



Configurando ELK com Docker e Filebeat
O ELK tomou espaço muito rapidamente no mundo dos logs e das métricas, principalmente por ser open-source e altamente escalável.

O ELK (Elasticsearch, Logstash e Kibana) tomou espaço muito rapidamente no mundo dos logs e das métricas, principalmente por ser open-source e altamente escalável. Mesmo com tamanha adoção, esta stack não é simples de configurar, muito pelo contrário, ela exige um bom conhecimento de cada um dos membros que formam o trio ELK.
Neste artigo, a orquestração dos serviços será feita usando o docker-compose na versão 2, que dispensa o uso de links para rede entre os serviços e cada um rodará em um container Docker. Todos os arquivos estão disponíveis neste repositório, basta clonar e seguir os passos abaixo.
Iniciando o ELK
No arquivo docker-compose.yml está toda a configuração do docker-compose para orquestrar o ELK e o Filebeat (que vou explicar na sequência).
O primeiro serviço a ser configurado é o Elasticsearch, o servidor de busca distribuído que irá armazenar os logs. A imagem utilizada está na versão 2.3.
elasticsearch:
image: elasticsearch:2.3.3
command: elasticsearch -Des.network.host=0.0.0.0
O segundo serviço é o Kibana, que permite a criação de visualizações e dashboards baseadas em buscas realizadas no elasticsearch. Na configuração abaixo, além de expor a porta 5601 para que a interface web fique acessível, também é configurada a dependência do container do elasticsearch com o parâmetro depends_on, que informa ao docker-compose que o container do elasticsearch deve ser iniciado primeiro.
kibana:
image: kibana:4.5.1
ports:
- "5601:5601"
depends_on:
- elasticsearch
O terceiro serviço é o Logstash que é o responsável por parsear os logs e enviar para o elasticsearch. Para que seja possível alterar as configurações do logstash na hora de iniciar o container, foi utilizado o parâmetro volumes do docker-compose, que permite sincronizar diretórios da maquina host com o container. O parâmetro command informa para o logstash qual arquivo de configuração ele deve carregar, ou seja, o arquivo que foi sincronizado para dentro do container.
logstash:
image: logstash:2.3.2
command: logstash -f /etc/logstash/conf.d/logstash.conf
volumes:
- ./logstash:/etc/logstash/conf.d
- ./logstash/patterns:/opt/logstash/patterns
depends_on:
- elasticsearch
O ultimo serviço é o Filebeat, que é responsável por ler os arquivos de log e enviar para o logstash. Na configuração dele, além de sincronizar a configuração também é sincronizado o diretório de logs “../fake-logs:/var/log” que, neste caso, deve ser alterado para o caminho de onde estão os logs que devem ser parseados.
filebeat:
image: prima/filebeat
volumes:
- ./filebeat/filebeat.yml:/filebeat.yml
- ../fake-logs:/var/log
depends_on:
- logstash
Configurando o Filebeat
O filebeat remove a necessidade do logstash de ler arquivos diretamente do disco. Esse comportamento é similar a produção, quando não é possível ter acesso ao disco de um servidor para ler os logs, desta maneira os logs serão enviados para o logstash através de uma determinada porta. Dentro de “./filebeat” está o arquivo de configuração filebeat.yml responsável por toda a configuração da leitura de logs.
filebeat:
prospectors:
-
paths:
- /var/log/nginx/vs_access.log
input_type: log
document_type: nginx_access
scan_frequency: 10s
-
paths:
- /var/log/error.log
input_type: log
document_type: app_error
scan_frequency: 10s
output:
logstash:
hosts: ["logstash:5044"]
logging:
files:
rotateeverybytes: 10485760 # = 10MB
selectors: ["*"]
level: warning
Prospectors são um ou mais paths de arquivos que o filebeat ficará acompanhando em busca de mudanças para enviar para o logstash. Cada paths possui parâmetros adicionais, como o document_type, que é referente ao type do elasticsearch onde o log sera salvo.
O output foi configurado para o logstash usando o host “logstash:5044″ referente ao containerdocker com o nome de logstash.
Mais opções de configurações para o filebeat podem ser encontradas aqui.
Configurando o Logstash
Agora que o filebeat já está configurado e pronto para enviar logs para a porta 5044 do logstash, o mesmo deve estar pronto para receber e parsear esses dados e também enviá-los para o elasticsearch depois de parseados.
O arquivo “logstash.conf” dentro de “./logstash” vai ficar assim:
input {
beats {
port => 5044
}
}
filter {
if [type] == "nginx_access" {
grok {
patterns_dir => "./patterns"
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
}
output {
elasticsearch {
hosts => "elasticsearch"
}
}
O logstash consiste em três etapas: Input (onde os dados entram), Filter (onde são parseados) e o utput (saída). O input acima esta configurado para o filebeat na porta 5044, tudo que for recebido nesta porta sera tratado como algo enviado pelo filebeat.
Na etapa de filter, é realizado um teste que verifica se os dados fazem parte do type nginx_access, em caso positivo, é usado o plugin grok que permite realizar expressões regulares nos logs.
COMBINEDAPACHELOG é um grupo de expressões regulares que consegue fazer parse das linhas de log do arquivo nginx_access para descobrir qual tipo de parser consegue parsear uma determinada linha de log foi usado o grok debugger.
O output será feito apenas para o elasticsearch. No hosts foi passado apenas o nome do containerja que o tutorial usa docker.
Iniciando o docker compose
Para iniciar os serviços, basta rodar o comando “docker-compose up” no mesmo diretório onde está o arquivo docker-compose.yml. O kibana estará disponível na porta 5601:
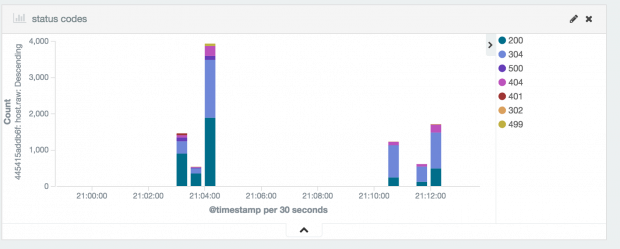
Exemplo de dashboard com visualization agrupando as requisições por status code.
O intuito de escrever este artigo foi para introduzir a configuração. O vídeo a seguir repassa esses pontos e fala sobre como criar dashboards e vistualizations no kibana.
Até o próximo galera, valeu!
Dev na carteira e no coração, com um certo apego em web. Moro em Pelotas (RS) e por esses lados, e para onde me chamarem, palestro e ministro workshops. Open-source is my religion!



