



DDoS de aplicação em arquiteturas de microsserviço
Hoje você vai conhecer uma das formas mais devastadoras de causar instabilidade no serviço em modernas arquiteturas de microsserviços: DDoS de aplicação.

Hoje você vai conhecer uma das formas mais devastadoras de causar instabilidade no serviço em modernas arquiteturas de microsserviços: DDoS de aplicação. Um ataque desses especialmente criado pode causar falhas de sistema em cascata, muitas vezes por uma fração dos recursos necessários para realizar um ataque DDoS mais tradicional. Isso se deve às relações complexas e interconectadas entre aplicativos. Os ataques DDoS tradicionais se concentram em esgotar os recursos de sistema no nível da rede. Em contraste, os ataques da camada de aplicação se concentram em chamadas de API caras, usando suas complexas relações interconectadas para fazer com que o sistema ataque a si mesmo – às vezes com um efeito maciço.
Em uma moderna arquitetura de microsserviços, isso pode ser particularmente prejudicial. Um invasor sofisticado poderia criar solicitações maliciosas que modelam o tráfego legítimo e passam por proteções de borda, como um firewall de aplicativos da web (WAF).
Neste artigo, a Netflix discute um esforço que a empresa faz para identificar, testar e remediar os ataques DDoS da camada de aplicação. Para começar, um contexto sobre o espaço do problema. Em seguida, discute-se as ferramentas e os métodos utilizados para testar os sistemas. Em seguida, discute-se as etapas para tornar os sistemas mais resilientes contra os ataques DDoS da camada de aplicação.
História
De acordo com o Relatório do Estado de Segurança da Internet do primeiro trimestre de 2017, da Akamai, “menos de 1% de todos os ataques DDoS são camada de aplicação” ¹. No entanto, esta métrica sub-representa o impacto desses ataques. Quando um invasor usa o tempo para criar esse estilo de ataque, eles podem ser altamente eficazes. Tendo isso em mente, a defesa contra esses tipos de ataques pode ajudar a garantir que sua organização não tenha falhas em cascata se ocorrer um ataque DDoS na camada de aplicação.
Os ataques tradicionais DDoS da camada de aplicação focavam no trabalho do invasor para gerar uma entrada em comparação com o trabalho do sistema respondente para gerar a saída resultante. Ataques focavam em chamadas caras, como consultas de banco de dados ou I/O de disco pesado, com o objetivo de utilizar o aplicativo até que ele não pudesse mais atender usuários legítimos. À medida que as arquiteturas de aplicativos evoluíram para sistemas mais complexos e distribuídos, agora temos vetores adicionais para se concentrar em controles de saúde do serviço, enfileiramento/lotes e dependências complexas de microsserviço, que podem resultar em falhas de um serviço chave se tornar instável.
Microsserviços e DDoS
Em uma arquitetura moderna de microsserviços, a aplicação DDoS pode ser uma oportunidade particularmente efetiva para causar instabilidade no serviço. Para entender o porquê, considere uma arquitetura de microsserviços de amostra que usa um gateway para interagir com uma variedade de microsserviços de nível intermediário e backend, conforme descrito na figura abaixo.
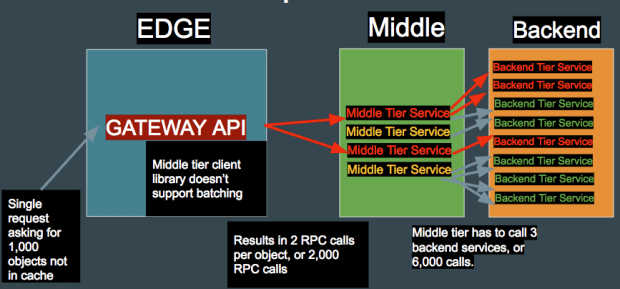
Este diagrama mostra como uma única solicitação na borda pode ser exibida em milhares de solicitações para os microsserviços de nível intermediário e backend. Se um invasor pode identificar chamadas de API que tenham esse efeito, talvez seja possível usar essa arquitetura de exibição contra ao serviço geral. Se os cálculos resultantes forem suficientemente caros, então alguns serviços de nível intermediário podem parar de funcionar. Dependendo da criticidade desses serviços, isso pode resultar em uma interrupção geral do serviço.
Tudo isso é possível porque a arquitetura de microsserviços ajuda o invasor ampliando massivamente o ataque contra sistemas internos. Em resumo, uma única solicitação em uma arquitetura de microsserviços pode gerar dezenas de milhares de chamadas de serviço complexas de nível intermediário e de backend.
Isso apresenta desafios únicos para os defensores. Se o seu ambiente se aproveitar de uma implementação comum de firewall de aplicativos da Web, onde o firewall está posicionado apenas nos sistemas de controle de internet (como o gateway da API), pode perder a oportunidade de bloquear solicitações que causam, especificamente, distúrbios aos serviços de níveis intermediários e de backend. Além disso, esse firewall talvez não saiba quanto trabalho uma solicitação para o gateway da API irá gerar para os serviços de nível intermediário e não pode desencadear uma lista negra até que o dano seja feito. Como defensores, é importante que entendamos como identificar essas chamadas de aplicativos vulneráveis ao caminhar através de um framework para o descoberta e validação.
Um framework para identificar e validar DDoS de aplicação
Intuitivamente, nosso objetivo como defensores é identificar quais chamadas de API podem ser vulneráveis a um DDoS. Estas são as chamadas que exigem recursos significativos dos serviços de nível intermediário e de backend. Contando o tempo que as chamadas de API levam para completar, é uma maneira de identificar essas chamadas. O modo mais básico e propenso a erros para fazer isso é tirar a impressão digital de chamadas de API a partir de um navegador da Web. Isso pode ser feito abrindo o console do Chrome Developer, selecionando a guia Rede, clicando no botão Preserve log e, em seguida, navegando para o site. Depois de algum período de tempo, classifique por Tempo e veja as chamadas mais latentes. Você receberá uma tela semelhante à imagem abaixo:
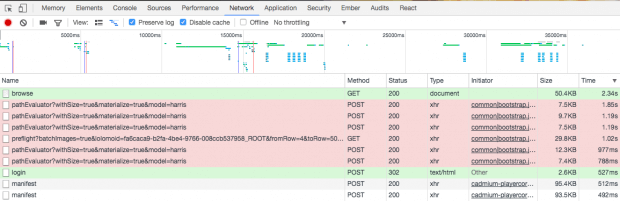
Esta técnica pode ter falsos positivos, incluindo chamadas que não podem ser modificadas para aumentar a latência. Além disso, você pode acabar perdendo chamadas que poderiam ser manipuladas para aumentar a latência. Uma melhor técnica para identificar chamadas latentes pode ser monitorar os tempos de solicitação para serviços de nível intermediário. Depois de encontrar um serviço de nível intermediário latente, você deve trabalhar na reconstrução de uma solicitação que poderia ser feita através do gateway da API, que invocaria o serviço de nível intermediário latente.
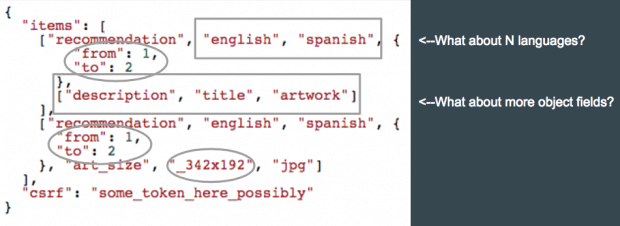
Depois de encontrar algumas chamadas de API interessantes, o próximo passo é inspecionar seu conteúdo. Seu objetivo nesta etapa deve ser encontrar maneiras de tornar as chamadas mais caras. Uma técnica para isso é aumentar o intervalo/gama dos objetos solicitados. Por exemplo, na imagem abaixo, os parâmetros de e para podem ser potencialmente modificados para aumentar a carga de trabalho em serviços de nível intermediário.

Escavando um pouco mais fundo, muitas vezes você pode modificar muitos elementos diferentes de uma solicitação para torná-la mais cara. A imagem abaixo mostra um exemplo em que você pode potencialmente modificar os campos de objeto solicitados, o intervalo e até mesmo o tamanho da imagem:
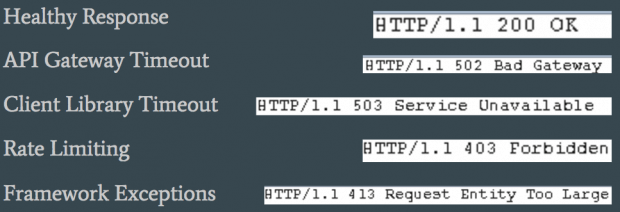
Você também deseja criar uma lista de indicadores sobre a saúde do seu teste. Isso irá informá-lo se o seu teste está funcionando e onde você precisará escalar o teste para cima ou para baixo. Normalmente, haverá diferentes códigos ou latências de status HTTP observados durante o teste, mas também haverá cabeçalhos específicos, texto de resposta, traços de pilha etc. A imagem abaixo mostra uma lista de indicadores de exemplo:
Outro indicador de sucesso de teste útil é a latência aumentada (como uma resposta HTTP 200 e uma resposta de 10 segundos). Você pode observar a latência durante o teste ou outros usuários navegando no aplicativo. Uma vez que você tenha uma boa compreensão dos tipos de solicitações que você pode enviar para gerar latência e de como medir os indicadores de sucesso, você precisará ajustar seu teste para operar sob um firewall de aplicativos da Web, se isso existir em seu ambiente.
O fluxo de tráfego ideal estará em algum lugar abaixo quando o firewall do aplicativo da Web começar a bloquear, mas alto o suficiente para que o número de solicitações e o trabalho por solicitação causem instabilidade no serviço.
Grizzly repulsivo

Para ajudar a facilitar este teste em uma escala menor, você pode usar o framework Grizzly Repulsivo. A Netflix está lançando este framework através do programa de código aberto skunkworks, o que significa que a empresa está compartilhando isso como prova de conceito, mas não anteciparam a manutenção desta base de código a longo prazo. Este framework está escrito em Python e alavanca o evento para uma alta concorrência. Também suporta a capacidade de round-robin objetos de autenticação, que podem ser uma técnica eficaz para ignorar determinados firewalls de aplicativos da Web.
O Grizzly Repulsivo não ajuda na identificação de vulnerabilidades DDoS do aplicativo. Tal como acontece com todas as ferramentas de teste de segurança, é importante utilizar isso apenas em sistemas onde você está autorizado a realizar esse teste. Nesses sistemas, primeiro você precisará identificar possíveis problemas como o descrito acima. Depois de ter alguns problemas potenciais para testar, o Grizzly Repulsivo irá simplificar o processo de teste.
Para obter detalhes sobre como usar o framework Grizzly Repulsivo, consulte a página Github do projeto para obter a documentação.
Kraken Nublado
Depois de testar sua hipótese em uma escala menor, você pode aproveitar o Kraken Nublado para escalar seu teste. Ele é um framework de orquestração AWS, especificamente centrado em ajudá-lo a testar seus aplicativos em uma escala global. Semelhante ao framework Grizzly Repulsivo, a Netflix está liberando Kraken Nublado como um projeto de código aberto do skunkworks.
Kraken Nublado ajuda a manter uma frota global de instâncias de teste e os testes Grizzly Repulsivo que são executados nessas instâncias. Ele também constrói e distribui a configuração de teste e alavanca os drivers de rede aprimorados do AWS EC2. O Kraken Nublado também pode escalar o teste em várias regiões e fornece sincronização de tempo para que seus agentes de teste funcionem em paralelo. O diagrama abaixo fornece uma visão geral de alto nível do Kraken Nublado.
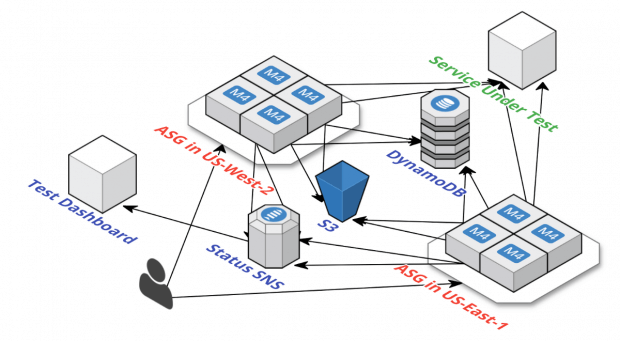
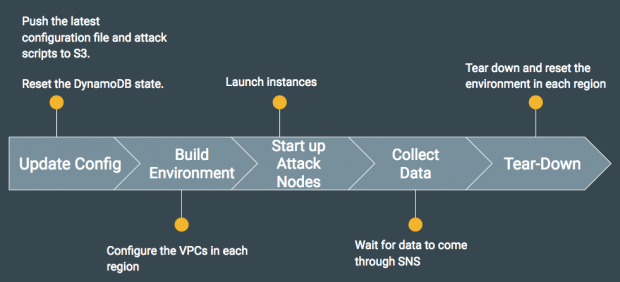
Kraken Nublado orquestra seus testes de forma amigável para desenvolvedores. Isso começa com alguns scripts de configuração que definem o teste. Cloud Kraken criará, então, o ambiente AWS para o teste e iniciará as instâncias. Enquanto o teste está em andamento, o Kraken Nublado irá coletar dados usando AWS SNS. Finalmente, os recursos da AWS são destruídos na conclusão do teste. Essas etapas são mostradas no diagrama abaixo:
Um estudo de caso Netflix
Na Netflix, o desejo era testar as descobertas da equipe em relação a uma determinada chamada de API que foi identificada como latente. Durante um exercício do Chaos Kong (onde a Netflix evacua toda uma região da AWS enquanto redireciona graciosamente o tráfego do cliente para outras regiões), testava-se o ambiente de escala de produção na região evacuada. Isso proporcionou a rara oportunidade de testar um cenário de DDoS de aplicação de camada contra um ambiente de escala de produção sem qualquer impacto no cliente. A cultura única da empresa encoraja a equipe a fazer o que é melhor para a empresa e seus clientes, e abraçamos essa liberdade para executar o teste na produção para realmente entender o impacto.
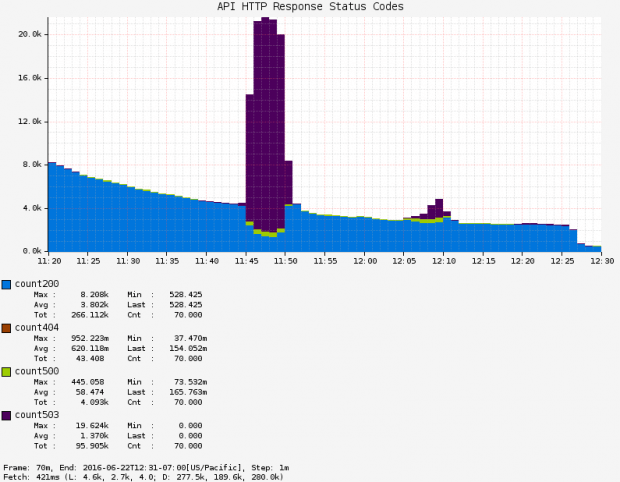
O teste realizado conduziu a dois ataques diferentes em dois períodos de 5 minutos. Os resultados dos testes confirmaram a teoria da equipe e resultaram em uma taxa de erro de gateway API de 80% para a região específica que era tida como alvo. Ao testar usuários que estavam fazendo solicitações contra esse gateway da API, observou-se erros no site ou outras exceções que impediam o uso do site. O gráfico abaixo mostra dois picos em códigos de status HTTP 503 (representados em roxo), que estão correlacionados com a saúde do gateway da API:
Defesa contra ataques de DDoS de aplicação
A melhor defesa para os ataques DDoS da camada de aplicação vem de uma coleção de controles de segurança e melhores práticas.
Antes de mais nada, é fundamental conhecer o seu sistema. Você deve entender quais microsserviços afetam cada aspecto da experiência do cliente. Procure maneiras de reduzir interdependências nesses serviços. Se um serviço se tornar instável, o resto dos seus microsserviços deve continuar a operar, talvez em um estado degradado.
É importante ter uma boa compreensão das suas filas de serviços e solicitações de serviço. Pode ser possível que seus serviços de nível intermediário e backend limitem o lote ou o tamanho do objeto solicitado. Isso também pode ser feito no código do cliente e potencialmente aplicado no gateway da API. Colocar um limite no trabalho permitido por solicitação pode reduzir significativamente a probabilidade de exploração.
Também recomendamos ativar um loop de feedback para fornecer alertas dos serviços de nível intermediário e de backend para seu WAF. Isso ajudará o WAF a saber quando bloquear esses ataques. Em muitas implementações, o WAF está apenas monitorando a borda e pode não perceber o impacto de uma única solicitação para o gateway da API. Um WAF também deve monitorar o volume de falhas de cache. Se um gateway da API estiver executando constantemente chamadas de serviço de nível intermediário devido a perdas de cache, isso sugere que o cache não está configurado corretamente ou que seja um comportamento malicioso potencial.
Os gateways de API e outros microsserviços devem priorizar o tráfego autenticado em relação ao tráfego não autenticado. Custa mais ao invasor usar sessões autenticadas. Isso também pode ajudar a mitigar o impacto de um evento DDoS de camada de aplicação em seus clientes.
Finalmente, assegure-se de ter razoáveis tempos de espera da biblioteca do cliente e interruptores. Com tempos de espera razoáveis – e muitos testes – você pode proteger seus serviços de nível intermediário dos ataques DDoS da camada de aplicação.
Referências
- Grizzly Repulsivo
- Kraken Nublado
- Canal Youtube do Netflix Security
Notas de rodapé
- “Relatório do Estado de Segurança da Internet da Akamai”. https://www.akamai.com. N.p., 19 de fevereiro de 2017. Web.
***
Fonte: https://medium.com/netflix-techblog/starting-the-avalanche-640e69b14a06
Alex Lattaro é Mestre em Inteligência Artificial pela Unicamp e tecnólogo em Análise e Desenvolvimento de Sistemas pelo IFSP. Já trabalhou como líder de conteúdo no Imasters e na Microsoft, foi Especialista em Ciência de Dados na Kroton, Ilumeo e Santander e também atuou como professor no Samsung Ocean na Unicamp, ministrando aulas de Python, Ciência de Dados e Inteligência Artificial. Atualmente trabalha como especialista de projetos na Facti.



