



Criptografia Dinâmica como uma medida anti cópia

O código fonte para este artigo pode ser encontrado aqui.
Muita coisa tem sido falada e escrita sobre como os fornecedores de software não protegem os seus produtos, então vou pular essa parte. Ao invés disso, neste artigo, gostaria de me concentrar nas etapas relativamente simples, que os fornecedores de software precisam seguir a fim de reforçar a sua proteção (usar empacotadoress e protetores é bom, mas certamente não é o bastante), não permitindo que o código inteiro apareça na memória de forma legível por um único momento.
Vetores de ataque
Antes de lidar com “por que os invasores são capazes de x, y, z”, vamos mapear os vetores de ataque mais comuns em ordem ascendente de sua complexidade.
- Análise Estática – inspecionar um executável em seu disassembler favorito. Pode ser difícil de acreditar, mas a maioria dos produtos de software lá fora é vulnerável à análise estática, mostrando-nos, assim, que a maioria dos vendedores não se preocupa com a segurança dos algoritmos próprios, além do fato de que eles parecem não se preocupar com pirataria também (mas eles tendem a chorar por isso o tempo todo);
- Análise Dinâmica – executar um executável dentro de seu depurador favorito. Esta é uma consequência direta do parágrafo anterior. Se um invasor é capaz de ver todo o código no disassembler – el definitivamente pode executá-lo em um depurador (mesmo que isso implique em uma correção menor);
- Patching Static – isso significa alterar o código localizado no arquivo do executável. Pode ser mudando um obstáculo ou adicionando algumas dezenas de bytes do próprio código invasor, a fim de alterar a maneira como o programa é executado;
- Patching Dinâmico – semelhante à correção estática na ideia por trás do método. A única diferença é que o patching dinâmico é realizado enquanto o alvo executável é carregado na memória.
- Dumping – salvar os dados na memória para um arquivo no disco. Este método pode ser muito útil quando se examina um arquivo executável compactado. Tais depósitos de memória podem ser facilmente carregados em IDA e examinados como se possuíssem um executável regular (algumas ações adicionais podem ser necessárias para uma melhor conveniência, como refazer a base do programa ou ajustar as referências a outros módulos).
Na maioria dos casos, pelo menos, dois dos vetores acima estariam presentes no tempo de ataque.
Packers e Crypters
Usar diferentes packers, crypters e protectors é uma prática bastante conhecida entre os fornecedores de software. O problema disso é que alguns deles vão além de empacotar o código no arquivo e descompactá-lo totalmente na memória e, às vezes, protege o próprio packer. Quando falo “ir além”, quero dizer qualquer implementação de métodos anti depuração e de qualquer tipo. Além disso, esses utilitários não impedem que um invasor obtenha uma cópia de memória o suficiente para lidar com eles. Um ou dois verificam a consistência do código, que permite (sim – permite, uma vez que não necessariamente consegue) evitar corrigir o código, mas cada parede possui uma porta e o que importaé o tamanho do esforço necessário para abrir essa porta. A linha inferior é que estes tipos de proteção podem apenas ser úteis na prevenção de análise estática, mas só se não houver nenhum unpacker relevante ou decrypter.
Protectors
Este é “o próximo passo” na evolução dos packers. Eles fornecem um pouco mais de opções e ferramentas para estimar o quão seguro o ambiente é. Além de empacotar o código, eles também utilizam a verificação de consistência do código, truques anti debugging, verificação de licença, etc. Os protectors são boas contramedidas para os três primeiros vetores (ou mesmo os quatro primeiros) de ataque. No entanto, mesmo se um determinado protector tenha algumas heurística anti conserto, só é bom desde que ela (a heurística) não seja invertida, nem consertada.
Apesar de todos os “prós” no protectors, até mesmo essas poderosas ferramentas não são capazes de fazer muito para impedir que um invasor obtenha um despejo de memória, que pode ser obtido pelo uso do ReadProcessMemory ou pela injeção de uma DLL e despejo “de dentro”, enquanto suspende todos os outros segmentos.
Mais alguma coisa? Bem, sim! Existem algumas proteções básicas fornecidas pelo sistema operacional, como a separação de sessão, por exemplo, que impede a criação de tópicos remotos (usado com injeção de DLL), mas esses nem valem a pena mencionar aqui.
O imagem desenhada aqui parece ser triste e sem esperança o suficiente. No entanto, existem vários bons métodos para adicionar mais proteção a um produto de software e mais dor em algumas partes do corpo dos invasores.
Ofuscação de código
Embora este método seja amplamente utilizado por protectors e, às vezes, por packers e crypters (infelizmente, na maioria dos casos, só para se protegerem), ele parece ser quase totalmente desconhecido para o resto dos fornecedores de software. Em minha opinião, fazer um branch no código mais do que é normalmente necessário não pode ser considerado como ofuscação de código. Ele pode, sim, ser chamado de uma tentativa de ofuscar um algoritmo. A situação é tal, que mesmo a implementação de algo semelhante a isto seria uma melhoria significativa nos esforços dos fornecedores para proteger seus produtos.
Escondendo o código
Os fornecedores de software falham repetidamente em compreender dois fatos: meios populares mais vulneráveis (no que diz respeito de soluções comerciais) e o fato de que não há nenhuma cura mágica e eles têm que por algum esforço adicional para proteger os seus produtos.
Uma das opções que eu gostaria de abordar aqui é a criptografia dinâmica de código executável. Este método promete que apenas certas partes do código estariam presentes na memória de forma legível (possível desmontar), enquanto o resto do código (e de preferência, dos dados) é codificado.
Eu ainda acho que a melhor forma de explicar uma coisa é por meio de exemplos. O pequeno pedaço de código C descrito abaixo visa mostrar o princípio de criptografia de código dinâmico. Ele contém diversas funções, além da principal – o primeiro é o qual (o alvo) que vamos proteger. Ele não faz nada de especial, apenas calcula o fatorial de 10 e o imprime. A principal função invoca um decrypter (a fim de decifrar o alvo), chama ele (assim, exibindo o fatorial de 10) e, finalmente invoca o crypter para criptografar o alvo de volta (esconder).
O código pode ser compilado tanto para o Linux (usando o gcc) ou Windows (usando mingw32). Ele usa código de ofuscação daqui.
Função-alvo
Nossa função-alvo é bastante simples (só calcula o fatorial de número codificado):
void func()
{
__asm__ __volatile__("enc_start:");
{ /* Braces are used here as we do not want IDA to track parameters */
int i, f = 10;
for( i = 9; i > 0; i--)
f *= i;
printf("10! = %d\n\n", f);
}
__asm__ __volatile__("enc_end:");
}
Você reparou nas etiquetas no início e no fim do corpo da função? Elas são utilizadas apenas para obter o endereço de início da região a ser decifrada/ criptografada e calcular o seu tamanho. Devido ao fato que estes rótulos não são processados pelo pré-processador C, mas são passados para montador, eles são acessíveis a partir de outras funções, por padrão. O resto do código é delimitado por chaves, a fim de colocar todas as ações relacionadas com variáveis i e f na parte criptografada da função. Antes de ser decifrado, fica menos assim:
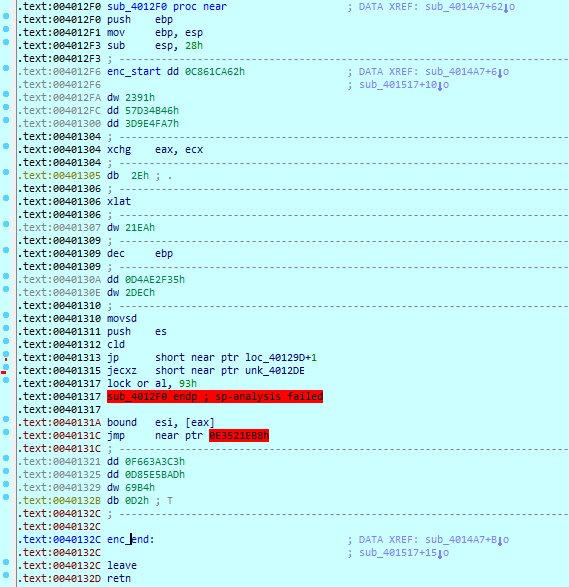
Embora no código anexado a criptografia inicial é realizada após o início do programa, na realidade, isso deve ser feito com uma ferramenta de terceiros (provavelmente). Você só teria que colocar uma marcação única no início e no fim da região que você deseja criptografar. Por exemplo:
__asm__(".byte 0x0D, 0xF0, 0xAD, 0xDE");
void func()
{
...
}
__asm__(".byte 0xAD, 0xDE, 0xAD, 0xDE");
Algoritmo de criptografia
A seleção do algoritmo de criptografia depende totalmente de você. Neste caso em particular, o algoritmo é bastante primitivo (ele não requer nem mesmo uma chave):
b - byte i - position for i = 0; i < length; i++ b(i+1) = b(i+1) xor (b(i) rol 1) b(0) = b(0) xor (b(length) rol 1)
Fluxo de execução
Então, vamos supor que o programa começou com a função já criptografada. Como este é apenas um exemplo, podemos chegar ao ponto imediatamente:
int main()
{
unsigned int addr, len;
__asm__ __volatile__("movl $enc_start, %0\n\t"\
"movl $enc_end, %1\n\t"\
: "=r"(addr), "=r"(len));
len -= addr;
decode(addr, len);
func();
encode(addr, len);
return 0;
}
O código acima é bastante auto-explicativo. Existem, no entanto, algumas coisas que preciso mencionar. Com funções de decodificar e codificar devemos tomar o cuidado de modificar os direitos de acesso à região de memória na qual vão operar. O seguinte código pode ser utilizado:
#ifdef WIN32
#include
#define SETRWX(addr, len) {\
DWORD attr;\
VirtualProtect((LPVOID)((addr) &~ 0xFFF),\
(len) + ((addr) - ((addr) &~ 0xFFF)),\
PAGE_EXECUTE_READWRITE,\
&attr);\
}
#define SETROX(addr, len) {\
DWORD attr;\
VirtualProtect((LPVOID)((addr) &~ 0xFFF),\
(len) + ((addr) - ((addr) &~ 0xFFF)),\
PAGE_EXECUTE_READ,\
&attr);\
}
#else
#include <sys/mman.h>
#define SETRWX(addr, len) mprotect((void*)((addr) &~ 0xFFF),\
(len) + ((addr) - ((addr) &~ 0xFFF)),\
PROT_READ | PROT_EXEC | PROT_WRITE)
#define SETROX(addr, len) mprotect((void*)((addr) &~ 0xFFF),\
(len) + ((addr) - ((addr) &~ 0xFFF)),\
PROT_READ | PROT_EXEC)
#endif
Este é o único código dependente de plataforma nesta amostra.
Linha inferior
O exemplo dado acima é realmente simples. As coisas seriam, pelo menos, um pouco mais complicadas na vida real. Enquanto aqui tem apenas uma função criptografada, imagine que existam várias funções criptografadas. Algumas delas são criptografadas sem chaves (como a citada acima), outras requerem chaves de complexidades diferentes. Várias teclas podem ser codificadas (para aquelas partes que foram criptografadas, a fim de chamar a atenção do invasor longe da coisa “real”), outros devem ser computados na mosca.
Exemplo: a função A é criptografada sem uma chave. Quando descodificada, ela executa várias operações e descodifica a função B, a qual, por sua vez criptografa a função A de volta e calcula uma chave para a função C, com base no teor binário da função A (ou A e B para evitar pontos de interrupção) ou mesmo com base em algum outro código no local independente.
Claro, não existe uma proteção inquebrável. Mas o tempo que leva para quebrar determinada proteção faz a diferença. Uma empresa que produz um software que é rompido no dia seguinte pode dificilmente beneficiar quase todo o trabalho pesado. Por outro lado, é totalmente possível criar esquemas de proteção que exigiriam meses para serem quebrados.
Vou tentar abranger possibilidades suplementares e os aspectos de proteção de software em meus artigos futuros, na esperança de, pelo menos tentar, mudar a situação.
Espero que este artigo tenha sido útil. Vejo vocês na próxima!
***
Artigo original disponível em: http://syprog.blogspot.com.br/2012/03/dynamic-code-encryption-as-anti-dump.html
trabalha com engenharia reversa e consultoria em anti-pirataria na Irdeto USA. Já trabalhou com detecção de malware, pesquisa de vírus e como engenheiro de suporte para cliente. Gosta de C, Assembler, Programação de Sistemas e Engenharia Reversa. É israelita e mora em Moscou.



