

Quando se discute sobre localização de dispositivos, divide-se essa área em duas frentes: localização indoor e outdoor. Com relação a precisão em localizações outdoor, o GPS junto com a infraestrutura de rede de celulares fornecem resultados satisfatórios para a maioria das aplicações. Hoje, através do GPS, obtém-se erros de localização de apenas 5 metros [2].
Contudo, um novo desafio para essa área consiste em atingir eficiência energética maior com a mesma precisão. A barreira surge devido ao fato de dispositivos com GPS atingirem um nível de consumo alto considerando a Internet das Coisas (IoT). Como alternativa, propõe-se estratégias de localização outdoor através de fingerprint, utilizando dispositivos IoT e seus sensores disponíveis [1].
Fingerprints são registros no ambiente de dispositivos com suas características dos sensores e posição conhecidas. Através desses registros os algoritmos são capazes de estimar posições para dispositivos com suas características desconhecidas.
Embora as soluções para um contexto outdoor tenham um certo nível de amadurecimento, o mesmo não ocorre com relação a localização indoor. Os mecanismos utilizados no contexto outdoor não funcionam em ambientes fechados, sobretudo, devido à característica do sinal trafegado. Estes sinais possuem comprimento de onda grande o suficiente o que os impede de adentrar nestes locais.
Sendo assim, também fazendo uso de dispositivos IoT [1], mas utilizando outras estratégias, surgem alternativas com tecnologia wireless para esse cenário. Estratégias mais tradicionais fazem uso de informações como o Received signal strength indication (RSSI), Angle of Arrival (AoA) e Time of Arrival (ToA) para a obtenção da localização.
A respeito deste trabalho, o desafio estava em desenvolver uma solução de localização indoor empregando somente a informação do RSSI. Para tanto, fez-se necessário estudar e entender como funciona este sinal. O RSSI informa a força do sinal entre dois dispositivos que estão se enxergando.
A grande problemática do sinal RSSI está no seu comportamento não linear com relação à distância entre os dois dispositivos envolvidos. Distâncias equivalentes podem ter resultados diferentes devido ao ambiente, como reflexão do sinal e multi-paths.
Além disso, o comportamento do sinal entre dois dispositivos a uma mesma distância varia de acordo com a barreira física, e tem uma relação direta com o tipo do material. Na literatura, é chamado de line-of-sight (LOS) os cenários onde dispositivos estão em visada direta, já em cenários com obstrução damos o nome de non-line-of-sight (NLOS).
Desta forma, conforme observado em investigações, existem algoritmos que levam em conta essa dinâmica do sinal e outros que não. No que se diz respeito aos cenários NLOS, dois se destacam nas análises: Iterative Weighted kNN (IWKNN) [3] e o Polynomial Regression Model (PRM) [4]. O que há em comum entre estes dois algoritmos é que ambos baseiam-se em um processo de calibração através de fingerprints e testpoints pré cadastrados do ambiente.
A ideia de escolher dois algoritmos surge do fato de estudos relevantes utilizarem uma estratégia em conjunto, compondo o resultado final com o resultado de cada um dos algoritmos, ou até mesmo dando a opção ao usuário de em determinado contexto escolher qual algoritmo utilizar, visto que alguns algoritmos podem se sair melhor do que outros em cenários específicos.
Note que uma solução de localização indoor tem nos algoritmos que estimam a posição a sua principal funcionalidade, mas a solução não é somente isso. É necessário uma arquitetura bem definida que contemple todas as fases do processo, desde a coleta dos dados RSSI de dispositivos no ambiente, até a visualização da posição pelo usuário. Na seção seguinte discute-se a arquitetura escolhida e seus componentes.
Arquitetura
Os algoritmos utilizados para a computação da localização são somente o primeiro passo para se desenvolver uma solução. De fato, possuíam-se quatro Access Points (AP) e alguns beacons que seriam utilizados para capturar a localização. Uma solução de localização indoor envolve um ecossistema capaz de capturar os dados do ambiente, processar e apresentar informações relevantes.
Os requisitos para a solução incluíam a execução da aplicação em edge ao invés de cloud. Essa característica limita um pouco as ferramentas que poderiam ser utilizadas, visto que na edge existem diversas aplicações em concorrência com a solução desenvolvida. Dessa forma, ferramentas como o Kafka, por exemplo, poderiam gerar gargalos.
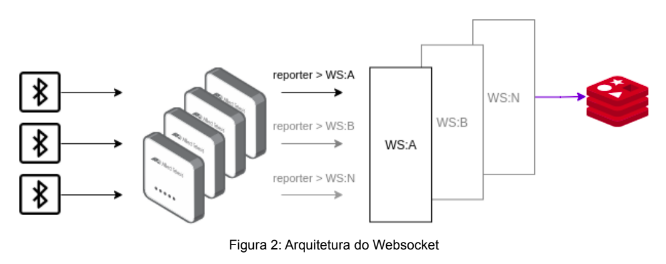
Com relação a captura dos dados, os APs permitiam a configuração de um endpoint WebSocket (WS) para enviar os beacons encontrados no ambiente. Diante disso, optou-se pelo uso de WS como o primeiro componente da arquitetura, onde sua responsabilidade consiste em capturar dados advindos dos beacons e replicá-los com os outros componentes da arquitetura através de alguma base de dados. A base de dados escolhida foi o Redis, visto que se trata de uma base de dados in-memory, o que é bom para um contexto de edge.
Além disso, o Redis oferece uma Message Queue (MQ) interna, o que elimina a necessidade de outra ferramenta para este fim. Portanto, o WS tem como objetivo armazenar os dados capturados dos beacons no Redis, que serão consultados no processo de computação da localização, e enviá-los para o Beacon Orch, através da MQ, a informação de qual AP reportou qual beacon.
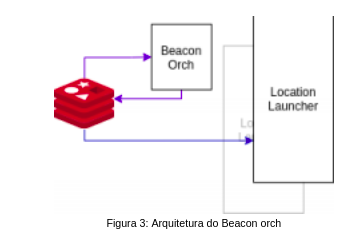
O Beacon Orch é o segundo componente da arquitetura cuja principal função é indicar para a etapa seguinte qual o beacon que deve ser computado. A literatura sugere três APs como número mínimo para o cálculo de localização. Por tanto, um beacon só deve ser submetido ao processamento se pelo menos essa quantidade for atendida. O beacon é submetido para a próxima etapa também através de uma fila MQ.
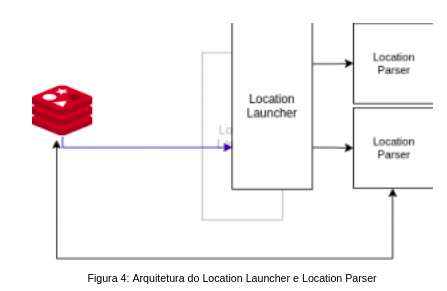
O elemento que faz a leitura dos beacons a serem processados é o Location Launcher (LL). Como já foi comentado anteriormente, ambos algoritmos utilizados aqui necessitam de um processo de calibração, que tem como resultado dados armazenados de forma offline que foram utilizados no processamento.
Desta forma, o primeiro papel do LL é identificar se, para o ambiente que o processamento deve ser feito, existem dados offline referente aos dois algoritmos e em caso contrário, realizar o processo de calibração dos algoritmos. Estando certo de que os algoritmos foram calibrados para aquele ambiente, entra o momento de paralelizar os processamentos. Note-se que, em um ambiente, podem existir diversos dispositivos bluetooth sendo reportados pelos AP, sendo assim inviável no contexto de alta demanda computá-los um por vez.
A ideia do LL é servir como um disparador de localizações a serem computadas de forma paralela, utilizando da capacidade dos núcleos de hardware para computar beacons simultaneamente e não gerar gargalos na visualização do usuário. As computações individuais de cada dispositivo bluetooth são realizadas através do Location Parser (LP).
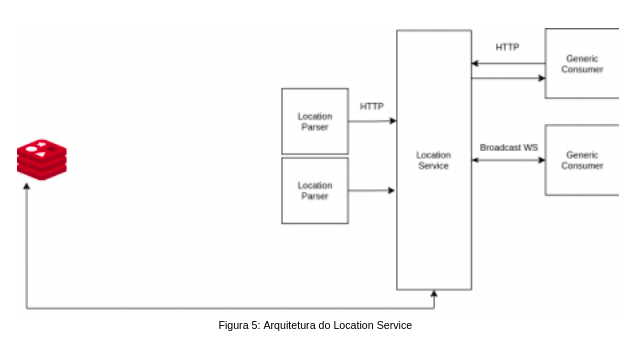
O LP é a engine de processamento onde as fases de computação (online) de cada um dos algoritmos são executadas a fim de se obter a localização do dispositivo. Ao término de cada computação, tem-se o resultado sendo persistido no Redis e também enviado para o último componente da arquitetura, o Location Service (LS). Há necessidade da persistência para permitir uma busca histórica da posição de um determinado dispositivo.
O LS é o componente arquitetural que estabelece uma relação com o usuário, é ele quem mostra para o usuário o resultado em si e transforma todos os dados que foram trafegados e processados ao longo da solução em informação concreta. Através de uma requisição http POST o LS recebe os resultados do processamento do LP e apresenta um mapa com a posição estimada dos dispositivos em uma aplicação Web.

A Figura 1 mostra a arquitetura completa, com cada um dos seus elementos e a relação entre eles. Note que alguns elementos como o WS e o LL são escaláveis e estão diretamente relacionados a um ambiente em específico. Ou seja, para um determinado ambiente, com um determinado número de APs, existe um WS específico e um LL específico para atender a demanda daquele local.
Desenvolvimento
WebSocket
O serviço de Websocket (WS) é a primeira camada dos serviços da aplicação, que é designado para ser uma interface entre os AP ‘s, coletando um conjunto de informações e salvando em um banco de dados em memória (Redis DB) e colocando-os em uma fila MQ (Redis Stream).
Utilizando a linguagem de programação Golang, a implementação consiste no seguinte pseudo-código:
- I) As mensagens advindas do AP são coletadas;
- II) Em seguida estas são enviadas para o WS, onde são descompactadas pelo protocolo Protobuf (protocolo cujo propósito é serializar e desserializar dados estruturados);
- III) Cada par de AP-Beacon recebido, extraem-se as informações referentes ao sinal RSSI, TX-POWER e timestamp que são salvos no banco de dados (Redis DB) e inseridos na fila MQ juntamente com os Mac Addresses do AP que foi reportado e o do Beacon.
Beacon Orch
O Beacon Orch é responsável por identificar as incidências dos beacons no conjunto mínimo de APs ou da malha de AP ‘s de um ambiente para obter uma localização. Uma vez identificado, o Beacon Orch sinaliza para uma nova Stream Redis com a referência do Beacon para a execução do algoritmo de reconhecimento de localização.
O Beacon Orch inscreve-se na fila de mensagens que o WebSocket realiza publicações dos dados referentes ao par AP-Beacon, realizando análises sobre quantos AP’s contém na malha e o número mínimo de AP’s necessários para receber dados. Após isto reporta-os para uma nova Stream Redis que será consumida pelo Location Parser.
Location Launcher e Location Parser
O Location Launcher & Parser (LL) é responsável por garantir que os algoritmos possuam calibração para o cenário de trabalho, assim como reportar para o usuário quaisquer erros que possam acontecer durante o processamento.
Secundariamente, o LL também é responsável por gerenciar a inicialização dos LPs com o objetivo de fornecer ao usuário as computações das posições dos dispositivos bluetooth. Os processos de inicialização são disparados no momento em que ocorre a leitura da MQ que o Beacon Orch é responsável por publicar.
Como mencionado anteriormente, o LP é capaz de computar a estimativa da posição do dispositivo bluetooth a ser encontrado. Para um determinado usuário, várias instâncias do LP podem executar de forma paralela. Diante disso, optou-se pelo uso da linguagem de programação Golang, que possui um bom desempenho em paralelismo.
O LP utiliza-se de dois pacotes que implementam os algoritmos de PRM [4] e IWKNN [3], também em Golang. Estes pacotes possuem funções relacionadas a suas partes offline e online. O desafio dessa etapa foi a implementação dos algoritmos mencionados, visto que estes não possuem implementação na linguagem desejada.
Com relação às fases offline, foi desenvolvido uma rotina que recebe como entrada o ambiente a ser calibrado e tem como saída o armazenamento da estrutura de dados correspondente à calibração no banco de dados Redis.
O algoritmo PRM baseia-se na resolução de sistemas matriciais, assim são utilizados pacotes da biblioteca padrão da linguagem na criação de um pacote customizado.
Já com relação ao IWKNN, para o processo de clusterização dos fingerprints serem realizados, foi necessário a implementação de dois algoritmos separadamente: Canopy e KMeans.
É importante entender também que tanto para o PRM como para o IWKNN existem variáveis utilizadas na fase online e que devem ser escolhidas durante a fase de calibração. Neste processo, os testpoints tem um fator fundamental, dado que a partir dos fingerprints obtenha-se resultados de calibração com melhor desempenho para a métrica de mean squared error (MSE) utilizada.
Depois de todas as estruturas do PRM e do IWKNN terem sido geradas, bem como as variáveis de configuração dos algoritmos, as fases online tem o papel de dado um conjunto de amostras de sinais RSSI de um determinado beacon, estimar sua posição com base nas estruturas de calibração. Com relação ao PRM, o sinal RSSI de cada uma das amostras é injetado numa função polinomial que fornece uma distância.
A partir disso, implementa-se o algoritmo de multi-point trilateration que fornece a posição estimada do beacon com base em um número N de distâncias entre este e um AP. Realizado este processo para cada um dos APs existentes no ambiente, tem-se uma posição relativa a cada um destes, de modo que a posição final será a média das posições.
Com o IWKNN o processo é semelhante, a diferença está somente no método. A partir dos cálculos da distância euclidiana entre vetores e seus cossenos, é calculada a posição estimada do beacon de acordo com uma média ponderada dos fingerprints mais semelhantes dentro de um cluster escolhido [3] [4].
Por fim, com o resultado das distâncias estimadas, a função final do LP é de enviar estes resultados através de uma requisição http do tipo POST para o LS, que oferece ao usuário a possibilidade de visualizar os resultados de diferentes formas. Além disso, estes resultados são armazenado no Redis para que pesquisas baseadas no histórico possam ser realizadas. A visualização da arquitetura do LL e do LP podem ser visualizadas na figura 4.
Location Service
O Location Service realiza a comunicação entre os consumidores da solução. Suas principais responsabilidades consistem em: I) Prover interface para consulta do histórico das posições armazenadas, e II) Produzir eventos de notificação em tempo real do posicionamento do(s) Beacon(s) via Websocket .
Os dados de posicionamento são atualizados através do Location Parser, via interface HTTP. Este serviço foi desenvolvido na linguagem Golang, com o intuito de fornecer um back-end que consome os dados da base de dados e interface para requisições http do tipo POST. Esta API serve para que o Location Parser envie o cálculo da localização feita pelos algoritmos (IW-KNN e PRM).
Foi criado também o front-end desenvolvido em Javascript, HTML e CSS, para que se possa visualizar onde que se encontra determinado beacons e tags no plano selecionado. Na interface Web o usuário pode selecionar qual o algoritmo que deseja visualizar a localização ou o usuário pode selecionar a média dos dois Algoritmos.
Fingerprint Register
O Fingerprint register tem como objetivo auxiliar o desenvolvimento durante o processo de cadastros do local e do fingerprint. Este projeto toma proveito dos processamentos realizados pelos serviços de Websocket e Beacon Orch, consumindo a stream produzida por este último. O Fingerprint é constituído de dois scripts, um para cadastro dos parâmetros do ambiente e outro para cadastro do fingerprint. No cadastro do local o usuário é pode adicionar parâmetros como nome, comprimento e largura do ambiente, além de indicar as posições dos APs.
No segundo script – cadastro de fingerprint – o usuário é guiado para a coleta e cadastro de fingerprint baseado no passo e número de sinais RSSI a serem coletados. Para cada ponto a ser cadastrado, o serviço faz a remoção valores discrepantes (outliers) e calcula a média dos demais sinais. Posteriormente, o usuário é questionado quanto a aceitação dos dados de forma a eliminar eventuais anomalias.
Por fim, o usuário tem a possibilidade de cadastrar os pontos de testes necessários para a calibração e testes dos algoritmos de geolocalização. Assim como no fingerprint, esse processo toma como base o tamanho da amostra adotada, se diferenciando dos pontos de fingerprint pela ausência de pós-processamentos.
Resultados
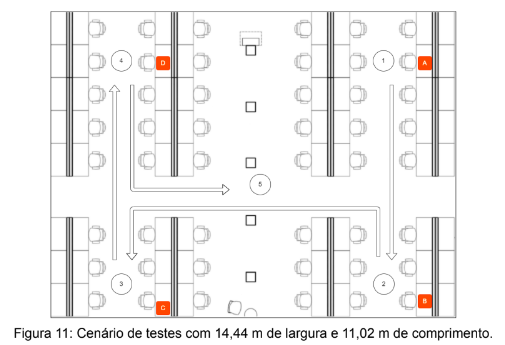
Como discutido anteriormente, o ambiente de testes deste estudo possui 4 APs distribuídos em um um ambiente com 14,44m de largura, 11,02m de comprimento e 4m de pé-direito, esta configuração pode ser observada na Figura 11, na qual podemos notar a disposição do AP ‘A’ no ponto x = 13,55m e y = 0,42m, AP ‘B’ em x = 13,55m e y = 9,55m, AP ‘C’ localizado nas coordenadas x=4,13m e y=0,0m e o AP ‘D’ x = 4,13m e y = 9,13m. Os resultados do processo de cadastro do ambiente no sistema pode ser visto no JSON apresentado na figura a seguir:
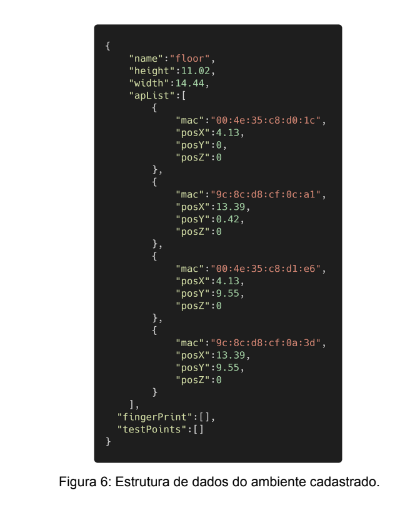
Seguindo o processo de Fingerprint, foi adotado um passo de 2m, visto que passos menores não demonstraram uma diferença significativa. A cada ponto do grid eram obtidas 30 amostras de sinal RSSi dos quais eram removidos outliers e calculado a média. Os resultados gerados para os três pontos iniciais e finais são apresentados na Figura 7.
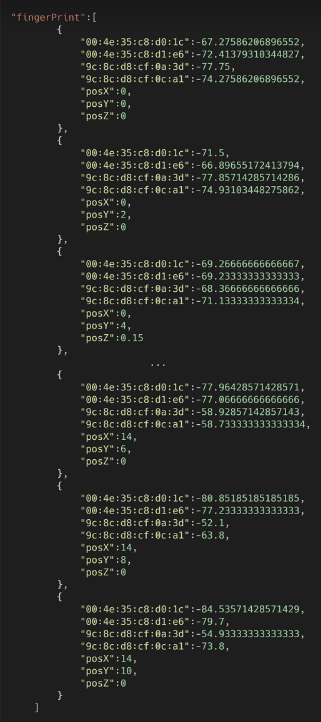
Figura 7: Amostras de dados do Fingerprint cadastrado.
Adicionalmente, foram cadastrados 10 pontos de testes para os quais determinou-se uma amostra de 10 sinais RSSI visando a calibração e eventuais testes dos algoritmos. Um exemplo do conteúdo dos pontos de teste é apresentado na Figura 8.
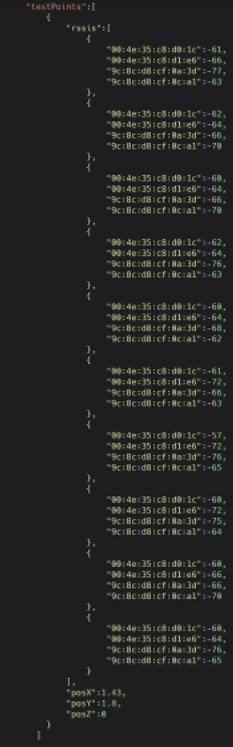
Figura 8: RSSis do Ponto de teste.
Após o cadastro do local, o processo de calibração dos algoritmos PRM e IWKNN são executados. Cada um desses processos fornecem resultados a serem utilizados pela fase online dos algoritmos no processo de computação. Com relação à calibração do PRM ( figura 9), tem-se como resultado os coeficientes do polinômio que representa a relação entre distância e sinal RSSI para cada AP.
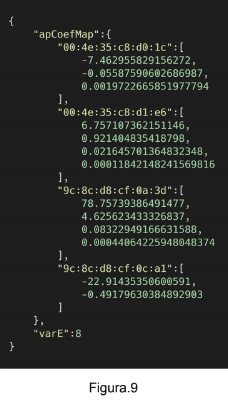
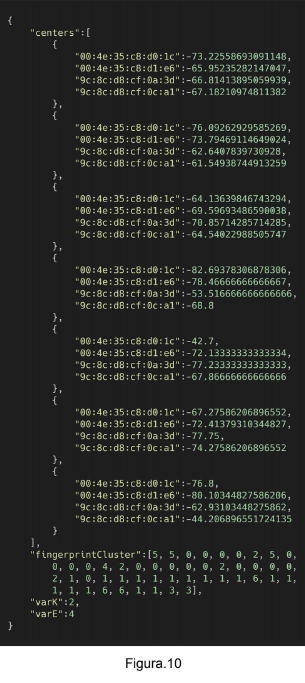
Já com relação ao IWKNN, obtém-se como resultado a clusterização de fingerprints. A
informação armazenada consiste no centro de cada um dos clusters e qual fingerprint está localizado
em qual cluster. O resultado do IWKNN pode ser visualizado na Figura 10.
Para fim de testes em diferentes regiões e cenários, o beacon foi posicionado em cinco pontos do cenário representados por círculos. É importante destacar a presença do quinto e último ponto situado na região central do cenário, esta região tem grande relevância para o projeto visto que está afastada de todos os APs. Devido a este distanciamento, espera-se uma menor eficácia dos algoritmos implementados.
Na Figura 11 observa-se também a presença de setas indicativas que demonstram a movimentação do beacon durante o experimento. No decorrer dos percursos nota-se uma imprecisão no posicionamento apresentado pelos algoritmos associada a flutuação do sinal RSSI neste processo. A estratégia adotada para minimizar o erro durante o procedimento foi estabelecer uma pausa de alguns segundos, permitindo a estabilização da captura do sinal RSSI em cada uma das posições do experimento.
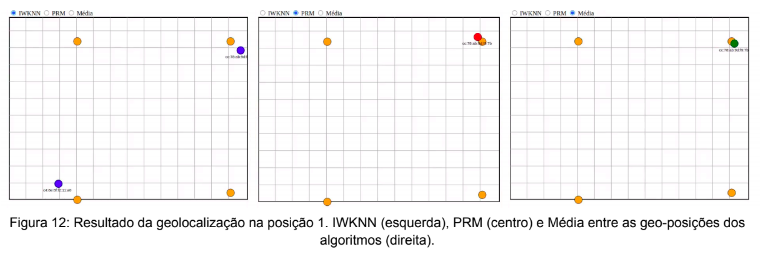
Os resultados do primeiro ponto de análise, o ponto 1, é apresentado pela Figura 12 na qual o beacon encontra-se próximo ao AP ‘A’, que está posicionado nas coordenadas x = 13,55m e y = 0,42m.
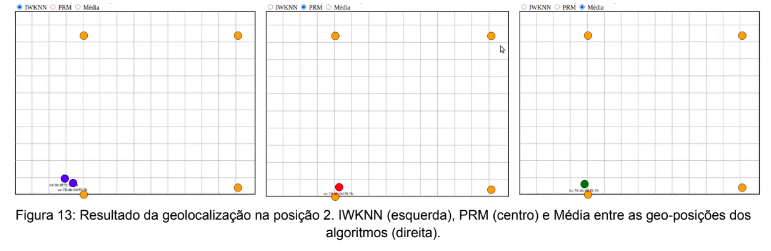
Em seguida o beacon foi movido para o ponto 2 nas vizinhanças do AP ‘B’, ou seja, próximo ao x = 13,55m e y = 9,55m. Os resultados apresentados pelo Location Service são demonstrados na Figura 13.
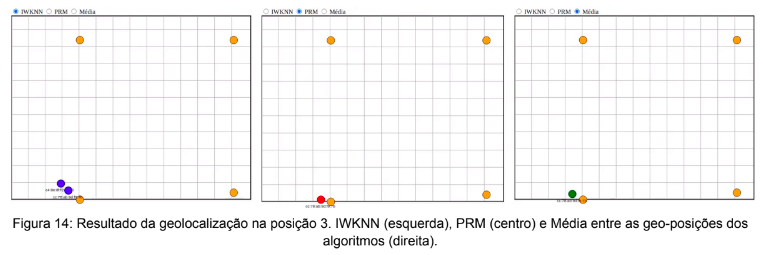
O segundo deslocamento é efetuado para os arredores do ponto x=4,13m e y=0,0m, onde se
encontra o AP ‘C’, identificado como posição 3 na Figura 11. A geolocalização produzida pelos
algoritmos nesse posicionamento pode ser vista na Figura 14.
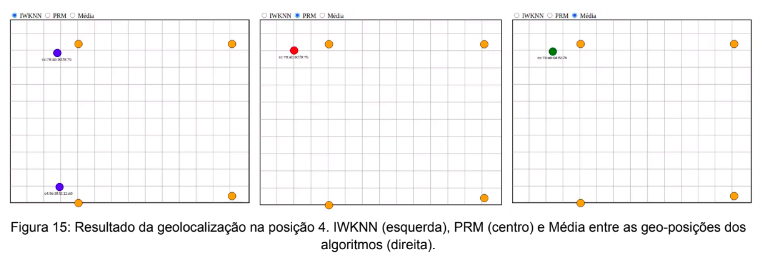
Na Figura 15 pode-se observar os resultados obtidos quando o beacon foi movido em direção ao último AP estacionando na posição 4, o qual se encontra posicionado no ponto x = 4,13 e y = 9,13.
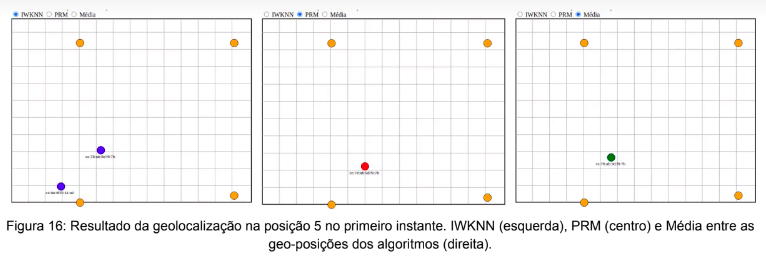
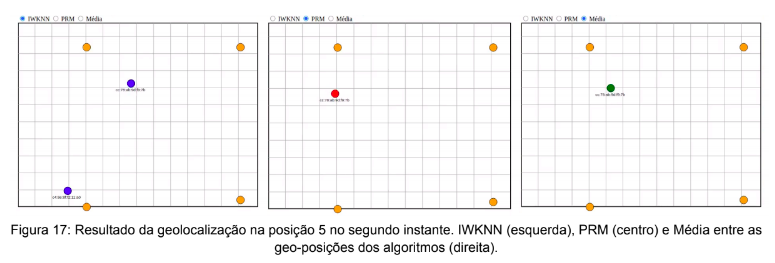
As figuras 16 e 17 apresentam os resultados relacionados à posição 5 da análise. Nelas observa-se dois instantes de tempo os quais visam demonstrar ao leitor a imprecisão obtida nas regiões centrais do mapa. Tal imprecisão deve-se ao distanciamento do beacon dos APs presentes em adição a ausência de qualquer linha-de-visada-direta. Para mitigar este efeito a adição de pontos de acesso no cenário seria necessária de modo a prover maior cobertura sob a área analisada.
Conclusão
Diante dos resultados obtidos, tem-se que a aplicação apresentada nas seções de Arquitetura e Desenvolvimento conseguiu um desempenho satisfatório, mesmo tendo sido desenvolvido num ambiente limitado, com recursos mínimos comparado às literaturas aqui apresentadas. Nestas, por exemplo, para um ambiente similar ao deste estudo, foram empregados 2.5 vezes mais AP para realizar a localização de um beacon. Além disso, a capacidade de captura de um fingerprint foi com um passo de 0.6 metros. Aqui, com relação aos resultados apresentados, quanto mais próximo o beacon dos APs, obtiveram-se valores de erro próximo aos das literaturas em questão.
Dado a solução inicial para o problema, o desafio futuro consiste em continuar a melhorar a acurácia da plataforma e a experiência do usuário. Com relação a acurácia existem alternativas orgânicas e inorgânicas a trabalhar. Alternativas inorgânicas estão relacionadas a obtenção de mais hardware, tanto APs como também a obtenção de mais beacons. O desempenho das estimativas de localização se beneficiam significativamente de um maior número de pontos de acesso para análise. Já com relação aos beacons, no ambiente proposto, os experimentos produziram um total de 48 fingerprints. Todavia, em posse de uma quantidade semelhante de beacons, pode-se ter fingerprints fixados no ambiente e realizar a calibração em tempo real, sendo capaz de pegar alterações pontuais que possam vir a ocorrer, o que é comum em ambientes com muito movimento.
Já as alternativas orgânicas dizem respeito a melhorar os mecanismos que estimam a posição. A arquitetura proposta possui dois componentes que influenciam diretamente o resultado final, o Beacon Orch e o Location Parser.
O Beacon Orch por sua vez, permitirá trabalhos futuros relacionados à inteligência artificial e Machine Learning, possibilitando a orquestração com o objetivo de aprender como os beacons se comportam em determinada área.
Com relação ao Location Parser e as melhorias na estimativa da posição, constata-se na literatura que uma solução para o problema apresentado pode ser composta por três fases. A primeira diz respeito ao tratamento do sinal: diante da não linearidade deste, esta etapa é responsável por empregar técnicas de compensação para mitigar a degradação do sinal – efeitos de propagação, como reflexão, refração, dispersão e difração. A segunda fase, implementada neste estudo , é composta por algoritmos que estimam uma posição. A terceira fase sugere o uso de novos algoritmos: dado uma estimativa, tenta-se reduzir o erro. Na terceira fase existem algoritmos conhecidos envolvendo filtro de kalman, por exemplo. Dessa forma, implementar algoritmos para a fase um e três são novas alternativas para tentar melhorar a acurácia da aplicação.
Referências
[1] A Survey of Fingerprint-Based Outdoor Localization, Quoc Duy Vo
[2] The world’s first GPS MOOC and worldwide laboratory using smartphones, F Van Diggelen, P Enge
[3] An Iterative Weighted KNN (IW-KNN) based Indoor Localization Method in Bluetooth Low Energy (BLE) Environment, Yiran Peng, Wentao Fan, Xin Dong, Xing Zhang
[4] Smartphone-Based Indoor Localization with Bluetooth Low Energy Beacons, Yuan Zhuang, Jun Yang, You Li, Longning Qi, e Naser El-Sheimy

De 0 a 10, o quanto você recomendaria este artigo para um amigo?