

A latência da rede é um dos nossos principais gargalos de desempenho na web. No pior dos casos, uma nova navegação requer uma pesquisa de DNS, handshake TCP, duas idas e voltas para negociar o túnel TLS e, finalmente, um mínimo de outra ida e volta para a requisição HTTP e sua resposta – isso são cinco idas e voltas de rede para obter os primeiros bytes do documento HTML!
Navegadores modernos se esforçam muito para antecipar e prever a atividade do usuário para esconder um pouco dessa latência, mas otimização especulativa não é uma panaceia: às vezes, o navegador não tem informações suficientes, em outros momentos ele pode errar. É por isso que otimizar o tempo para o primeiro byte (TTFB, ou Time to First Byte, na sigla em inglês) e o TLS TTFB em particular, devido às idas e voltas extras, é fundamental para oferecer uma experiência web consistente e otimizada.
O porquê e o como do TTFB
De acordo com o HTTP Archieve, o tamanho do documento HTML é de aproximadamente até 20 KB em 75% dos sites, o que significa que uma nova conexão TCP incorrerá em várias idas e voltas (devido ao slow-start) para baixar este arquivo – com IW4, um arquivo de 20 KB terá três idas e voltas extras e, atualizando para IW10, reduziria para duas idas e voltas extras.
Para minimizar o impacto das idas e voltas extras, todos os navegadores modernos criam tokens e fazem o parser do HTML recebido de forma incremental e sem esperar que o arquivo completo tenha chegado. Processamento de fluxo permite que o navegador descubra outros recursos críticos, como referências a folhas de estilo CSS, JavaScript e outros recursos o mais rápido possível e possa dar início a essas requisições, enquanto espera o restante do documento. Como resultado, otimizar o seu TTFB e o conteúdo desses primeiros bytes pode fazer uma grande diferença para o desempenho do seu aplicativo:
- Não armazene toda a resposta do servidor. Se você tiver conteúdo parcial (por exemplo, o cabeçalho da página), então envie-o o mais rápido possível para ter o navegador trabalhando para você.
- Otimize o conteúdo dos primeiros bytes, incluindo referências a outros recursos críticos o mais cedo possível.
Medição TLS TTFB do NGINX com configuração padrão de lançamento
Com a teoria da TTFB fora do caminho, vamos nos voltar agora para a questão prática de escolher e ajustar o servidor para entregar os melhores resultados. Seria de se esperar que a experiência padrão de lançamento faria um bom trabalho para a maioria dos servidores… infelizmente, esse não é o caso. Vamos dar uma olhada no nginx mais de perto:
- Servidor Ubuntu recente em ec2-oeste (instância micro) com nginx v1.4.4 (estável).
- O servidor está configurado para servir um único arquivo de 20 KB (comprimido).
- O certificado TLS é de aproximadamente 5 KB e está usando uma chave de 2048 bits.
- As medições são feitas com WebPagetest: perfil 3G (300ms de atraso), Chrome (canal estável), Dulles local (aproximadamente 80ms de RTT na instância EC2, na costa oeste).
O tempo total de ida e volta do cliente ao servidor de é de aproximadamente 380ms. Como resultado, seria de se esperar que uma conexão HTTP normal produzisse um TTFB de aproximadamente 1140ms: 380ms para o DNS, 380ms para handshake TCP e 380ms para a requisição e resposta HTTP (instantânea). Para o HTTPS, poderíamos acrescentar mais dois RTTs para negociar todos os parâmetros necessários: 1140ms + 760ms, ou aproximadamente 1900ms (5 RTTs) no total. Bem, isso é a teoria, vamos agora tentar a teoria na prática!

O TTFB HTTP está na marca (aproximadamente 1100ms), mas o que está acontecendo com HTTPS? O TTFB relatado pelo WebPagetest mostra aproximadamente 2900ms, que é todo o segundo extra além do nosso valor esperado! É o custo do handshake RSA e da criptografia simétrica? Não. Executar benchmarks openssl no servidor mostra que leva aproximadamente 2,5ms para um handshake de 2048 bits, e podemos transmitir aproximadamente 100MB/s através de AES-256. É hora de cavar mais fundo.
Corrigindo um “grande” bug de certificado no nginx
Olhando para o tcpdump da nossa sessão HTTPS, vemos o registro ClientHello seguido da resposta ServerHello aproximadamente 380ms depois. Até aí tudo bem, mas então algo peculiar acontece: o servidor envia aproximadamente 4KB de seu certificado e faz uma pausa para esperar por um ACK do cliente – ahh? O servidor está usando um kernel Linux recente (3.11) e é configurado por padrão com IW10, o que lhe permite enviar até 10 KB. O que está acontecendo?

Depois de cavar o código fonte do nginx, tropeço nesta pedra. Acontece que qualquer versão do nginx antes 1.5.6 tem este problema: os certificados de mais de 4KB de tamanho incorrem em um ida e volta extra, transformando um handshake de duas idas e voltas em um caso de três idas e voltas – caramba. Pior, nesse caso particular, acionamos outro caso extremamente infeliz na pilha TCP do Windows: o cliente faz os ACKs dos primeiros pacotes do servidor, mas em seguida espera aproximadamente 200ms antes de desencadear um ACK atrasado para o último segmento. No total, isso resulta em 580ms extras de latência que não esperávamos.
Ok, vamos tentar a versão principal do nginx atual (1.5.7) e ver se ela sai melhor…

Muito melhor! Depois de um simples upgrade, o TLS TTFB abaixa para cerca de 2300ms, que é aproximadamente 600ms menor do que a nossa primeira tentativa: acabamos eliminado o RTT extra gerado pelo nginx e os 200ms atrasados de ACK no cliente. Dito isso, não estamos fora de perigo ainda – pois há um RTT extra lá.
Otimização do tamanho de registro TLS
O tamanho do registro TLS pode ter um impacto significativo sobre o desempenho do tempo de carregamento da página do seu aplicativo. Nesse caso, nos deparamos com esse problema de cabeçalho primeiro: o nginx injeta dados na camada TLS, que por sua vez cria um registro de 16 KB e, em seguida, passa para a pilha TCP. Até aí tudo bem, exceto que a janela de congestionamento do servidor é menor do que 16 KB para a nossa nova conexão, e nós transbordamos a janela, incorrendo em uma viagem extra, enquanto os dados são armazenados temporariamente no cliente. A solução desse problema requer a realização de um patch rápido para o código fonte do nginx :
diff nginx-1.5.7/src/event/ngx_event_openssl.c nginx-1.5.7-mtu/src/event/ngx_event_openssl.c 570c570 < (void) BIO_set_write_buffer_size(wbio, NGX_SSL_BUFSIZE); --- > (void) BIO_set_write_buffer_size(wbio, 16384); diff nginx-1.5.7/src/event/ngx_event_openssl.h nginx-1.5.7-mtu/src/event/ngx_event_openssl.h 107c107 < #define NGX_SSL_BUFSIZE 16384 --- > #define NGX_SSL_BUFSIZE 1400

Depois de aplicar a nossa mudança de duas linhas e recompilar o servidor, nosso TTFB abaixa para aproximadamente 1900ms – que resultam nos 5 RTTs que esperávamos no início. Na verdade, é fácil de detectar a diferença em relação à nossa execução anterior: o gráfico mostra agora o segundo RTT como o tempo de download de conteúdo (parte azul), enquanto anteriormente o navegador não conseguiu processar o documento HTML até o fim. Sucesso! Mas espere, e eu lhe dissesse que poderíamos fazer ainda melhor?
Ativação do TLS False Start
O TLS False Start nos permite eliminar uma viagem extra de latência dentro do handshake TLS: o cliente pode enviar os seus dados de aplicativos criptografados (ex.: requisição HTTP) imediatamente após ter enviado seus registros ChangeCipherSpec e Finished, sem esperar que o servidor confirme suas configurações. Então, como é que vamos habilitar o TLS False Start?
- O Chrome vai usar TLS False Start se detectar o suporte para negociação NPN e forward secrecy – o NPN é um recurso independente, mas a presença de suporte para NPN é usada para proteger contra implementações malfeitas.
- O Firefox ativou o TLS False Start várias vezes, mas ele vai ser (re)ativado no M28 e ele também exigirá um anúncio NPM e suporte para forward secrecy.
- IE10+ usa uma combinação de lista negra e timeout e não necessita de qualquer recurso TLS adicional.
- A Apple incluiu suporte ao TLS False Start no OSX 10.9, o que significa que esperamos que sua vinda para o Safari esteja próxima.
Em suma, precisamos habilitar NPN no servidor, o que na prática significa que precisamos recompilar o nginx com OpenSSL 1.0.1a ou superior – nada mais, nada menos. Vamos fazer exatamente isso e ver o que acontece…
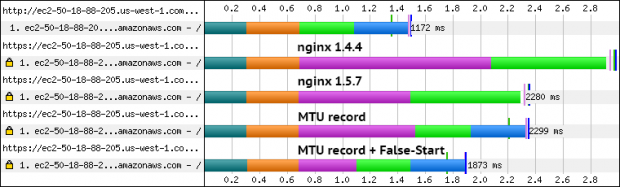
Começamos com um desperdício de aproximadamente 1800ms para nossa conexão TLS (quase 5 RTTs adicionais); eliminamos a viagem extra de ida e volta do certificado após a atualização do nginx; cortamos outro RTT, forçando um tamanho de registro menor; diminuímos um RTT extra do handshake TLS, graças ao TLS False Start. Com tudo dito e feito, nossa TTTFB fica abaixo de 1560ms , que é exatamente uma ida e volta a mais do que uma conexão HTTP normal. Agora, sim, estamos bem!
Sim, TLS adiciona latência e sobrecarga de processamento. Dito isso, o TLS é uma fronteira não otimizada, e podemos mitigar muitos dos seus custos – vale a pena! Nossa exploração rápida com o nginx é um exemplo disso, e a maioria dos outros servidores TLS tem os mesmos problemas que descrevemos acima. Vamos corrigir isso. O TLS não é lento, só não é otimizado.
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://www.igvita.com/2013/12/16/optimizing-nginx-tls-time-to-first-byte/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?