

MongoDB é um banco de dados de código aberto, gratuito, de alta performance, sem esquemas e orientado a documentos lançado em fevereiro de 2009 pela empresa 10gen. Foi escrito na linguagem de programação C++ (o que o torna portável para diferentes sistemas operacionais) e seu desenvolvimento durou quase 2 anos, tendo iniciado em 2007.
Já falei de MongoDB na prática aqui no blog em outras três oportunidades juntamente com a tecnologia Node.js. Confira em:
- Tutorial Node.js + MongoDB com driver nativo
- Tutorial Node.js + MongoDB com ORM
- Tutorial autenticação em Node.js (onde guardo as credenciais no Mongo)
No entanto, em ambas ocasiões, MongoDB foi o coadjuvante e pouco falei de suas características, suas vantagens, desvantagens e como modelar bases reais com ele. Pois bem, esse é o intuito do post de hoje, compartilhar os meus pouco mais de 2 anos (na data que escrevo este post) de experiência com este fantástico banco de dados.
Veremos neste artigo:
A parte inicial e teórica deste artigo pode ser substituída pelo vídeo abaixo, caso prefira. Depois, pode ler apenas a parte 4.
Vamos lá!
#1 – Orientado à Documentos
Por ser orientado a documentos JSON (armazenados em modo binário, apelidado de BSON), muitas aplicações podem modelar informações de modo muito mais natural, pois os dados podem ser aninhados em hierarquias complexas e continuar a ser indexáveis e fáceis de buscar, igual ao que já é feito em JavaScript.
Existem vários bancos NOSQL atualmente no mercado porque existem dezenas de problemas de persistência de dados que o SQL tradicional não resolve. Bancos não-relacionais document-based (que armazenam seus dados em documentos) são os mais comuns e mais proeminentes de todos, sendo o seu maior expoente o banco MongoDB como o gráfico abaixo da pesquisa mais recente de bancos de dados utilizados pela audiência do StackOverflow em 2021 mostra.
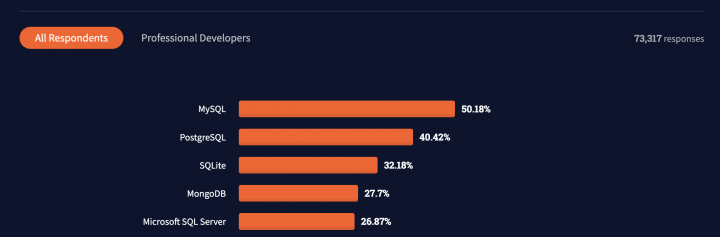
Dentre todos os bancos não relacionais o MongoDB é o mais utilizado com mais de 1/4 de todos os respondentes alegarem utilizar ele em seus projetos, o que é mais do que até mesmo o Oracle, um banco muito mais tradicional.
Basicamente neste tipo de banco (document-based ou document-oriented) temos coleções de documentos, nas quais cada documento é autossuficiente, contém todos os dados que possa precisar, ao invés do conceito de não repetição + chaves estrangeiras do modelo relacional.
A ideia é que você não tenha de fazer JOINs pois eles prejudicam muito a performance em suas queries (são um mal necessário no modelo relacional, infelizmente). Você modela a sua base de forma que a cada query você vai uma vez no banco e com apenas uma chave primária pega tudo que precisa.
Obviamente isto tem um custo: armazenamento em disco. Não é raro bancos MongoDB consumirem muitas vezes mais disco do que suas contrapartes relacionais.
#2 – Quando devo usar MongoDB?
MongoDB foi criada com Big Data em mente. Ele suporta tanto escalonamento horizontal quanto vertical usando replica sets (instâncias espelhadas) e sharding (dados distribuídos), tornando-o uma opção muito interessante para grandes volumes de dados, especialmente os desestruturados.
Dados desestruturados são um problema para a imensa maioria dos bancos de dados relacionais, mas não tanto para o MongoDB. Quando o seu schema é variável, é livre, usar MongoDB vem muito bem a calhar. Os documentos BSON (JSON binário) do Mongo são schemaless e aceitam quase qualquer coisa que você quiser armazenar, sendo um mecanismo de persistência perfeito para uso com tecnologias que trabalham com JSON nativamente, como JavaScript (e consequentemente Node.js).

Cenários altamente recomendados e utilizados atualmente são em catálogos de produtos de e-commerces. Telas de detalhes de produto em ecommerces são extremamente complicadas devido à diversidade de informações aliada às milhares de variações de características entre os produtos que acabam resultando em dezenas de tabelas se aplicado sobre o modelo relacional. Em MongoDB essa problemática é tratada de uma maneira muito mais simples, que explicarei mais adiante.
Além do formato de documentos utilizado pelo MongoDB ser perfeitamente intercambiável com o JSON serializado do JS, MongoDB opera basicamente de maneira assíncrona em suas operações, assim como o próprio Node.js, o que nos permite ter uma persistência extremamente veloz aliado a uma plataforma de programação igualmente rápida.
Embora o uso de Node.js com bancos de dados relacionais não seja incomum, é com os bancos não-relacionais como MongoDB e Redis que ele mostra todo o seu poder de tecnologia para aplicações real-time e volumes absurdos de requisições na casa de 500 mil/s, com as configurações de servidor adequadas.
Além disso, do ponto de vista do desenvolvedor, usar MongoDB permite criar uma stack completa apenas usando JS uma vez que temos JS no lado do cliente, do servidor (com Node) e do banco de dados (com Mongo), pois todas as queries são criadas usando JS também, como você verá mais à frente.
#3 – Quando não devo usar MongoDB?
Nem tudo são flores e o MongoDB não é uma “bala de prata”, ele não resolve todos os tipos de problemas de persistência existentes.
Você não deve utilizar MongoDB quando relacionamentos entre diversas entidades são importantes para o seu sistema. Se for ter de usar muitas “chaves estrangeiras” e “JOINs”, você está usando do jeito errado, ou, ao menos, não do jeito mais indicado.
Além disso, diversas entidades de pagamento (como bandeiras de cartão de crédito) não homologam sistemas cujos dados financeiros dos clientes não estejam em bancos de dados relacionais tradicionais. Obviamente isso não impede completamente o uso de MongoDB em sistemas financeiros, mas o restringe apenas a certas partes (como dados públicos).
Em meu post sobre Persistência Poliglota eu falo bastante dos conceitos por trás de diversos bancos não-relacionais e incluo concorrentes do MongoDB e onde eles devem ser utilizados ao invés deste mecanismo de persistência, dê uma olhada para mais informações neste sentido.

#4 – Instalação e Testes
Diversos players de cloud computing fornecem versões de Mongo hospedadas e prontas para uso como Umbler e mLab, no entanto é muito importante um conhecimento básico de administração local de MongoDB para entender melhor como tudo funciona. Não focaremos aqui em nenhum aspecto de segurança, de alta disponibilidade, de escala ou sequer de administração avançada de MongoDB. Deixo todas estas questões para você ver junto à documentação oficial no site oficial, onde inclusive você pode estudar e tirar as certificações.
Caso ainda não tenha feito isso, acesse o site oficial do MongoDB e baixe gratuitamente a versão mais recente para o seu sistema operacional, que é a versão 6 na data em que escrevo este artigo. Você encontra a versão gratuita na aba Products > Community > Server.
Baixe o arquivo compactado e extraia os arquivos, recomendo colocar em c:\mongo ou outra pasta de fácil localização. Dentro dessa pasta do Mongo podem existir outras pastas, mas a que nos interessa é a pasta bin. Nessa pasta tem um utilitário de linha de comando (exe no Windows) de nome mongod, que serve para subir um servidor de banco de dados.
Para subir um servidor de MongoDB na sua máquina é muito fácil: execute o utilitário mongod via linha de comando como abaixo, onde dbpath é o caminho onde seus dados serão salvos (esta pasta já deve estar criada).
|
1
|
C:\mongo\bin> mongod –dbpath C:\mongodata
|
Isso irá iniciar o servidor do Mongo. Uma vez que as mensagens parem de rolar e não tenha nada sinalizando erro, está pronto, o servidor está executando corretamente e você já pode utilizá-lo, sem segurança alguma e na porta padrão 27017.
Nota: se já existir dados de um banco MongoDB na pasta data, o mesmo banco que está salvo lá ficará ativo novamente, o que é muito útil para os nossos testes.
Agora vamos falar do terminal cliente, para que possamos nos conectar no servidor e enviar comandos para ele. A partir da versão 6 do MongoDB ele deve ser baixado separadamente e se chama Mongo Shell, disponível na seção Tools da área de downloads do site, neste link.
Baixe, extraia o conteúdo do zip e recomendo copiá-lo (todos arquivos) para dentro da pasta bin da instalação do MongoDB, apenas para fins de organização. O arquivo que nos interessa aqui é o mongosh e vou considerar que ele foi deixado ao lado do arquivo mongod, a partir dos próximos comandos, ok?
Agora abra outro prompt de comando (o outro ficará executando o servidor) e novamente dentro da pasta bin do Mongo, digite:
|
1
|
c:\mongo\bin> mongosh
|
Após a conexão funcionar, se você olhar no prompt onde o servidor do Mongo está rodando, verá que uma conexão foi estabelecida e um sinal de “>” indicará que você já pode digitar os seus comandos e queries para enviar à essa conexão.
Ao contrário dos bancos relacionais, no MongoDB você não precisa construir a estrutura do seu banco previamente antes de sair utilizando ele. Tudo é criado conforme você for usando, o que não impede, é claro, que você planeje um pouco o que pretende fazer com o Mongo.
O comando abaixo no terminal cliente mostra os bancos existentes nesse servidor:
|
1
|
> show databases
|
Se é sua primeira execução ele deve listar as bases admin e local. Não usaremos nenhuma delas. Agora digite o seguinte comando para “usar” o banco de dados “workshop” (um banco que você sabe que não existe ainda):
|
1
|
> use workshop
|
O terminal vai lhe avisar que o contexto da variável “db” mudou para o banco workshop, que nem mesmo existe ainda (mas não se preocupe com isso!). Essa variável “db” representa agora o banco workshop e podemos verificar quais coleções existem atualmente neste banco usando o comando abaixo:
|
1
|
> show collections
|
Isso também não deve listar nada, mas não se importe com isso também. Assim como fazemos com objetos JS que queremos chamar funções, usaremos o db para listar os documentos de uma coleção de customers (clientes) da seguinte forma:
|
1
|
> db.customers.find()
|
find é a função para fazer consultas no MongoDB e, quando usada sem parâmetros, retorna todos os documentos da coleção. Obviamente não listará nada pois não inserimos nenhum documento ainda, o que vamos fazer agora com a função insert:
|
1
|
> db.customers.insert({ nome: “Luiz”, idade: 29 })
|
A função insert espera um documento JSON por parâmetro com as informações que queremos inserir, sendo que além dessas informações o MongoDB vai inserir um campo _id automático como chave primária desta coleção.
Como sabemos se funcionou? Além da resposta ao comando insert (nInserted indica quantos documentos foram inseridos com o comando), você pode executar o find novamente para ver que agora sim temos customers no nosso banco de dados. Além disso se executar o “show collections” e o “show databases” verá que agora sim possuímos uma coleção customers e uma base workshop nesse servidor.
Tudo foi criado a partir do primeiro insert e isso mostra que está tudo funcionando bem no seu servidor MongoDB!
E assim encerra a primeira parte do nosso tutorial de MongoDB para iniciantes. Na parte 2, que você confere neste link, falo dos comandos elementares do MongoDB (CRUD) e de modelagem orientada à documentos.
Espero que tenha gostado e até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?