

Nesta coluna, já falamos sobre vários modelos de IA baseados em comportamentos biológicos e, na última edição, chegamos a demonstrar a aplicação de muitos deles em jogos eletrônicos. Hoje, a ideia é ir um pouco de machine learning (ML) e sua aplicação na indústria 4.0.
Primeiro, vamos observar alguns cenários nos quais conseguimos identificar a presença do ML. Nossa grande amiga Netflix é um exemplo. Com seus modelos de ML, ela consegue nos indicar filmes e séries dos quais podemos gostar, baseados naqueles a que já assistimos. A Amazon é outra grande utilizadora de ML – podemos ver isso nas indicações de livros, baseados em nossas compras, visitas, cliques, etc.
Mas o ML vai muito além de sugestões, e o que queremos trazer neste artigo é uma dessas outras aplicações. Acredito que uma das maiores aplicações de ML seja em análises preditivas, que se baseiam na possibilidade de prever um comportamento tendo como base comportamentos passados.
Mas antes de irmos para a aplicação, precisamos entender alguns algoritmos de ML. Temos basicamente três grandes grupos: aprendizagem supervisionada, semissupervisionada e nãosupervisionada. Abaixo seguem alguns exemplos de aprendizagem supervisionada e não supervisionada.
Aprendizagem supervisionada
Árvores de decisão
É um algoritmo baseado em um gráfico ou modelo de decisões. Em suma, ele permite que você tome uma decisão correta (mais assertiva) baseado em um conjunto mínimo de perguntas realizadas.
É comumente utilizado para resolver problemas complexos, decompondo-os em problemas menores. E esta técnica pode ser utilizada de maneira recursiva, ou seja, aplicar a decomposição em cada subproblema.
Em uma árvore de decisão, cada nó é responsável por um teste de atributo. Cada ramo descendente representa um possível valor do atributo, e cada percurso (raiz à folha) representa uma regra de classificação.
O algoritmo base de uma árvore de decisão consiste em:
- Identificar um atributo;
- Estender a árvore adicionando um ramo para cada valor do atributo;
- Passar os exemplos para as folhas, ou seja, levar em consideração o valor escolhido para cada atributo;
- Se todos os exemplos são da mesma classe, devemos associar essa classe à folha; caso contrário, devemos refazer os passos anteriores.
A ideia aqui não é aprofundar muito em cada algoritmo, e sim apresentá-lo. Caso você queira entender um pouco mais sobre árvores de decisão, recomendo que você estude um pouco mais, pois para desenvolver uma boa árvore de decisão, é preciso definir os critérios para a escolha do atributo, caracterizar as medidas de partição, entender como funciona a entropia para calcular a aleatoriedade de uma variável, critérios para fazer com que a árvore pare, entre outros.
Regressão linear de mínimos quadrados
Muito utilizado em estatística, este modelo consiste em traçar um comportamento comum até comportamentos aleatórios. Observando a imagem abaixo, podemos entender um pouco melhor.
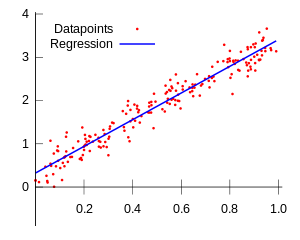
A estratégia mais comum para resolver esse problema é a de mínimos quadrados comuns. Para realizar essa tarefa, você desenha uma linha e, para cada um dos pontos de dados, mede a distância vertical entre o ponto e a linha. Depois disso, basta somá-los. A linha ajustada deve ser aquela em que essa soma de distâncias é a menor possível.
Aprendizagem não supervisionada
Algoritmos de agrupamento (clustering)
Basicamente, é reunir um conjunto de dados semelhantes em um mesmo grupo (cluster). Existem vários tipos de algoritmos de cluster:
- Baseado em Centroid;
- Baseado em conectividade;
- Baseado em densidade;
- Probabilístico;
- Redução de dimensionalidade;
- Redes neurais/deep learning.
Esses algoritmos de agrupamento são muito utilizados em bioinformática, por exemplo. No estudo do genoma, a análise de dados de expressão gênica tem utilizado técnicas de agrupamento para identificar possíveis grupos de genes.
Análise de componentes independentes (ICA)
É uma análise estatística que revela fatores ocultos presentes em conjuntos de variáveis aleatórias, medições ou sinais. Pense na ICA como um algoritmo capaz de gerar modelos para os dados multivariados observados (um banco de dados muito grande e com N tipos de dados). Neste modelo, as variáveis dos dados vão misturar lineares de variáveis latentes desconhecidas, assim como o sistema que misturou.
Este é um pouco confuso, mas vamos observar um exemplo para facilitar a nossa vida. Este tipo de algoritmo é comumente utilizado em um problema chamada “cocktail party” ou separação de sinais de áudio. Pense em duas pessoas em uma sala, as duas com um microfone de captação de áudio. Elas estão conversando. Os sensores precisam identificar e separar os áudios e dizer a qual pessoa eles pertencem. Ficou mais claro agora?
Além disso, podemos utilizar o ICA em imagens digitais, bancos de dados de documentos, indicadores econômicos e medições psicométricas.
Aplicação do ML na indústria
Imagine uma indústria com vários sensores instalados em todas as máquinas, gerando Teradados que alimentam uma rede de aprendizado de máquina na qual esses dados são analisados em tempo real, gerando insights sobre o funcionamento dela, desde quando uma determinada peça precisa ser substituída até em qual temperatura ela funciona sem que haja prejuízos físicos, entre outros fatores.
Atualmente, isso é possível, porém não é tão simples quanto parece. Tudo começa na linha de produção, na qual os dados são gerados e enviados para armazenamento. Esses dados, posteriormente, serão utilizados para treinar um modelo preditivo.
Para isso, é necessário que seja feita uma classificação desses dados. O processo de classificação varia de acordo com o problema que se deseja resolver. O método de classificação binária, por exemplo, é fundamentado nas árvores de decisão, sendo uma extensão dos modelos de regressão, mas não é restrito à classificação. Esse método é baseado na estratificação binária das covariáveis que levam à tomada de decisão. Este modelo estatístico pode ser utilizado em algoritmos de previsão, como indicar se uma máquina quebra ou não quando atingir determinada temperatura.
Outro modelo estatístico usado na criação de modelos preditivos de aprendizado de máquina é a classificação de classes. Aqui, os dados são agrupados por proximidade, e a frequência com que aparecem também é levada em consideração. É comumente utilizado para análises de dados subjetivos – na indústria, por exemplo, podemos enxergar isso como o desgaste de uma correia.
Após os dados serem coletados por meio dos sensores, armazenados e analisados por meio de modelos estatísticos e matemáticos, eles são enviados para a construção dos modelos de predição – leia-se: aprendizado de máquina.
Existem n frameworks e softwares que podem aplicar o ML para nós sem que tenhamos muito trabalho. Nesses programas, podemos simplesmente inserir nosso banco de dados, escolher o algoritmo e aplicar Paretto.
Porém, nós somos desenvolvedores de sistemas. Sendo assim, precisamos saber como aplicar esses algoritmos e entender qual é o melhor para cada situação. Precisamos colocar esse algoritmo funcionando dentro do nosso código.
E, pensando um pouco além do código, precisamos que nossa aplicação, nossa inteligência e nosso aprendizado de máquina sejam justos e éticos. Ou seja, precisamos ter cuidado com os dados inseridos no treinamento, pois, como já cansamos de ver, muitos programas desenvolvidos por nós acabam por se tornar, digamos, preconceituosos. Que tal pensarmos em ética no código?
***
Artigo publicado na revista iMasters, edição #25: https://issuu.com/imasters/docs/25

De 0 a 10, o quanto você recomendaria este artigo para um amigo?