Conheça o conceito CQRS
Vamos falar do conceito CQRS (Command and Query Responsibility Segregation) em português seria Segregação por Responsabilidade de Comando e Consulta.


Neste artigo irei falar sobre o conceito CQRS (Command and Query Responsibility Segregation) em português seria Segregação por Responsabilidade de Comando e Consulta. Iremos examinar como a separação de funções no sistema pode levar a uma arquitetura muito mais eficiente. Vamos também olhar diferentes propriedades arquitetônicas existentes nos sistemas em que o CQRS foi aplicado.
OrigemO CQRS originou-se do CQS (Command–query separation), definida como:
Cada método deve ser um comando que executa uma ação ou uma consulta que retorna dados para o chamador, mas não ambos. Em outras palavras, Fazer uma pergunta não deve alterar a resposta .
CQRS foi originalmente considerado apenas como uma extensão de CQS e durante muito tempo foi discutido como o mesmo assunto. Depois de muita confusão entre os dois conceitos, foram separados.
CQRS usa a mesma definição de CQS que Meyer usou e mantém o ponto de vista de que eles deveriam ser puros. A diferença fundamental é que, no CQRS, os objetos são divididos em dois objetos, um contendo os Comandos (Commander), e um contendo as Consultas (Reader).
O padrão, embora não seja muito interessante para todos os casos, torna-se extremamente interessante quando se aplica o DDD.
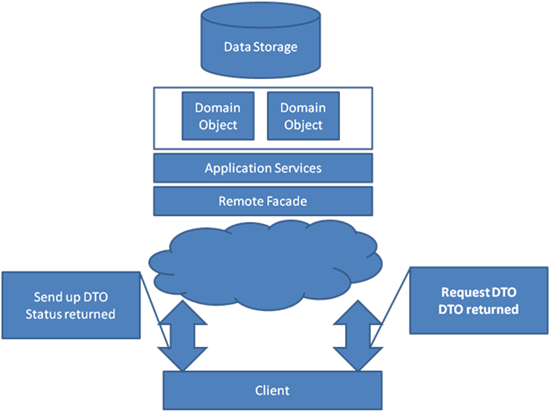
A figura 1 contém a arquitetura convencional onde a classe de serviço lida com escrita e leitura. O domínio também está sendo usado para escrita e leitura. Aplicando o CQRS a essa arquitetura, embora seja simples de aplicar, mudará drasticamente como a arquitetura funciona. A seguir temos um serviço de exemplo:
A seguir temos um serviço de exemplo
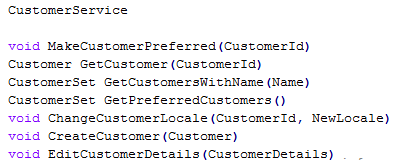
A aplicação do CQRS no CustomerService resultaria em dois serviços, conforme mostrado na Imagem 2.
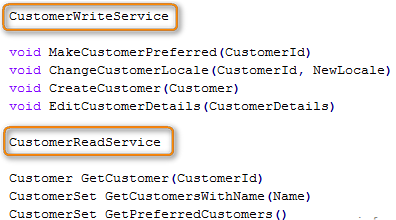
Embora seja um processo relativamente simples, isso resolverá muitos dos problemas que existiam na arquitetura convencional. A classe de serviço foi dividida em duas , um classe de leitura(reader) e uma classe de escrita(commander).
Essa separação impõe a noção de que o Commander e Reader têm necessidades muito diferentes. As propriedades da arquitetura associadas aos casos de uso em cada tipo tendem a ser bem diferentes. Apenas para citar alguns:
Consistência
Commander: É muito mais fácil processar transações com dados consistentes do que lidar com todos os casos de uso que uma consistência eventual pode precisar.
Reader: a maioria dos sistemas pode ser consistente no lado da consulta.
Armazenamento de dados
Commander: O commander, sendo um processador de transação em uma estrutura relacional, desejaria armazenar dados de uma maneira normalizada.
Reader: O reader precisa mais de dados desnormalizados para minimizar o número de joins necessários para obter um determinado conjunto de dados.
Escalabilidade
Commander: Na maioria dos sistemas, especialmente sistemas da Web, o commander geralmente processa um número muito pequeno de transações como uma porcentagem do todo. Escalabilidade, portanto, nem sempre é importante.
Reader: Na maioria dos sistemas, especialmente sistemas da Web, o reader geralmente processa um número muito grande de transações como uma porcentagem do todo. A escalabilidade é mais frequentemente necessária para o reader (leitura).
Entendendo o ReaderComo afirmado, o reader conterá apenas os métodos para obter dados. Da arquitetura original, esses seriam todos os métodos que retornam DTOs que o cliente consome para mostrar na tela.
Na arquitetura original, a construção de DTOs era controlada pelos objetos de domínio. Este processo pode levar a aumentar muito trabalho do time de desenvolvimento, pois os DTOs são um modelo diferente do domínio e, como tal, requerem um mapeamento.
Os DTOs são construídos para representar às telas do cliente afim de evitar muitas consultas. Em casos com muitos clientes, talvez seja melhor criar um modelo canônico usado por todos os clientes. Em ambos os casos, o modelo de DTO é muito diferente do modelo de domínio que foi construído para representar e processar transações.
Alguns dos problemas podem ser encontrados em muitos domínios.
- Um grande número de métodos de leitura em repositórios frequentemente também inclui informações de paginação ou ordenação.
- Getters expondo o estado interno dos objetos de domínio para criar DTOs.
- O carregamento de vários aggregates para criar um DTO faz com que as consultas mais pesadas sejam feitas no modelo de dados. Alternativamente, os limites aggregates podem ser confundidos por causa das operações de construção do DTO
O maior problema é que a otimização de consultas é extremamente difícil de ser feita. Como as consultas estão operando em um modelo de objeto e sendo traduzidas para um modelo de dados, provavelmente por um ORM, pode ser difícil otimizar essas consultas. Um desenvolvedor precisa ter um conhecimento profundo do ORM e do banco de dados.
Após aplicar o CQRS, existe um limite natural. Caminhos separados foram explicitados, agora faria mais sentido não usar o domínio para projetar os DTOs. Em vez disso, é possível introduzir uma nova maneira de projetar DTOs.
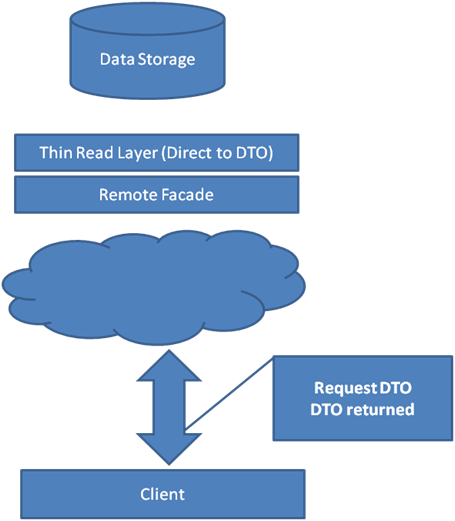
O domínio foi ignorado. Existe agora um novo conceito chamado “Thin read layer” ou traduzido diretamente : “Camada de leitura fina”. Essa camada lê diretamente do banco de dados para os DTOs. Há muitas maneiras de fazer isso com ADO.NET ou utilizar ORM;Micro ORM. A escolha certa para uma equipe depende de com o que ela se sente mais confortável. Provavelmente, a melhor solução é algo no meio termo, pois muito do que um ORM fornece não é necessário e muito tempo poder ser perdido criando mapeamento de dados.
A Thin Read Layer não precisa ser isolada do banco de dados, não é necessariamente uma coisa ruim estar vinculada a uma fonte de dados na camada de leitura. Também não é necessariamente ruim usar procedures para leitura (desde que não tenha regras de negocio), novamente depende da equipe e dos requisitos não funcionais do sistema.
A Thin Read Layer não é um código complexo, embora possa ser tedioso manter. Um benefício da camada de leitura separada é que ela não sofrerá uma incompatibilidade. Ele está conectado diretamente ao modelo de dados, o que torna as consultas muito mais fáceis de otimizar. Os desenvolvedores que trabalham no lado do reader não precisam entender o domínio nem a ferramenta ORM que está sendo usada. No nível mais simples, eles precisariam entender apenas o modelo de dados.
O CommanderNo geral, o commander continua muito parecido com a arquitetura original. A ilustração na Figura 3 deve parecer quase idêntica à Imagem 1. As principais diferenças são que agora temos um contrato descentralizado separando leitura e escrita para realmente fazer sentido o uso do Domain Driven Design e não quebrarmos o nosso domínio.
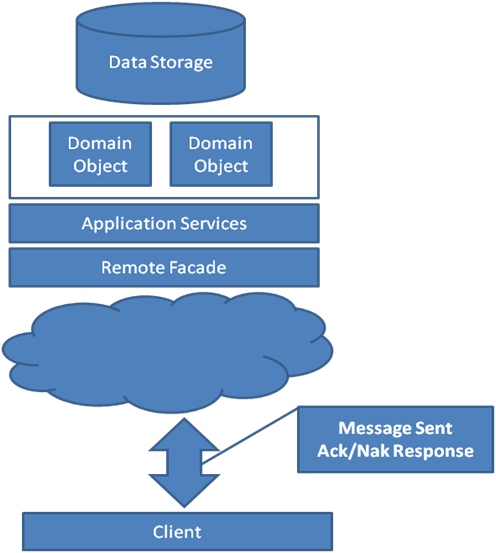
Na “Arquitetura original”, o domínio estava lidando com comandos e consultas, o que causou muitos problemas no próprio domínio. Algumas dessas questões foram:
- Um grande número de métodos de leitura em repositórios frequentemente também inclui informações de paginação ou ordenação.
- Getters expondo o estado interno dos objetos de domínio para criar DTOs.
- O carregamento de vários aggregates para criar um DTO faz com que as consultas mais pesadas sejam feitas no modelo de dados. Alternativamente, os limites aggregates podem ser confundidos por causa das operações de construção do DTO.
Depois que a camada de leitura(reader) tiver sido separada, o domínio se concentrará apenas no commander. Objetos de domínio de repente não têm mais a necessidade de expor o estado interno, os ficam mais simples e métodos GetById, podem ser obtido do Aggregate.
Essa alteração foi feita a um custo menor ou nenhum custo em comparação com a arquitetura original. Em muitos casos, a separação reduzirá os custos de processamento e complexidade, já que a otimização das consultas é mais simples na camada de leitura do que seria se fosse implementada no domínio. A arquitetura também carrega menor sobrecarga ao trabalhar com o domínio à medida que a consulta é separada. No pior dos casos, o custo deve ser igual; Tudo o que realmente tem sido feito é a movimentação de uma responsabilidade, é possível até mesmo que o lado da leitura ainda use o domínio.
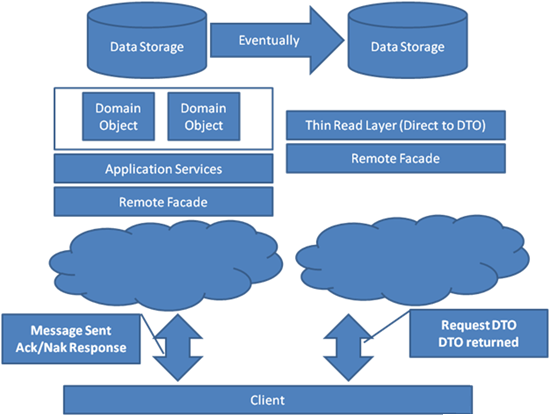
Ao aplicar o CQRS, os conceitos de leituras e gravações foram separados. Isso realmente levanta a questão de se os dois devem existir lendo o mesmo modelo de dados ou talvez possam ser tratados como se fossem dois sistemas integrados. A Figura 5 ilustra esse conceito. Há muitos padrões de integração bem conhecidos entre várias fontes de dados para manter a sincronização de maneira consistente ou eventualmente consistente. As duas fontes de dados distintas permitem que os modelos de dados sejam otimizados para a tarefa em questão.
A escolha do modelo de integração é muito importante, pois uma escolha errada pode levar a custos altos de retrabalho. O modelo mais adequado é a introdução de eventos, os eventos são um padrão de integração bem conhecido e oferecem o melhor mecanismo para a sincronização de dados.
Atua como Gerente de desenvolvimento de sistemas na XP Inc., possui mais de 10 anos de experiência em desenvolvimento de sistemas com foco principal em tecnologias .NET, atualmente escreve artigos de tecnologia para as mídias da XP Inc. em parceria com grandes nomes da comunidade