

Por anos Bazel sempre me pareceu uma ferramenta muito boa e, ao mesmo tempo, por uma soma da sua linguagem própria (starlark) e a estrutura dos arquivos, muito complicada de aprender.
Somente depois de entender o que acontece “atrás das cortinas” e os conceitos da ferramenta é que finalmente pude começar a tirar o melhor dela. Por isso, resolvi criar uma série de posts para compartilhar meu aprendizado.
Se você já teve algum contato com Bazel, vou pedir para que não se preocupe com os arquivos WORKSPACE, BUILD e .bzl por enquanto (se você não teve contato, também não precisa se preocupar). Nesse post, vamos deixar esses arquivos de lado e falar um pouco sobre como o bazel funciona internamente.
Bazel executa seus builds com base em um diagrama de ações (action graph). Cada ação é um nó no diagrama, e cada nó é a execução de um programa, como, por exemplo, javac, gcc, tsc e etc…
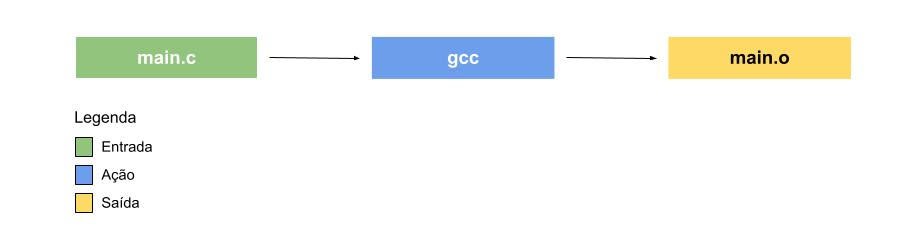
Esse diagrama de ações é o principal conceito que você precisa entender, já que tudo o que fazemos no Bazel é básicamente contruir esse diagrama. Depois, durante o processo de build, o Bazel vai utilizar esse diagrama para percorrer todos os nós e executar todas as ações.
Para entender um pouco melhor o processo todo, vamos falar sobre as 3 fases do Bazel.
- Carregamento (loading phase): Nessa fase, Bazel vai ler e carregar todos os scripts que criamos.
- Análise (analysis phase): Com todos os scripts carregados, ele vai executar os scripts para montar o diagrama de ações em memória.
- Execução (execution phase): Por último, ele vai percorrer todo o diagrama e executar todas as ações para gerar a saída final que queremos.
Depois do diagrama construído, o Bazel irá criar uma pasta de sand-box onde serão executadas as ações. Essa pasta é iniciada vazia, ou seja, para que o Bazel tenha acesso aos arquivos do projeto, precisamos declarar esses arquivos como inputs do diagrama. Somente os arquivos declarados serão copiados para essa pasta e utilizados nas execuções das ações.
Para ficar um pouco mais claro, imagine o seguinte diagrama:
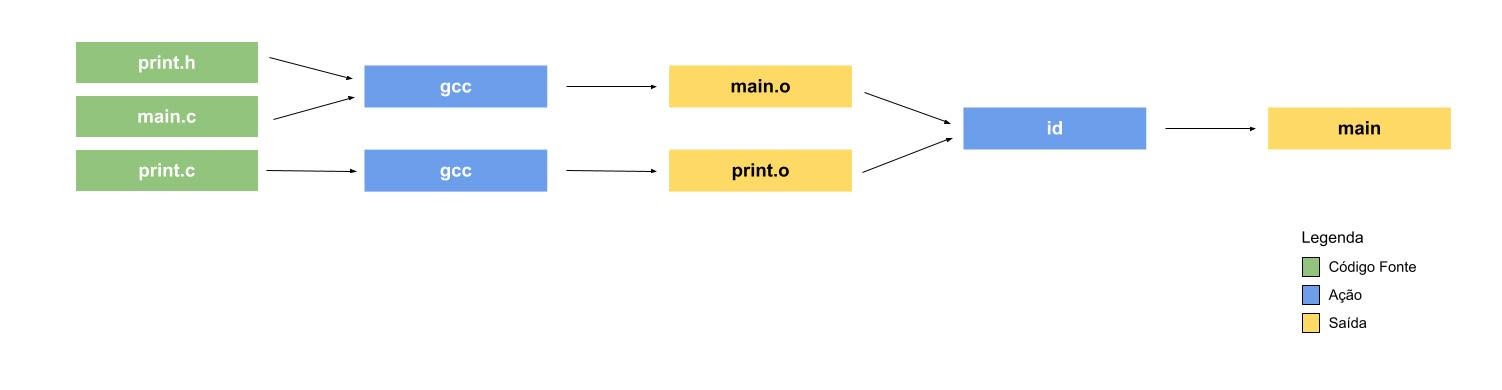
Começamos com nossos arquivos fonte. Nas configurações do Bazel, colocamos esses arquivos como inputs para que sejam transformados em binários, jars, javascript, zip e etc…
Cada ação deve gerar pelo menos uma saída, já que o Bazel não suporta ações que não façam nenhuma alteração no filesystem.
Com o diagrama montado, o Bazel consegue analisá-lo e aplicar otimizações, como por exemplo executar ações em paralelo e pular passos desnecessários, ou seja, passos que podem ser recuperados do cache.
Para controlar o cache, o Bazel gera uma hash de todo arquivo gerado nos passos intermediários. Dessa forma ele consegue executar somente os passos impactados pelos arquivos alterados.
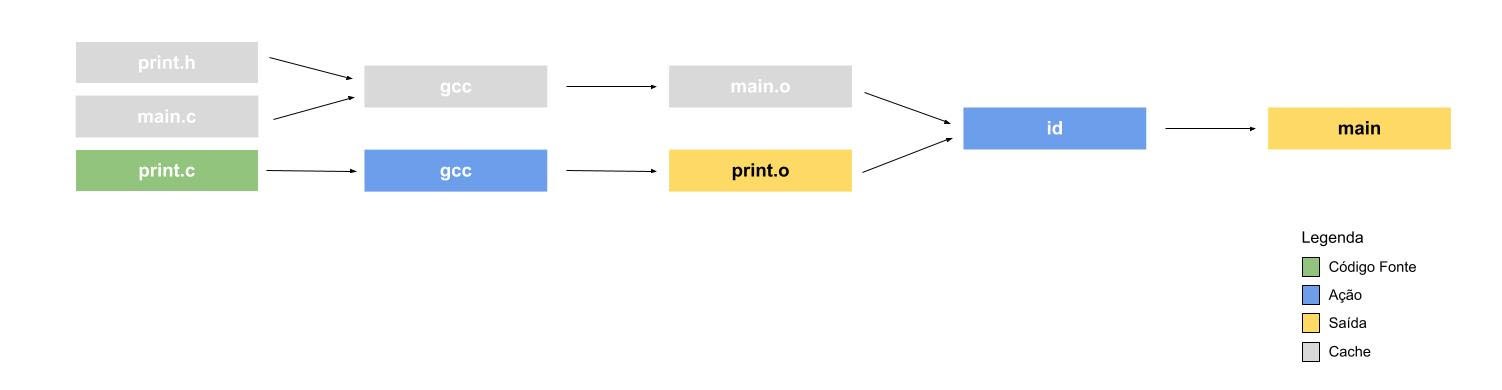
Em resumo, para ter um build feito com Bazel nós precisamos:
- Definir um diagrama de ações, que são basicamente os programas que queremos executar.
- Esses programas devem receber arquivos em sua entrada.
- Esses programas geram uma saída com os arquivos transformados.
- Os arquivos transformados podem ser usados como entrada do próximo programa.
- O Bazel faz cache de cada uma das saídas e gera uma hash para esse cache.
- Após a primeira execução, com essa hash que foi gerada o Bazel consegue definir se precisa executar o passo novamente ou pode recuperar o resultado do cache.
Esse fluxo se repete até que todos os passos tenham sido executados, finalizando assim o build.
Agora que já conhecemos um pouco melhor como Bazel funciona internamente, no próximo post vamos começar falar sobre alguns conceitos dessa ferramenta.
Obrigado por ter lido e até o próximo post.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?