

Olá pessoal! Gostaria de compartilhar algo que tem me incomodado ultimamente em relação a toda essa onda de entusiasmo em torno da inteligência artificial.
Todo mundo está falando sobre RAG (Retrieval-Augmented Generation) como se fosse a solução mágica para todos os problemas de aprendizado de máquina. Alimente seus documentos em um banco de dados vetorial, conecte-o ao ChatGPT e pronto — você tem um assistente inteligente que sabe tudo sobre o seu domínio. Certo?
Bem… quase.
Eis a verdade incômoda: mais de 80% dos projetos internos de IA generativa não cumprem o que prometem. E já vi implementações suficientes de RAG fracassarem miseravelmente para entender o porquê.
Este não é mais um tutorial do tipo “Olá, RAG”. Estas são as lições contra-intuitivas que diferenciam sistemas prontos para produção de demonstrações sofisticadas que nunca saem do ambiente de testes.
1. Mais dados são uma armadilha (sim, é verdade)
Seu primeiro instinto ao construir um sistema RAG provavelmente é: “Deixe-me alimentá-lo com TUDO!” Cada mensagem do Slack, cada ticket de suporte, cada documento da última década. Mais dados = melhores respostas, certo?
Errado.
Lembra daquele velho ditado da programação “lixo entra, lixo sai”? Isso é ainda mais verdadeiro para o RAG (lixo entra, lixo sai). A qualidade do seu sistema é diretamente proporcional à qualidade da sua base de conhecimento, e não ao seu tamanho.
Eis o que realmente funciona:
Comece com um núcleo selecionado de fontes primárias de alta qualidade:
- Documentação técnica e referências de API
- Atualizações de produtos e notas de lançamento
- Soluções de suporte verificadas
- Artigos da base de conhecimento
Somente depois de consolidar essa base é que você deve expandir para fontes secundárias, como fóruns ou chamados de suporte. E quando o fizer, aplique filtros rigorosos de atualidade e autoridade.
Pense da seguinte forma: você preferiria fazer uma pergunta para alguém que leu 10 livros excelentes sobre o assunto ou para alguém que apenas deu uma olhada rápida em 1.000 posts aleatórios de blogs? Qualidade sempre supera quantidade.
2. O ajuste fino não é a solução mágica que você pensa que é.
Existem duas abordagens principais para fazer com que um LLM “conheça” sua área de atuação:
- RAG : Forneça o contexto relevante no momento da consulta.
- Ajuste fino : Atualize os pesos do modelo para memorizar informações específicas.
Muitas equipes presumem que o ajuste fino é a solução definitiva. “Vamos simplesmente incorporar nosso conhecimento ao modelo!”
Mas a pesquisa acadêmica conta uma história diferente. Para tarefas de resposta a perguntas que envolvem conhecimento especializado ou de “cauda longa” — o tipo de conhecimento que a maioria das empresas realmente possui — o RAG supera consistentemente o ajuste fino.
Eis por que isso é importante:
Para domínios de nicho e especializados , fornecer informações por meio de recuperação é mais eficaz E menos dispendioso em termos de recursos do que tentar incorporá-las nos pesos do modelo.
Para conhecimentos que mudam frequentemente , o RAG permite atualizações fáceis sem ciclos dispendiosos de retreinamento.
Para modelos menores (com menos de 7 bilhões de parâmetros), o RAG pode ajudá-los a ter um desempenho equivalente ao de modelos vanilla muito maiores.
Portanto, se você estiver criando um chatbot para uma nova API ou produto especializado, o RAG provavelmente é a melhor opção. Reserve o ajuste fino para quando precisar alterar o comportamento do modelo, e não apenas o que ele sabe.
3. A parte mais difícil costuma ser apenas… dividir o texto.
Essa foi a que mais me surpreendeu.
“Fragmentar” — dividir seus documentos em partes menores para incorporação e recuperação — parece trivial. Basta cortar o texto a cada N caracteres e pronto, certo?
Acontece que essa é uma das decisões mais importantes que você tomará, e errar nela compromete todo o resto.
O problema com a divisão em blocos de tamanho fixo é que ela corta frases no meio do pensamento, ignora quebras semânticas e espalha informações relacionadas por diferentes blocos. Seu modelo acaba com um contexto fragmentado e incoerente.
O que realmente funciona:
- Segmentação semântica : Dividir em limites lógicos – frases, parágrafos, seções. Manter conceitos relacionados juntos.
- Fragmentação recursiva : Use uma hierarquia de separadores (quebras de parágrafo, depois frases e, por fim, palavras). Ótimo para conteúdo e código estruturados.
- Fragmentação dinâmica orientada por IA : Permite que um LLM detecte pontos de quebra naturais, ajustando o tamanho do fragmento com base na densidade conceitual.
Pense nisso: se você fizer uma pergunta e o contexto obtido for uma frase cortada ao meio mais um parágrafo aleatório de algum outro lugar, até mesmo o modelo mais inteligente terá dificuldades para lhe dar uma resposta coerente.
Uma boa segmentação resulta em um contexto coerente, o que leva a melhores respostas. É simples assim (e difícil ao mesmo tempo).
4. O banco de dados vetorial “puro” pode ser um beco sem saída.
Com toda a repercussão em torno do RAG, bancos de dados de vetores especializados como Pinecone, Milvus e Qdrant explodiram em popularidade. Eles são a escolha padrão para muitas equipes.
Mas eis uma perspectiva contrária baseada na experiência em produção: confiar exclusivamente em um banco de dados puramente vetorial pode ser uma armadilha para projetos de longo prazo .
Por quê? Porque as aplicações do mundo real precisam de mais do que uma busca por similaridade vetorial:
- Filtragem de metadados : Pesquise documentos de um período específico ou por autores específicos.
- Pesquisa de texto completo : Às vezes, você precisa de correspondências exatas de palavras-chave, e não apenas de similaridade semântica.
- Integração : Você provavelmente já tem um banco de dados – precisa mesmo de outro?
Lembra-se da curadoria cuidadosa de dados da lição nº 1? Essas fontes de alta qualidade geralmente vêm com números de versão, datas ou informações sobre o autor. Você precisa consultar esses metadados de forma eficiente.
A alternativa pragmática:
Bancos de dados que suportam vetores como um recurso — como o PostgreSQL com pgvector, o MongoDB ou o Redis — podem lidar com o armazenamento de vetores juntamente com tudo o mais. Um sistema, uma interface de consulta, menos complexidade operacional.
Não se deixe levar pela euforia e tome decisões desnecessárias em relação à infraestrutura.
5. Uma resposta “boa” não basta – você precisa da tríade RAG.
É aqui que a maioria das equipes falha: elas testam seu sistema RAG com uma simples “verificação de clima”.
“Essa resposta parece correta?”
Isso não é escalável e ignora modos de falha críticos.
Conheça a Tríade RAG – três métricas que oferecem uma visão completa:
Relevância da resposta
A resposta aborda de fato a pergunta do usuário? Um sistema pode gerar informações perfeitamente corretas que ignoram completamente o que o usuário perguntou.
Relevância do contexto
Os documentos recuperados são realmente pertinentes à consulta? Sua recuperação pode retornar conteúdo relacionado, mas inútil.
Firmeza (Fidelidade)
A resposta é de fato sustentada pelo contexto recuperado? Isso detecta alucinações — respostas que soam plausíveis, inventadas pelo modelo.
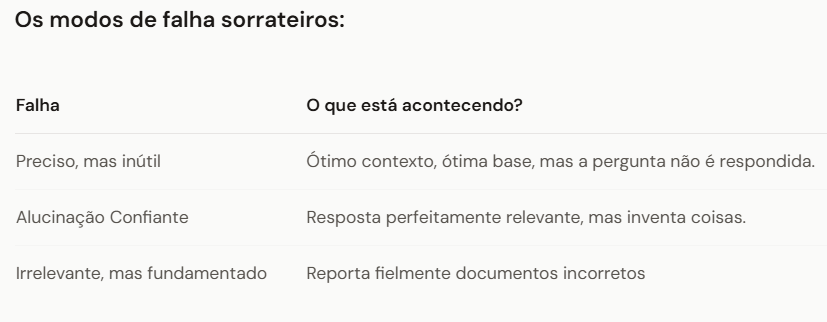
Você pode se destacar em duas métricas e fracassar completamente na terceira. É por isso que você precisa das três.
Isso transforma a garantia de qualidade de uma avaliação subjetiva em ciência mensurável. Defina critérios automatizados de aprovação/reprovação e detecte regressões antes que elas afetem os usuários.
Em resumo: é engenharia, não mágica.
Construir um sistema RAG de produção não se resume a seguir uma receita simples. Trata-se de tomar decisões de engenharia deliberadas:
- Selecione com rigor – Qualidade acima de quantidade, sempre.
- Escolha sua abordagem com sabedoria : RAG para conhecimento, ajuste fino para comportamento.
- Domine a divisão em blocos de conteúdo — é mais difícil e mais importante do que você imagina.
- Escolha uma infraestrutura pragmática – Não complique demais o armazenamento de vetores.
- Meça corretamente – A Tríade RAG, não vibrações.
O caminho da demonstração à produção é pavimentado com essas escolhas contra-intuitivas. A maioria dos tutoriais as ignora completamente — é por isso que a maioria dos projetos falha.
Agora que você conhece as complexidades ocultas, em qual área você se concentrará primeiro?
Está criando um sistema RAG ou enfrentando dificuldades com um? Gostaria muito de saber mais sobre a sua experiência. Encontre-me no Twitter ou no LinkedIn .
Boa construção!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?