

São dez horas. Você sabe onde estão os seus logs?
Eu estou introduzindo este guia com um trocadilho em um anúncio de serviço público comum, que foi executado na transmissão dos noticiários de TV da tarde/noite nos Estados Unidos, porque a análise de log é extremamente interessante e importante.
Se o seu SEO técnico e on-page for pobre, então nada que você fizer vai ter importância. O SEO técnico é a chave para ajudar os mecanismos de busca a rastrear, analisar e indexar sites, e assim classificá-los de forma adequada, muito antes do início de qualquer trabalho de marketing.
A coisa importante para lembrar: seus arquivos de log contêm os únicos dados que são 100% exatos em termos de como os mecanismos de busca estão rastreando seu site. Ao ajudar o Google a fazer o seu trabalho, você irá definir o cenário para o seu trabalho de SEO futuro e tornar o seu trabalho mais fácil. A análise de log é uma faceta do SEO técnico, e corrigir os problemas encontrados em seus logs vai ajudar a conduzir a classificações mais elevadas, mais tráfego, mais conversões e vendas.
Aqui estão apenas algumas razões:
- Muitos erros de código de resposta podem levar o Google a reduzir o rastreamento do seu site e talvez até sua classificação.
- Você quer ter certeza de que os mecanismos de pesquisa estão rastreando tudo (coisas novas e antigas), que você quer que apareça e que seja rankeado na classificação no SERPs (e nada mais).
- É crucial assegurar que todos os redirecionamentos de URL vão passar qualquer link juice.
No entanto, a análise de log é algo que, infelizmente, é discutido muito raramente nos círculos de SEO. Então, aqui, eu queria dar à comunidade Moz um guia introdutório à análise que eu espero que vai ajudar. Se você tiver alguma dúvida, não hesite em perguntar nos comentários!
O que é um arquivo de log?
Servidores de computador, sistemas operacionais, dispositivos de rede e aplicativos de computador geram automaticamente uma coisa chamada entrada de log sempre que executarem uma ação. Em um contexto de marketing digital e SEO, um tipo de ação é uma página sendo solicitada por um bot ou um humano.
Entradas de log do servidor são especificamente programadas para serem emitidas no formato de log comum do consórcio W3C. Aqui está um exemplo da Wikipedia com minhas explicações que acompanham:
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
- 127.0 .0.1 – O nome do host remoto. Um endereço IP é mostrado, como neste exemplo, sempre que o nome de host DNS não estiver disponível ou o DNSLookup estiver desligado.
- usuer-identifier – O logname remoto/identidade RFC 1413 do usuário (não é tão importante).
- frank – O ID de usuário da pessoa que solicita a página. Baseado no que eu vejo em meu perfil Moz, entradas de log de Moz provavelmente mostrariam tanto “SamuelScott” ou “392388” sempre que eu visitasse uma página depois de ter logado.
- [10/Oct/2000:13:55:36 -0700] – A data, a hora e o fuso horário da ação em questão em formato strftime.
- GET/apache_pb.gif HTTP/1.0 – “GET” é um dos dois comandos (o outro é o “POST”) que podem ser executados. “GET” recupera uma URL, enquanto “POST” é a apresentação de algo (como um comentário em um fórum). A segunda parte é a URL que está sendo acessada, e a última parte é a versão do HTTP que está sendo acessada.
- 200 – O código de estado do documento que foi devolvido.
- 2326 – O tamanho, em bytes, do documento que foi devolvido.
Nota: Um hífen é mostrado em um campo quando essa informação não estiver disponível.
Toda vez que você – ou o Googlebot – visitar uma página em um site, uma linha com essa informação é enviada, gravada e armazenada pelo servidor.
As entradas de log são geradas continuamente e em qualquer lugar. Dezenas de milhares podem ser criadas a cada segundo – em função do nível de um dado servidor, rede, ou a atividade do aplicativo. Uma coleção de entradas de log é chamada de um arquivo de log, e é exibida com a entrada de log mais recente, na parte inferior. Os arquivos de log individuais contêm normalmente um dia de calendário de entradas de log que valem a pena.
Acessando arquivos de log
Diferentes tipos de servidores armazenam e gerenciam seus os arquivos de log de forma diferente. Aqui estão os guias gerais para encontrar e gerenciar as informações de log em três dos tipos mais populares de servidores:
- Acessando arquivos de log do Apache (Linux)
- Acessando arquivos de log do Nginx (Linux)
- Acessando arquivos de log do IIS (Windows)
O que é análise de log?
A análise de log é o processo de passar por arquivos de log para aprender alguma coisa com os dados. Algumas razões comuns incluem:
- Desenvolvimento e garantia de qualidade (QA) – Criação de um programa ou aplicativo e verificação de erros problemáticos para se certificar de que ele funcione corretamente.
- Solucionar problemas de rede – Responder e corrigir erros do sistema em uma rede.
- Serviço ao cliente – Determinar o que aconteceu quando um cliente teve um problema com um produto técnico.
- Questões de segurança – Investigar incidentes de hacking e outras intrusões.
- Assuntos de conformidade – A obtenção de informações em resposta a políticas corporativas ou governamentais
- SEO técnico – Este é o meu favorito! Mais sobre isso daqui a pouquinho.
A análise de log raramente é realizada regularmente. Normalmente, pessoas entram nos arquivos de log somente em resposta a algo – um bug, um hack, uma intimação, um erro, ou uma avaria. Não é algo que ninguém quer fazer de forma contínua.
Por quê? Esta é uma imagem de uma parte muito pequena de um (não estruturado) arquivo de log original:
Ai. Se um site recebe 10.000 visitantes que vão a cada dez páginas por dia, então o servidor vai criar um arquivo de log a cada dia que consistirá de 100.000 entradas de log. Ninguém tem o tempo para passar por tudo isso manualmente.
Como fazer análise de log
Existem três maneiras gerais de tornar a análise de log mais fácil em SEO ou em qualquer outro contexto:
- Do-it-yourself em Excel
- Software proprietário, como Splunk ou Sumo-logic
- O software open source ELK Stack
O ensaio de Tim Resnik no Moz de alguns anos atrás orienta você no processo de exportação de um lote de arquivos de log para o Excel. Essa é uma maneira relativamente rápida e fácil de fazer a análise de log simples, mas a desvantagem é que a pessoa vai ver apenas um snapshot no tempo, e não todas as tendências globais. Para obter os melhores dados, é crucial usar as ferramentas proprietárias ou o ELK Stack.
O Splunk e Sumo-Logic são ferramentas proprietárias de análise de log utilizadas principalmente por empresas. O ELK Stack é um grupo livre e de código aberto de três plataformas (ElasticSearch, Logstash e Kibana), que é de propriedade da Elastic e é usado com mais frequência por pequenas empresas. (Divulgação: Nós, da Logz.io, usamos o ELK Stack para monitorar os nossos próprios sistemas internos, bem como para a base do nosso próprio software de gerenciamento de log.)
Para aqueles que estão interessados em usar esse processo para fazer análise de SEO técnico, sistema de monitoramento ou desempenho de aplicativo, ou por qualquer outra razão, o nosso CEO, Tomer Levy, escreveu um guia para a implantação do ELK Stack.
Insights de SEO técnico em dados de log
Embora você opte por acessar e entender seus dados de log, existem muitas questões importantes de SEO técnico para abordar conforme for necessário. Eu incluí screenshots do nosso painel de SEO técnico com dados do nosso próprio site para demonstrar o que examinar em seus registros.
Volume do bot de crawl
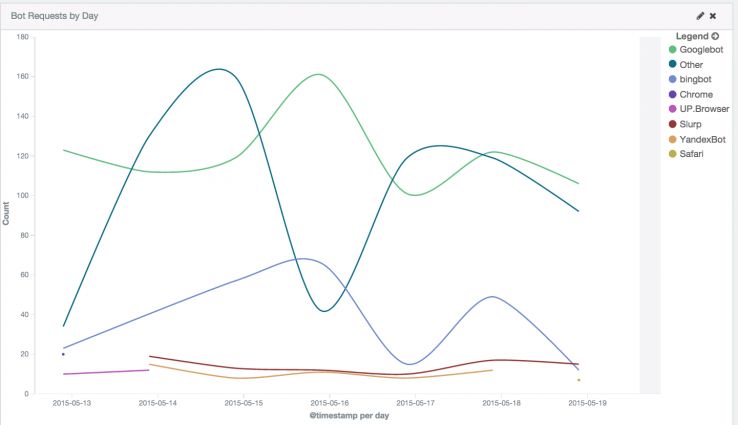
É importante conhecer o número de solicitações feitas por Baidu, Bingbot, GoogleBot, Yahoo!, Yandex e outros ao longo de um determinado período de tempo. Se, por exemplo, você quiser se encontrado na busca na Rússia mas o Yandex não está rastreando o seu site, isso é um problema. (Você vai querer consultar Yandex Webmaster e ler este artigo no Search Engine Land.)
Erros de código de resposta
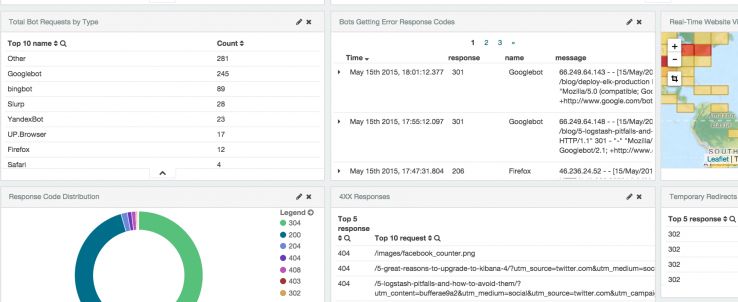
O Moz tem uma cartilha excelente sobre os significados dos diferentes códigos de status. Eu tenho uma configuração do sistema de alerta que me diz sobre erros 4XX e 5XX imediatamente, porque eles são muito significativos.
Redirecionamentos temporários
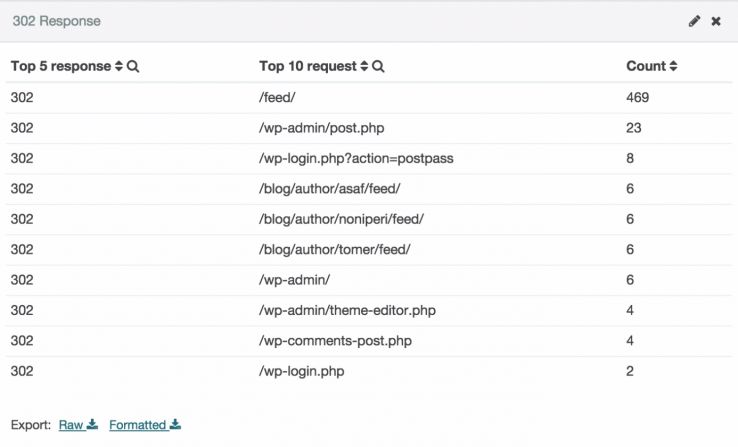
Redirecionamentos temporários 302 não passam o juice de ligações externas da URL antiga para a nova. Quase todo o tempo, eles devem ser alterados para redirecionamentos permanentes 301.
Desperdício de orçamento de crawl
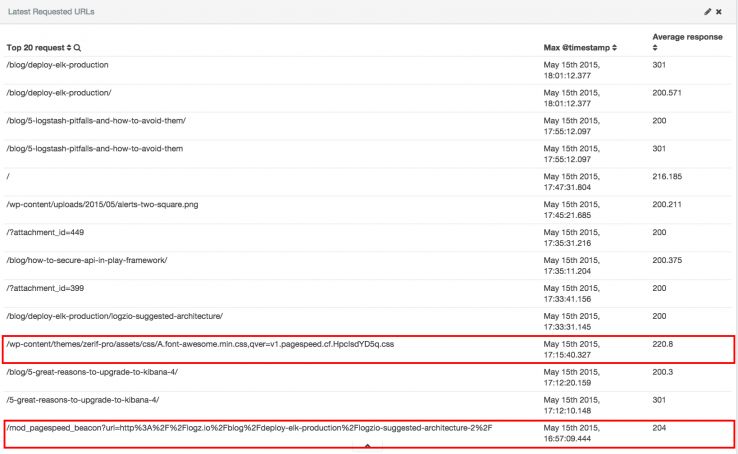
O Google atribui um orçamento de crawl para cada site com base em vários fatores. Se o seu orçamento de crawl for, digamos, 100 páginas por dia (ou a quantidade equivalente de dados), então você vai querer ter certeza de que todas as 100 serão coisas que você quer que apareçam nas SERPs. Não importa o que você escreve nas suas tags robots.txt file e meta-robots, você ainda pode estar perdendo seu orçamento de crawl em publicidade nas landing pages, scripts internos, e muito mais. Os logs te dirão – eu destaquei dois exemplos baseados em scripts em vermelho acima.
Se você atingir o seu limite de crawl, mas ainda tiver novos conteúdos que devem ser indexados para aparecer nos resultados de busca, o Google pode abandonar o seu site antes de encontrá-lo.
Duplicando o crawl de URL
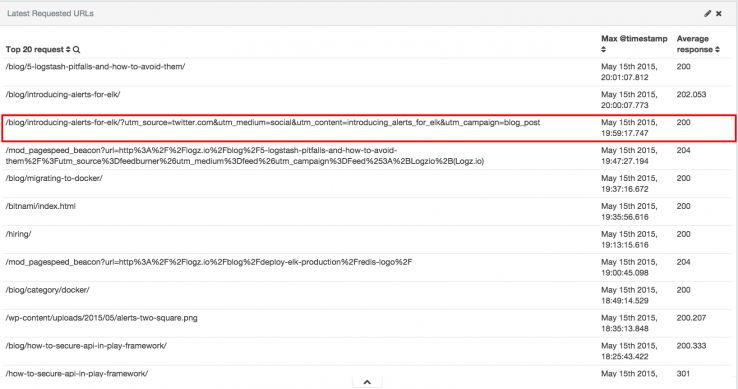
A adição de parâmetros de URL – normalmente utilizados no rastreamento para fins de marketing – muitas vezes resulta nos mecanismos de busca desperdiçando orçamentos ao rastrearem URLs diferentes com o mesmo conteúdo. Para saber como resolver esse problema, eu recomendo a leitura dos recursos no Google e Search Engine Land aqui, aqui, aqui e aqui.
Prioridade de crawl
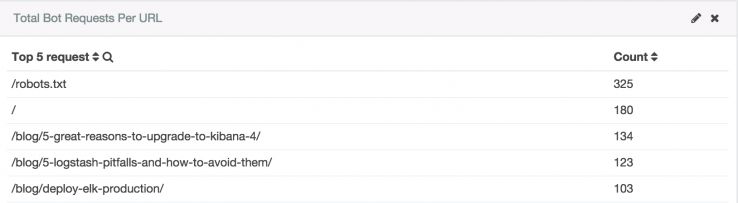
O Google pode estar ignorando (e não rastreando ou indexando) uma página crucial ou uma seção do seu site. Os logs vão revelar quais URLs e/ou diretórios estão recebendo mais e menos atenção. Se, por exemplo, você publicou um e-book que busca um ranqueamento de queries determinadas, mas ele fica em um diretório que o Google só visita uma vez a cada seis meses, então você não vai obter qualquer tráfego de busca orgânica do e-book por até seis meses.
Se uma parte do seu site não está sendo rastreada muito frequentemente – e ele é atualizado com uma frequência apropriada -, então pode ser necessário que você verifique a sua estrutura interna de ligação e as configurações de rastreamento de prioridades no seu Sitemap XML.
Data do último crawl
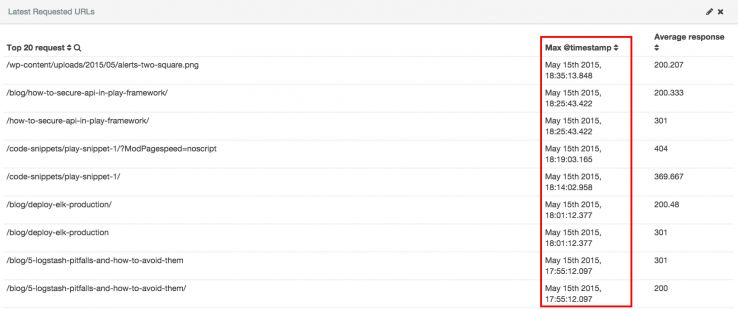
Você fez upload de algo que espera que será indexado rapidamente? Os arquivos de log vão dizer quando o Google o indexou.
Orçamento de crawl
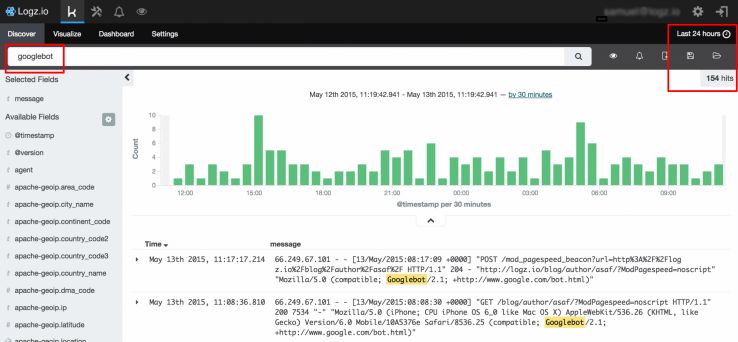
Uma coisa que eu gosto de verificar é a atividade em tempo real do Googlebot em nosso site, pois o orçamento de crawl que o mecanismo de busca atribui para um site é um indicador grosseiro – um muito difícil – de quanto ele “gosta” do seu site. O Google idealmente não quer perder o seu precioso tempo rastreando em um site ruim. Aqui, eu vi que o Googlebot tinha feito 154 solicitações do nosso novo website ao longo das vinte e quatro horas anteriores. Felizmente, esse número vai subir!
Como eu espero que você possa ver, a análise de log é criticamente importante em SEO técnico. São onze horas – você sabe onde os seus logs estão agora?
Recursos adicionais
- Log File Analysis: The Most-Powerful Tool in Your SEO Toolkit (Tom Bennet em BrightonSEO)
- SEO Finds in Your Server Log (part two) (Tim Resnik em Moz)
- Googlebot Crawl Issue Identification Through Server Logs (David Sottimano em Moz)
- Para mais informações sobre ELK Stack (Logz.io), visite Logstash e Kibana.
***
Samuel Scott faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://moz.com/blog/technical-seo-log-analysis. Esta tradução foi feita com permissão. Moz não tem qualquer afiliação com este site.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?