dois?
Uma das maneiras mais comuns de mapeamento de uma rede social em torno de um indivíduo é olhar para a forma como os seguidores dele indivíduo seguem uns aos outros. Essa abordagem é usada para gerar coisas como o InMap do LinkedIn. Um problema com esse tipo de geração de mapas é que para gerar um mapa abrangente precisamos pegar os dados do amigo/seguidor para toda a rede do amigo/seguidor. A API do Twitter permite que você procure informações do amigo/seguidor para 15 pessoas a cada 15 minutos, portanto mapear uma grande rede pode levar algum tempo! Como alternativa, pode-se obter uma lista de todos os seguidores de um indivíduo e, em seguida, ver como uma amostra desses seguidores se conecta com o resto para ver se podemos identificar quaisquer grupos particulares.
Outra maneira é mapear a conversa entre pessoas no Twitter que estão discutindo um tópico específico usando uma hashtag específica. Um grande exemplo é o Explorador de TAGS de Martin Hawksey, que pode ser usado para arquivar e visualizar uma conversa do Twitter através de hashtags. Um dos problemas com essa abordagem é que nós só temos olhos de pessoas que estão ativamente engajadas em uma conversa por meio da hashtag que estamos monitorando no momento de uma amostragem dos dados de conversa no Twitter.
Para os usuários do Excel, o NodeXL é uma ferramenta de análise de rede social que suporta a importação e a análise de dados de rede do Twitter. Eu não tenho qualquer experiência em usar essa ferramenta, então eu realmente não posso comentar nada!
No resto deste artigo, vou descrever uma outra técnica de mapeamento – posicionamento social emergente (ESP, emerging social positioning) – que tenta identificar os amigos comuns dos seguidores de um indivíduo em particular.
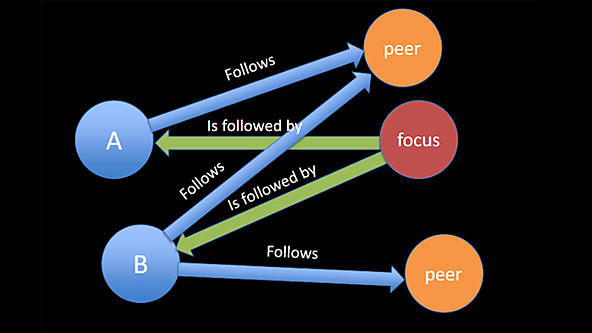
A ideia é simples: as pessoas me seguem, porque elas estão interessadas no que eu faço ou digo (espera-se). Essas mesmas pessoas também seguem outras pessoas ou coisas que lhes interessam. Se muitos dos meus seguidores seguem a mesma pessoa ou coisa, muitos dos meus seguidores estão interessados naquela coisa. Então, talvez eu também esteja. Ou talvez eu deveria estar. Ou talvez essas coisas sejam meus concorrentes? Ou talvez um grupo de meus seguidores revelam algo sobre mim que eu estou tentando manter escondido ou não estou divulgando publicamente na medida em que me associar a uma coisa que eles revelam, em virtude de seguir outros significantes dessa coisa em massa? (Para mais discussão, ver o College of Journalism BBC sobre como mapear sua rede social)
Aqui está um exemplo de um mapa como esse mostrando as pessoas geralmente seguidas por uma amostra de 119 seguidores da conta @SchoolOfData no Twitter.
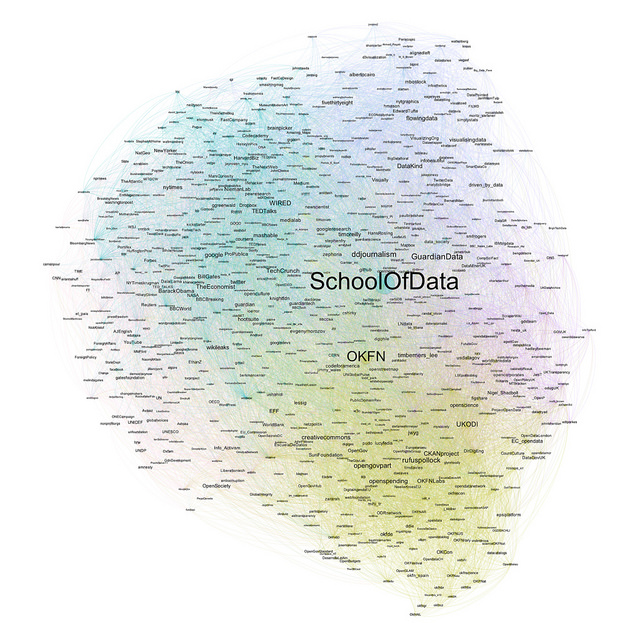 Da minha leitura rápida do mapa, podemos ver um grupo de contas relacionadas a OKF e, mais embaixo, as contas relativas a ONGs em torno da posição 7 horas. Mudando para 10 horas mais ou menos, temos uma região de publicações web e sites de notícias de tecnologia; apenas após a posição de 12 horas, temos um grupo de pessoas associadas com a visualização de dados e, em seguida, um conjunto de contas mais relacionado ao jornalismo de dados; finalmente, na posição de 3 horas, há um aglomerado de interesse em dados abertos do Reino Unido. Dependendo de sua familiaridade com os nomes das contas de Twitter, você pode ter uma leitura um pouco diferente.
Da minha leitura rápida do mapa, podemos ver um grupo de contas relacionadas a OKF e, mais embaixo, as contas relativas a ONGs em torno da posição 7 horas. Mudando para 10 horas mais ou menos, temos uma região de publicações web e sites de notícias de tecnologia; apenas após a posição de 12 horas, temos um grupo de pessoas associadas com a visualização de dados e, em seguida, um conjunto de contas mais relacionado ao jornalismo de dados; finalmente, na posição de 3 horas, há um aglomerado de interesse em dados abertos do Reino Unido. Dependendo de sua familiaridade com os nomes das contas de Twitter, você pode ter uma leitura um pouco diferente.
Note que também podemos tentar rotular as regiões do mapa automaticamente, por exemplo, pegando as bios do Twitter de cada conta em um grupo de cor e executando algumas ferramentas de análise de texto simples sobre eles para escolher palavras comuns ou tópicos que poderíamos usar como rótulos de área.
Então, como ele foi gerado? E você pode gerar um para sua própria conta no Twitter?
O mapa em si foi gerado utilizando um programa de código aberto gratuito multiplataforma para visualização de rede chamado Gephi. Os dados utilizados para gerar o mapa foram conseguidos a partir da API do Twitter usando algo chamado de IPython notebook. Um IPython notebook é um aplicativo interativo, baseado no navegador que permite que você escreva programas em Python interativos ou construa aplicativos “bare bones” que outros possam usar sem a necessidade de aprender qualquer programação.
Instalar o IPython e algumas das bibliotecas de programação que estamos usando pode ser, por vezes, um pouco difícil. Então, a maneira que eu executo o IPython notebook é sobre o que é chamado de máquina virtual. Você pode pensar nisso como um “computador dentro de outro computador”. Essencialmente, a ideia é instalar um outro computador que contém tudo o que precisamos em um espaço em nosso próprio computador e, em seguida, trabalhar com isso através de uma interface de navegador.
A máquina virtual que eu uso é uma que foi empacotada para apoiar o livro Mining the Social Web, 2ª Edição (O’Reilly, 2013),por Matthew Russell. Você pode descobrir como instalar a máquina virtual em seu próprio computador em Mining the Social Web – Virtual Machine Experience.
Tendo instalado a máquina, o script que eu uso para colher os dados para o mapeamento ESP pode ser encontrado aqui: Emergent Social Positioning IPython Notebook (preview). O script é inspirado por scripts desenvolvidos por Matthew Russell, mas com algumas variações, em particular na forma como os dados são armazenados no banco de dados da máquina virtual.
Faça o download do script para o diretório ipynb no diretório Mining the Social Web. Para executar o script, clique nas células de código na ordem e aperte o botão de “play” para executar o código. A célula de código final contém uma linha que permite que você digite sua própria conta do Twitter como alvo. Dê um duplo clique na célula para editá-la. Quando o script for executado, um arquivo de dados de rede será escrito no diretório ipynb como um arquivo .gexf.
Esse arquivo pode ser importado diretamente para o Gephi, podendo visualizar a rede. Para um tutorial sobre como visualizar redes com Gephi, consulte o artigo Firsts Steps in Identifying Climate Change Denial Networks on Twitter.
Embora o processo possa parecer bastante complicado – instalar a máquina virtual, fazê-la funcionar, conseguir as credenciais da API do Twitter, usar o notebook, usar Gephi – se você trabalhar com as etapas metodicamente, deve ser capaz de chegar lá!
***
Artigo escrito por Tony Hirst, que trabalha para a Escola de Dados moldando materiais, organizando o blog e ministrando workshops. Publicado originalmente no portal Escola de Dados: http://schoolofdata.org/2014/02/14/mapping-social-positioning-on-twitter/trabalha para capacitar organizações da sociedade civil, jornalistas e cidadãos com as habilidades que eles precisam para usar dados de forma eficaz em seus esforços para criar sociedades mais justas e eficazes.