

Recentemente, estive palestrando sobre criação de mecanismos de busca com PHP e MongoDB durante um meetup do PHP RS, aqui em Porto Alegre. Como muitas vezes não conseguimos nos ater a todos os detalhes enquanto espectadores de palestra, resolvi escrever este artigo, que é praticamente um transcript dela, onde ensino os conceitos fundamentais de criação de mecanismos de busca e como fazer um com a linguagem PHP e o banco não-relacional MongoDB.
Para o correto entendimento deste artigo, sugiro que leia primeiro o guest post sobre PHP + MongoDB, que escrevi para o site do PHP RS. Lá, você vai aprender como deixar todo o ambiente rodando corretamente, bem como os principais componentes da biblioteca de MongoDB para PHP, capacitando-o a fazer um CRUD com estas tecnologias.
Neste artigo, você vai ver:
- Por que criar mecanismos de busca
- Conceitos fundamentais
- Organizando o banco de dados
- Programando em PHP
Dito isso, vamos começar.
1. Por que criar mecanismos de busca?
Eu comecei a estudar sobre mecanismos de busca em 2010, quando lancei o Busca Acelerada. De lá pra cá, participei de projetos de implementação de buscadores corporativos, de APIs de busca, de crawlers e de projetos como o BuildIn e o Só Famosos. Não sou nenhum expert no assunto, mas sete anos envolvidos com esses projetos me dão um pouco de confiança para ensinar os outros sobre como fazê-lo.
Mecanismos de busca são muito úteis em diversos cenários, tanto como ferramentas completas quanto como auxiliares em sistemas já existentes. Já tive a oportunidade criar mecanismos que funcionavam como APIs, apenas para indexar os documentos e informações internas da empresa e disponibilizar para consumo dos demais sistemas. Além disso, geralmente, bons mecanismos de busca verticais, aqueles focados em apenas um nicho de informação, atraem uma grande quantidade de visitas e podem ser monetizados sem muito esforço com resultados interessantes.
Ou seja, criar mecanismos de busca é um baita negócio, independente se vai ser para você ou para os outros. O Google que o diga!
2. Conceitos fundamentais
Sem entrar em muitos detalhes e aspectos científicos, existem uns poucos conceitos que temos que ter em mente quando estamos pensando em construir um buscador. Muitos destes já foram evidenciados neste artigo mais antigo e mais teórico.
São eles:
- Fonte de dados
- Classificação
- Indexação
- Pesquisa
- Atualização
2.1 Fonte de dados
O primeiro passo é obter a fonte dos dados que serão pesquisáveis através do nosso buscador. Essa fonte pode ser tão simples quanto a base atual da sua empresa ou do seu cliente, um banco relacional tradicional como SQL Server já serve. Ou então, você pode estar pensando em algo mais complicado, como um webcrawler, também chamado de webspider, que vai varrer a Internet ou a LAN da sua empresa indexando conteúdos que valham a pena serem pesquisados depois.
Não vou entrar em detalhes de como construir a fonte de dados do buscador, deixo essa com você.
2.2 Classificação
Para cada registro, documento, artigo, página web ou o que quer que sua fonte de dados contenha, você deverá efetuar a classificação desse dado. Essa classificação pode ser tão simples, quanto aplicar alguns IFs, quanto complexa, se estiver pensando em usar técnicas de IA como redes neurais e machine learning.
Não importa a sua estratégia, mas sim que o resultado seja satisfatório para o que se propõe. Bole algum tipo de rankeamento entre os documentos/ registros, como o PageRank do Google, que determina a relevância de cada página baseada no número de links apontando para ela versus a relevância dos sites que apontam. No Busca Acelerada, eu tenho o CarRank, ranking gerado a partir da análise de características dos anúncios como ter preço, foto, dados completos, ser de um site confiável etc.
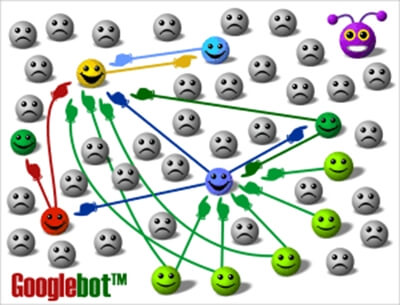
É na etapa de classificação que dados obsoletos ou inúteis devem ser removidos também. Como anúncios sem foto, no caso do Busca Acelerada, pois ninguém gosta de anúncios sem foto. Geralmente, após a classificação, os dados que estavam todos no seu banco SQL agora fazem parte, de maneira classificada e apenas com as informações úteis para pesquisa, de um NoSQL, como MongoDB, que usaremos neste exemplo.
2.3 Indexação
Uma vez que classificou toda a informação que deseja pesquisar mais tarde, é hora de indexá-la de maneira que o buscador consiga encontrar o que o usuário quer da maneira mais rápida possível.
Para que a indexação seja eficiente, é importante que o dado classificado seja normalizado (tudo caixa alta, sem acentos, sem caracteres especiais, só no masculino, só no singular etc), que seus sinônimos sejam mapeados, que as stopwords (preposições, artigos etc) sejam removidas e por aí vai, para evitar lotar o índice com lixo. Essas informações normalizadas devem ser separadas em tags e cada tag deve indicar quais documentos/ registros possuem a mesma.
Esse conceito é o que chamamos de índice invertido, e é o tipo mais básico de índice de busca que podemos utilizar. Em um índice invertido, cada tag normalizada aponta para todos documentos/ registros que contém a mesma. Assim, conseguimos facilmente achar todas ocorrências para o que o usuário procura sem ter de percorrer todos os documentos/ registros atrás das tags.
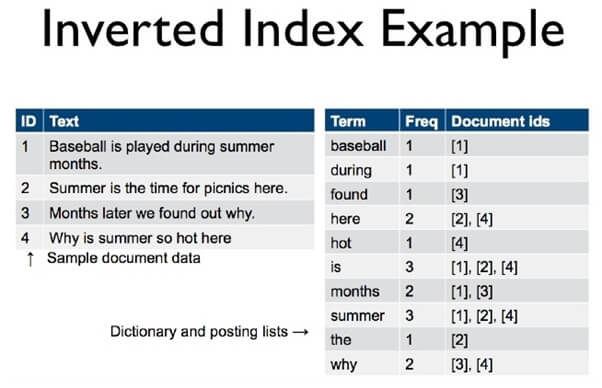
Esse índice invertido de tags deve ser armazenado de alguma forma, para que seja usado pelo algoritmo de busca mais tarde. Uma primeira solução caseira que fiz foi usando estruturas de dados em dicionário, que é razoavelmente eficiente, mas muito volátil (ficava só na memória RAM). Índices invertidos mais profissionais podem ser construídos com Redis (a melhor opção, mas mais cara em termos de hardware) e com MongoDB (o que usaremos mais adiante).
2.4 Pesquisa
A pesquisa em si geralmente não é um grande problema, se você já fez eficientemente as três etapas anteriores.
Basicamente, os termos de pesquisa que o usuário digitar no seu sistema devem passar pelo mesmo processo de normalização da fonte de dados, para que sinônimos e companhia sejam considerados; bem como caracteres especiais e etc. sejam ignorados.
Após esse processo, os termos de pesquisa do usuário devem ter sido transformados em tags. Essas tags devem ser verificadas junto ao índice, para descobrir quais documentos/ registros entregam o que o usuário busca, para depois pegarmos os documentos/ registros em questão, conforme as regras de busca que estivermos aplicando (AND ou OR). Aqui um pouco de teoria dos conjuntos cai bem.
O resultado desta etapa é uma pesquisa funcionando rápida e eficientemente. Se sua classificação ficou boa, inclusive a ordenação dos resultados será relevante para o usuário.
2.5 Atualização
Embora muitos achem que o trabalho de construir um mecanismo de busca termine quando a pesquisa estiver funcionando, isso não é verdade. Uma vez que todas engrenagens estejam funcionando, é hora de pensar em como você vai atualizar o seu índice, para manter os resultados de busca sempre atualizados e relevantes para os usuários. Já imaginou se o Google não atualizasse seu índice com frequência?
Você vai precisar definir uma estratégia para sua atualização de índice, baseado no orçamento que tem para hardware, na frequência de atualização necessária para o seu negócio, na tecnologia do seu índice invertido etc. Geralmente, usamos uma de duas estratégias: live update ou rebuild index.
Definir que as atualizações sejam ao vivo requer uma tecnologia de índice boa de verdade, como Redis ou MongoDB (nessa ordem), mas vai exigir mais memória RAM para que aconteça rapidamente sem onerar o disco e consequentemente o banco (o que deixaria lento para os usuários). Definir atualizações baseadas em reconstrução de índice exige menos custo, mas mais organização. Mas ela pode gerar um buscador não atualizado quanto seu cliente gostaria. Nesse caso, os índices são reconstruídos em algum(ns) momento(s) do dia.
No Busca Acelerada, os índices são reconstruídos todos os dias às 11h da manhã. Já no Só Famosos, usamos o conceito de live update e os índices estão sempre atualizados. E por fim, o Google, usa os dois conceitos: live update para notícias e rebuild index para demais sites, que não exigem atualização instantânea do seu buscador.
Como consegui live update com o Só Famosos?
Usando MongoDB, é claro!
3. Organizando o banco de dados
Eu vou ensinar como uso o MongoDB no Só Famosos, e como pretendo usar na nova versão do Busca Acelerada, que deve sair ainda esse ano.
Basicamente, se você não está acostumado com o MongoDB, você terá de baixá-lo no site oficial e extrair os arquivos no seu sistema operacional (ele é escrito em C++, roda em todas plataformas). Ele é gratuito, então, não se preocupe com custos.
O MongoDB é um banco de dados orientado a coleções de documentos. Sendo assim, na etapa de classificação, você terá um documento no MongoDB para cada item que deseja pesquisar mais tarde (anúncios de veículos, no caso do Busca Acelerada, por exemplo). Os documentos do MongoDB permitem campos (equivalente às colunas do SQL) de vários tipos, incluindo arrays de valores, o que casa bem o conceito de tags que você terá de aplicar após a indexação dos dados.
Colocar o MongoDB pra rodar é muito simples. Você deve navegar via terminal até a pasta bin dentro da instalação do MongoDB e executar o utilitário “mongod”, como abaixo:
C:\mongodb\server\3.x\bin> mongod -dbpath C:\mongodb\server\3.x\data
É importante salientar que você só obterá o máximo de performance com o MongoDB se rodar com RAM sobrando na sua máquina, no mínimo o necessário para subir sua principal coleção de documentos e seus índices, que serão os elementos mais requisitados pelo buscador.
Como os documentos do MongoDB são schema-less, você não precisa modelar o banco de dados com antecedência e pode aceitar itens de todos os tipos para serem consultados, desde que os componentes textuais que serão usados na pesquisa tenham passado pela normalização que citei anteriormente e tenhamos um campo array chamado “tags” em todos documentos.
Como quero facilitar as coisas para você, vamos inserir uma carga de dados já normalizada em tags no seu MongoDB, usando o código abaixo, que deve ser executado dentro do utilitário de linha de comando ‘mongo’, presente na pasta bin da sua instalação de MongoDB:
C:\mongodb\server\3.x\bin> mongo
use luiztools
custArray = [{"nome":"Luiz Júnior", "profissao":"Professor", "tags":["LUIZ","JUNIOR","PROFESSOR"]},
{"nome":"Luiz Fernando", "profissao":"Autor", "tags":["LUIZ","FERNANDO","AUTOR"]},
{"nome":"Luiz Tools", "profissao":"Blogueiro", "tags":["LUIZ","TOOLS","BLOGUEIRO"]},
{"nome":"Luiz Duarte", "profissao":"Blogueiro", "tags":["LUIZ","DUARTE","BLOGUEIRO"]}]
db.customers.insert(custArray);
Aqui definimos que vamos usar o banco luiztools, que passará a existir automaticamente assim que inserirmos dados nele. Na sequência, definimos um array de objetos JSON (formato que o MongoDB usa para guardar os dados) que contém 4 clientes fictícios e já possuem um campo tags com as mesmas normalizadas.
Note que joguei todas as informações que quero poder usar na pesquisa mais tarde: nome e profissão. Note também que não defini um identificador único para cada documento, o que o MongoDB fará automaticamente para mim, criando um campo _id com um ID auto-gerado e não-repetível.
Esse array JSON é inserido no MongoDB, na coleção customers (que será criada neste momento, automaticamente) e usando o comando insert. O resultado desse comando deve indicar que quatro documentos foram inseridos (nInserted: 4).
Uma vez que todos documentos tenham um campo “tags” com um array de Strings, agora você deve criar um índice nesse campo para que a busca nele seja o mais eficiente possível. O MongoDB entende que campos array, quando indexados, devem ser indexados de maneira invertida, que é exatamente o que esperamos em um buscador. Você deve criar um índice no campo tags usando o comando abaixo:
db.customers.createIndex({ "tags": 1 });
E com isso, nosso banco está preparado para nosso buscador!
Se você acha que foi fácil demais para ser tão bom quanto estou dizendo, saiba que essa configuração que ensinei permite que bases com dois milhões de registros tenham retorno de pesquisa em milisegundos usando oito termos de pesquisa ao mesmo tempo! Acredite quando eu digo que é um buscador simples mas eficiente.
Próximo passo, PHP!
4. Programando em PHP
Agora que nosso banco está pronto, está na hora de programarmos em PHP!
Confesso que não sou nenhum expert em PHP, meu envolvimento com esta linguagem é mínimo. No entanto, mesmo com conhecimentos tão básicos, vou conseguir te mostrar como fazer o buscador direitinho.
Primeiro, você vai ter, primeiro, que configurar seu PHP para se comunicar com o MongoDB, através do driver oficial chamado ‘mongodb’ (não confundir com o driver ‘mongo’, que é obsoleto). Esse driver pode ser obtido via linha de comando usando seu gerenciador de pacotes favorito e até mesmo via GitHub, como no exemplo abaixo para Linux:
$ git clone https://github.com/mongodb/mongo-php-driver.git $ cd mongo-php-driver $ git submodule sync && git submodule update –init $ phpize $ ./configure $ make $ sudo make install
Uma vez que você tenha baixado o driver do MongoDB para PHP, você deve adicionar essa extensão no seu php.ini, como abaixo:
extension=mongodb.so
Para saber se fez tudo corretamente, você pode rodar um phpinfo() ou pode criar o seu arquivo pesquisa.php e tentar criar uma conexão com o seu banco de dados, usando o código abaixo:
$mongo = new MongoDB\Driver\Manager( ‘mongodb://localhost/luiztools’);
Note que esse meu exemplo de conexão considera um banco rodando em localhost com uma base nomeada luiztools. Caso você não tenha instalado o driver corretamente, vai dar erro de que não conseguiu encontrar essa classe MongoDB\Driver\Manager.
Com a conexão funcionando, vamos criar um formulário de pesquisa em HTML?
Abra o seu pesquisa.php (ou crie-o, caso ainda não tenha feito) e dentro, cole o seguinte código HTML:
<html>
<head></head>
<body>
<form method=”GET” action=”pesquisa.php”>
<p><label for=”txtPesquisa”>Pesquisa: <input type=”text” id=”txtPesquisa” name=”txtPesquisa” /></p>
<input type=”submit” value=”Pesquisar” />
</form>
</body>
</html>
Esse código é bem tosco e não faz jus às minhas habilidades de frontend. #sqn
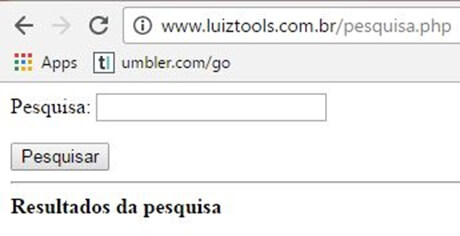
No entanto, é o suficiente para testarmos nosso buscador. Note que o form dessa página vai fazer um GET na mesma, passando o campo txtPesquisa pela querystring. Sendo assim, vamos ao código PHP que vai ler essa requisição e ir no banco de dados:
<?php
$search = explode(' ', $_GET['txtPesquisa']);
$mongo = new MongoDB\Driver\Manager('mongodb://localhost/luiztools');
$filter = ['tags' => ['$all' => $search ] ];
$query = new MongoDB\Driver\Query($filter, ['sort' => [ 'nome' => 1], 'limit' => 5]);
$rows = $mongo->executeQuery("luiztools.customers", $query);
foreach ($rows as $row) {
echo "$row->nome : $row->profissao\n";
}
?>
Opa, foi rápido demais, não?!
Vamos ver em partes:
$search = explode(' ', $_GET['txtPesquisa']);
Aqui pegamos o txtPesquisa da QueryString e transformamos ele em um array de tags que eu chamei de $search. Em um cenário ideal, você deve fazer toda uma normalização dos dados da pesquisa aqui (caixa alta, singular, masculino, sinônimos etc), para que a busca fique mais flexível e o usuário não tenha de “acertar na mosca”, como o dado está salvo no banco.
A próxima linha é a da conexão. Vamos pulá-la (eu já expliquei antes) e vamos à construção do filtro da consulta:
$filter = ['tags' => ['$all' => $search ] ];
Os filtros das consultas são construídos usando arrays associativos. Neste caso, estou dizendo que o filtro deve se basear no campo tags. Como este campo é um array e eu quero pesquisar um outro array dentro dele, eu tenho de usar uma de duas regras: $all (AND) ou $in (OR). Aqui, optei por $all, o que quer dizer que o filtro só retornará documentos do banco que contenham todas as tags que o usuário informou na pesquisa.
O MongoDB possui vários operadores interessantes como $all, $in e muitos outros. Vale a pena dar uma olhada na documentação, pois é ligeiramente diferente dos bancos SQL.
O próximo passo é construir o objeto de consulta do banco, que aqui eu chamei de $query:
$query = new MongoDB\Driver\Query($filter, ['sort' => [ 'nome' => 1], 'limit' => 5]);
$rows = $mongo->executeQuery("luiztools.customers", $query);
O objeto Query é pertencente ao driver do MongoDB para PHP e seu construtor exige o filtro (que criamos antes) e opcionalmente as queryoptions, que é um array associativo que aqui eu defini o sort (ordenação, nome crescente) e o limit (paginação, 5 documentos). Na sequência, mandei executar a Query sobre a coleção luiztools.customers, usando a conexão ($mongo) que havia criado antes.
Isso vai retornar um array de objetos customer com nome, profissão e _id que você pode usar como quiser e que eu fiz o lindo exemplo abaixo:
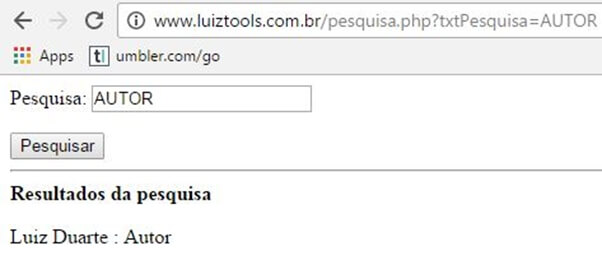
E com isso, encerro este artigo. Claro, tem muitas outras coisas que você pode fazer para melhorar esse buscador, a começar pela interface precária, usar Ajax na pesquisa, colocar mais profundidade no buscador etc. Mas deixo esse “abacaxi” pra você descascar!
Caso vá colocar esse buscador como público na Internet, sugiro dar uma olhada nesse artigo sobre SEO para buscadores.
Seguem os slides da palestra original: Mecanismo de busca PHP + MongoDB

De 0 a 10, o quanto você recomendaria este artigo para um amigo?