

O Nodejs está, cada vez mais, se popularizando, mas já parou para pensar como ele funciona “por baixo dos panos”? Nesse artigo, vou explicar os conceitos de Event Loop, Call Stack, Multi Threading e Task Queue.
Sabemos que o Nodejs é orientado a eventos e segue os princípios de orientação a eventos do Javascript puro client-side.
Como o Nodejs é server-side, esses eventos seriam uma conexão no banco de dados, a abertura de um arquivo, streaming de dados e outras requisições realizadas por um servidor.
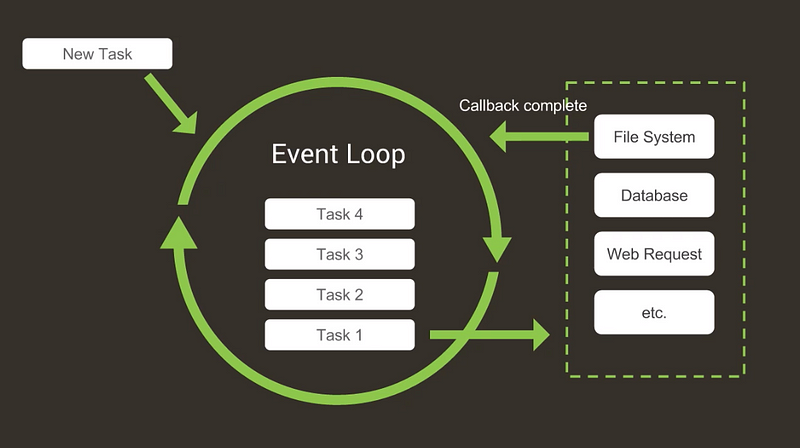
Event Loop
O Event Loop é responsável por capturar e emitir eventos no sistema. De forma resumida, ele é um loop infinito que a cada ação, verifica na sua fila de eventos se aquele determinado foi emitido. Quando isso ocorre, é emitido esse evento, que é executado e vai para a fila de executados.
Estando ele em execução, podemos programar a lógica que desejarmos nele, graças ao mecanismo de callback do Javascript.
Call Stack
A callstack é uma estrutura de dados que armazena em que parte do programa estamos. Ao entrar numa função, ela vai para o topo da stack. Ao retornar de uma função, deixamos o topo da stack. Isso funciona como uma LIFO (Last In, First Out).
Ele funciona da seguinte maneira:
Armazenamento temporário: Quando a função é invocada, seus parâmetros e variáveis vão para a pilha de chamadas de forma que se tornam um quadro de pilha. Este quadro é um local na memória da pilha. Quando a função é retornada, ela é retirada da pilha e a memória é apagada.
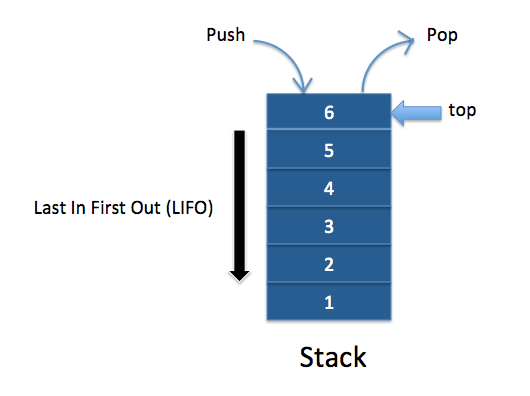
Gerenciando a invocação das funções: Esta pilha de chamadas armazena a posição do registro de cada quadro de pilha. É conhecida a próxima função a ser executada e esta será removida após a execução.
Neste exemplo, podemos ver como ocorre a manipulação dessas chamadas de função:
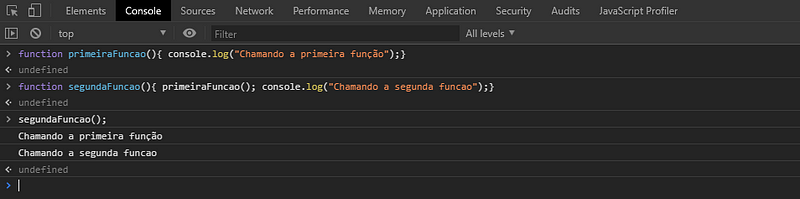
- Quando a segundaFuncao() é executada, um quadro de pilha vazio é criado, que é o ponto de entrada do programa.
- Esta, chama a primeiraFuncao() que é inserida na pilha.
- Como foi invocada, a primeiraFuncao() exibe “Chamando a primeira função” e é retirada da pilha
- Pela ordem de execução, chamamos a segunda função, que vai imprimir “Chamando a segunda função”. Após esta execução, ela é retirada da pilha, limpando a memória.
Multi threading
Por origem, o Node.js é single-thread. Para usá-lo em processamento paralelo, uma solução é o uso de clusters.
Ele cria novos processos, trabalhando de modo distribuído e compartilhando a mesma porta de rede. Temos um cluster pai e cluster filhos (master slave):
Exemplo da criação de um cluster:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Processo Master ${process.pid} está em execução`);
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('Sair', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} morreu`);
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('Olá cluster\n');
}).listen(3000);
console.log(`Worker ${process.pid} iniciado`);
}Como um Cluster funciona:
O cluster.fork() gera os processos de trabalho para que estes possam se comunicar com o processo pai através do IPC (Inter-Process Communication) e passa essas informações do servidor para frente e para trás.
Este método de cluster suporta duas formas de distribuição das conexões de entrada:
1- Padrão em algumas plataformas, que é a metodologia round-robin , na qual o processo mestre atende uma determinada porta, aceita novas conexões e as distribui pelos workers (contém todas as informações e métodos públicos) seguindo a lógica do round-robin para evitar sobrecarregar um processo de trabalho.
2- O processo Master cria um socket de escuta (faz a comunicação entre servidor-cliente, neste caso master-slave) e o envia para os workers envolvidos que aceitam a conexão diretamente.
Como os workers são processos separados, podem ser mortos e iniciados dependendo da necessidade do aplicativo, sem afetar outros workers que estiverem em funcionamento. Enquanto houver um worker vivo, o master continuará aceitando conexões. Quando nenhum estiver ativo, as conexões existentes serão descartadas e novas serão recusadas pelo Master, pois o mesmo não suportará toda carga de trabalho.
A clusterização faz com que a aplicação responda um maior número de requests, reduz o tempo ocioso da CPU.
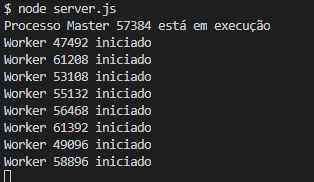
Quando executamos este arquivo, temos a seguinte saída:
Task Queue
Fila de tarefas, fila de trabalhos, podem ser entendidas como uma maneira dos componentes passarem às tarefas entre si para se comunicarem de modo fácil e confiável.
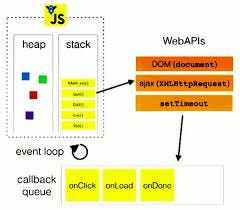
Em node.js tem um próprio gerenciamento dos jobs (por padrão ele trabaha com LIFO conforme dito na seção CallStack) mas também temos alguns módulos que implementam a estrutura FIFO (First-In-First-Out) que não é tão utilizado.
Era isso que queria trazer neste artigo, segue abaixo as referências e dicas de conteúdo, até a próxima ❤
https://github.com/charlesfreeborn/JS-CallStack-CodeSamples/blob/master/codesamples.md
O Nodejs está cada vez mais se popularizando, mas já parou para pensar como ele funciona “por baixo dos panos”? Nesse artigo vou explicar os conceitos de Event Loop, Call Stack, Multi Threading e Task Queue que foram alguns temas que comecei a pesquisar mais para compreender como ele processa nossas requisições e explorar mais suas funcionalidades.
Sabemos que o Nodejs é orientado a eventos e segue os princípios de orientação a eventos do Javascript puro client-side.
Como o Nodejs é server-side esses eventos seriam uma conexão no banco de dados,a abertura de um arquivo, streaming de dados e outras requisições realizadas por um servidor.
Event Loop
O Event Loop é responsável por capturar e emitir eventos no sistema. De forma resumida, ele é um loop infinito que a cada ação, verifica na sua fila de eventos se aquele determinado foi emitido. Quando isso ocorre, é emitido esse evento, que é executado e vai para a fila de executados.
Estando ele em execução, podemos programar a lógica que desejarmos graças ao mecanismo de callback do Javascript.
Call Stack
A callstack é uma estrutura de dados que armazena em que parte do programa estamos. Ao entrar numa função, ela vai para o topo da stack. Ao retornar de uma função, deixamos o topo da stack. Isso funciona como uma LIFO (Last In, First Out).
Ele funciona da seguinte maneira:
Armazenamento temporário: Quando a função é invocada, seus parâmetros e variáveis vão para a pilha de chamadas de forma que se tornam um quadro de pilha, este quadro é um local na memória da pilha, quando a função é retornada, ela é retirada da pilha e a memória apagada.
Gerenciando a invocação das funções: Esta pilha de chamadas armazena um resgitro da posição do registro de cada quadro de pilha, é conhecida a próxima função a ser executada e esta será removida após a execução.
Neste exemplo podemos ver como ocorre a manipulação dessas chamadas de função:
- Quando a segundaFuncao() é executada, um quadro de pilha vazio é criado, que é o ponto de entrada do programa.
- Esta, chama a primeiraFuncao() que é inserida na pilha.
- Como foi invocada, a primeiraFuncao() exibe “Chamando a primeira função” e é retirada da pilha
- Pela ordem de execução, chamamos a segunda função, que vai imprimir “Chamando a segunda função”, após esta execução ela é retirada da pilha, limpando a memória.
Multi threading
Por origem, o Node.js é single-thread, para usá-lo em processamento paralelo, uma solução é o uso de clusters.
Ele cria novos processos, trabalhando de modo distribuído e compartilhando a mesma porta de rede, temos um cluster pai e cluster filhos (master slave):
Exemplo da criação de um cluster:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Processo Master ${process.pid} está em execução`);
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('Sair', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} morreu`);
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('Olá cluster\n');
}).listen(3000);
console.log(`Worker ${process.pid} iniciado`);
}Como um Cluster funciona:
O cluster.fork() gera os processos de trabalho para que estes possam se comunicar com o processo pai através do IPC (Inter-Process Communication) e passa essas informações do servidor para frente e para trás.
Este método de cluster suporta duas formas de distribuição das conexões de entrada:
1- Padrão em algumas plataformas, que é a metologia round-robin , na qual o processo mestre atende uma determinada porta, aceita novas conexões e as distribui pelos workers (contém todas as informações e métodos públicos) seguindo a lógica do round-robin para evitar sobrecarregar um processo de trabalho.
2- O processo Master cria um socket de escuta (faz a comunicação entre servidor-cliente, neste caso master-slave) e o envia para os workers envolvidos que aceitam a conexão diretamente.
Como os workers são processos separadados, podem ser mortos e iniciados dependendo da necessidade do aplicativo, sem afetar outros workers que estiverem em funcionamento. Enquanto houver um worker vivo, o master continuará aceitando conexões , quando nenhum estiver ativo, as conexões existentes serão descartadas e novas serão recusadas pelo Master, pois o mesmo não suportará toda carga de trabalho.
A clusterização faz com que a aplicação responda um maior número de requests, reduz o tempo ocioso da CPU.
Quando executamos este arquivo, temos a seguinte saída:
Task Queue
Fila de tarefas, fila de trabalhos podem ser entendidas como uma maneira dos componentes passarem as tarefas entre si para se comunicarem de modo fácil e confiável.
Em node.js tem um próprio gerenciamento dos jobs (por padrão ele trabaha com LIFO conforme dito na seção CallStack) mas também temos alguns módulos que implementam a estrutura FIFO (First-In-First-Out) que não é tão utilizado.
Era isso que queria trazer neste artigo, segue abaixo as referências e dicas de conteúdo, até a próxima ❤
https://github.com/charlesfreeborn/JS-CallStack-CodeSamples/blob/master/codesamples.md

De 0 a 10, o quanto você recomendaria este artigo para um amigo?