

Olá, pessoal! Neste episódio do DatabaseCast, Mauro Pichiliani (Twitter | Blog), Wagner Crivelini (@wcrivelini) e o convidado Ricardo Rezende (@ricarezende) separam os dados como se eles estivesse dentro de um pacote de M&Ms. Neste episódio você vai aprender quais são os tipos de particionamento no Oracle, SQL Server, MySQL, PostgreSQL, MongoDB e Cassandra, discutir se o Hadoop é ou não um banco de dados, mandar um alô para o pessoal do Suriname e da Suécia e aprender a chamar certas soluções de gambiware.
 Veja também a caneca Datas SQL com a sintaxe para manipulação de datas no Oracle, SQL Server, MySQL e PostgreSQL.
Veja também a caneca Datas SQL com a sintaxe para manipulação de datas no Oracle, SQL Server, MySQL e PostgreSQL.

Não deixe de nos incentivar digitando o seu comentário no final deste artigo, mandando um e-mail para databasecast@gmail.com, seguindo o nosso twitter @databasecast, vendo informações de bastidores e as músicas do programa no nosso Tumblr e curtindo a nossa página no Facebook e no Google+.

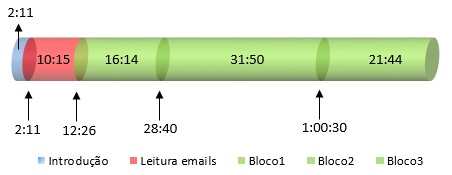
Veja no gráfico abaixo a duração e os tempos aproximados de início e fim de cada bloco:
Veja na tag cloud abaixo a contagem das palavras mais usadas nos e-mails, comentários e tweets do episódio anterior:

Livro Conversando sobre Banco de dados do Mauro Pichiliani (Impresso e PDF, EPUB e MOBI)
Você pode comprar a camiseta com estampa fractal Fluxo Matrix e Sonho Fractal diretamente neste link. Veja também:
Links do episódio:

De 0 a 10, o quanto você recomendaria este artigo para um amigo?