Canonical element e Conteúdo duplicado

Canonical element é um novo recurso disponibilizado pelos mecanismos de busca, que tem como objetivo “resolver” um problema incômodo: o conteúdo duplicado. Vou comentar alguns pontos deste novo recurso, mas antes acredito que seja conveniente fazer algumas definições rápidas para aqueles que ainda não conhecem bem o que é conteúdo duplicado. Sendo assim, vou:
- Falar sobre os problemas causados pelo conteúdo duplicado;
- Definir o que é conteúdo duplicado;
- Mostrar os problemas que isso pode causar;
- Comentar algumas soluções conhecidas; e
- Falar sobre o recurso recentemente lançado o Canonical element.
Conteúdo Duplicado
Pode-se entender conteúdo duplicado como páginas com URLs distintas que possuem um mesmo conteúdo. Veja um trecho, por exemplo, de uma definição do Centro de Ajuda ao Webmaster do Google, sobre conteúdo duplicado:
“Duplicar conteúdo, geralmente refere-se a blocos substanciais de conteúdo dentro ou através de domínios que complementam outro conteúdo ou são notadamente similares. Geralmente, não é uma prática enganosa, a princípio.”
Fonte: http://www.google.com/support/webmasters/
A ajuda do Google ainda exemplifica que o conteúdo duplicado não malicioso pode ocorrer em alguns casos, como:
- Fóruns de discussão que podem gerar páginas tanto regulares quanto reduzidas, em dispositivos móveis;
- Produtos exibidos ou relacionados por link via URLs distintos; e
- Versões de sites apenas para impressão.
Um outro exemplo onde pode ocorrer conteúdo duplicado é em algumas ferramentas de blog. Por se tratar de um mecanismo que possui diversidade de navegação e categorização de artigos arquivados por data, categoria, hora, entre outros, o “spider” pode encontrar duas páginas com endereços diferentes, mas, com o mesmo conteúdo.
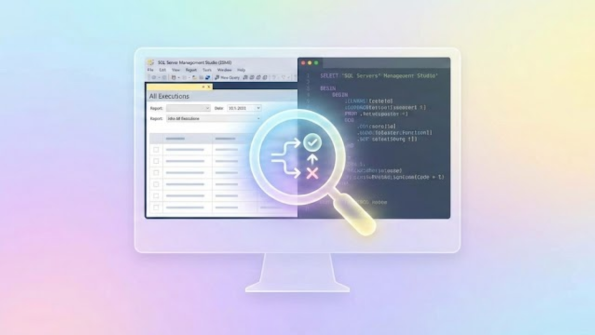
Em outros tipos de websites isso também pode ocorrer, mas não entraremos a fundo nessa questão. O importante neste caso é que o leitor entenda que se trata de duas páginas iguais com URLs diferentes. Podemos definir conteúdo nesse caso como o conteúdo textual, o texto propriamente dito, o título da página e a meta tag descrição, por exemplo. O Google Webmaster Tools oferece um relatório onde é possível identificar se há conteúdo duplicado na descrição e nos títulos do seu site:

Jerry Ledford (2008) comenta que a distribuição de conteúdo pela internet também pode causar a duplicação de conteúdo. Em alguns casos porque alguns sites copiam trechos de conteúdos de outros, em outros casos porque uma chamada para um artigo, por exemplo, pode aparecer várias vezes em um ou mais websites.
Problemas causados pelo Conteúdo Duplicado
Penso que o maior inconveniente causado por esse problema é a queda no posicionamento do seu site, nos resultados orgânicos dos mecanismos de busca. Isso pode acontecer já que o robô do mecanismo de busca encontrará dois conteúdos iguais em URLs diferentes, entendendo isso como conteúdo duplicado ou mesmo como spam, uma técnica ilegal para repetição de palavras-chave em um mesmo domínio, com o objetivo de obter um melhor posicionamento nos resultados de busca.
Soluções conhecidas
Em sites com páginas feitas exclusivamente para impressão esse tipo de problema também pode ocorrer. Falo daqueles sites, onde em alguma notícia, por exemplo, você encontra um link com uma versão da página para a impressão. Trata-se de duas páginas, uma com a notícia dentro da estrutura do site, e outra com uma versão mais “clean” para a impressão. Se não houver nenhuma especificação para o robô, certamente isso poderá ser considerado conteúdo duplicado passível até de uma punição.
Nesse caso, imagine que todas as páginas para impressão fiquem em uma pasta “/ver-impressao”. Sendo assim, basta bloquear a indexação e consideração dessa pasta pelo robots.txt, onde haverá uma regra:
User-agent: *Disallow: /ver-impressaoUma alternativa é o uso da meta tag “noindex”. Para isso basta colocar dentro do <head>:
<head>...<meta name="robots" content="noindex"></head>Nesse último caso o robô só não irá indexar as páginas que possuírem esta meta informação.
Canonical Element
Este recurso pode e certamente irá ajudar muitos sites que sofrem com esse tipo de problema. A configuração básica trata de um colocar a tag no conteúdo original e na página onde o conteúdo é duplicado. Para um e-commerce, por exemplo, com URLs derivadas de parâmetros, a solução seria na página direcionada aos detalhes de algum produto, a implementação do canonical element. Vamos utilizar para este exemplo, uma loja de instrumentos musicais.
Página para marca de guitarras Gibson:
http://www.instrumentosmusicais.com/guitarras.php?marca=gibson
Vamos dizer que nesta página é possível escolher a cor da Guitarra, e que apesar da nova URL a página é a mesma, mudando somente a cor do instrumento:
http://www.instrumentosmusicais.com/guitarras.php?marca=gibson$var=vermelha
Nesse caso o robô pode considerar que essas duas páginas possuem o mesmo conteúdo. Sendo assim, basta “canonizar” uma das URLs, usando o canonical element dentro do cabeçalho das duas páginas:
<head>......<link rel="canonical" href="http://www.instrumentosmusicais.com/guitarras.php?marca=gibson"/></head>Dessa forma o robô irá entender que se trata apenas de uma variação do conteúdo e que pode indexar só uma das páginas.
Em minha opinião, apesar de um recurso muito útil o canonical element não pode ainda resolver todos os problemas de conteúdo duplicado, mas certamente este avanço já mostra que os mecanismos de busca correm atrás de cada vez mais soluções para problemas como esse, a fim de qualificar ainda mais seus resultados.
Vejam o vídeo do Matt Cutts apresentando e explicado o canonical element: http://google.com/support/webmasters/bin/answer.py?answer=139394
Até a próxima!
É head da Vitrio no Rio Grande do Sul. Autor do livro "SEO, Otimização de Sites: aplicando técnicas de otimização de sites com uma abordagem prática" (Brasport, 2010). No Twitter, é @erickformaggio.