



A anatomia de um desastre de senhas – o gigantesco erro da Adobe em criptografia
Uma análise sobre a falha de segurança da Adobe, que expôs dados de 38 milhões de usuários.

Em outubro, escrevi sobre a enorme falha de segurança da Adobe. Até onde se sabe, incluindo a Adobe, a falha afetou três milhões de registros de clientes, o que fez a coisa parecer ruim desde o início.
Mas o pior estava por vir, já que atualizações recentes fizeram o número subir para alarmantes 38 milhões.
Nós culpamos a Adobe pela falta de clareza na notificação da violação de segurança.
Nossa reclamação
Uma de nossas queixas foi de que a Adobe disse que eles haviam perdido senhas criptografadas, quando pensamos que a empresa tivesse dito que havia perdido senhas em hashes com saltos.
Conforme explicamos na época:
As senhas provavelmente não estavam criptografadas, o que implicaria na Adobe poder descriptografá-las e então saber qual senha você escolheu.
As normas atuais para armazenamento de senhas usam uma função matemática de mão única chamada de hash que […] depende unicamente da senha. […] Isso significa que você na verdade nunca armazena a senha, criptografada ou não.
[…e] você normalmente acrescenta alguns saltos: uma string aleatória que você armazena com o ID do usuário e mistura a senha no momento de computar o hash. Mesmo que dois usuários escolham a mesma senha, seus saltos serão diferentes e resultarão em hashes diferentes, o que torna as coisas muito mais difíceis para invasores.
Parece que entendemos tudo errado, em mais de um ponto. Aqui explicamos o que e por quê.
A violação dos dados
Um enorme dump da base de usuários foi recentemente publicado online, tendo 4GB comprimidos, ou apenas pouco menos de 10GB sem compressão, listando não apenas 38 bilhões de registros violados, mas 150 bilhões deles.
Na medida em que as violações acontecem, você talvez a veja no livro de Recordes do Guinness no ano que vem, pois ela pode se tornar suficientemente chocante por si só.
Mas há mais.
Utilizamos uma amostra de um milhão de itens do dump publicado para ajudá-lo a entender melhor. Nossa amostra não foi selecionada exclusivamente de forma aleatória. Pegamos todos os décimos registros dos primeiros 300MB dos dados comprimidos até que tivéssemos um milhão de registros. Achamos que isso forneceria uma amostra representativa sem que precisássemos passar por todos os 150 milhões de registros.
O dump se parece com isto:

Inspecionando, os campos são os seguintes:
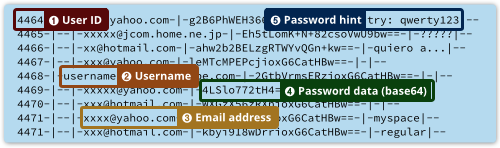
Menos de 1 em 10 mil entradas possui um username – aquelas que possuem são quase que exclusivamente limitadas às contas da adobe.com e stream.com (uma empresa de web analytics).
Os IDs dos usuários, os endereços de e-mail e usernames eram desnecessários para nosso propósito, então os ignoramos e simplificamos os dados conforme exibido abaixo.
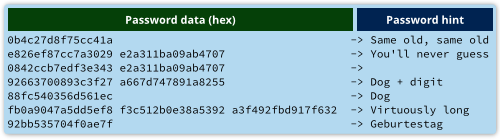
Mantivemos as dicas das senhas, porque elas foram úteis, e convertemos os dados das senhas da base64 para hexadecimal, tornando o tamanho de cada entrada mais óbvia, desta forma:
Criptografia versus hashing
A primeira pergunta é “a Adobe estava dizendo a verdade, ao afirmar que as senhas estavam criptografadas e não em foma de hash?”
Lembre-se de que hashes produzem uma quantidade fixa de output, sem levar em consideração a quantidade de dados inseridos, portanto, a tabela com o comprimento dos dados sugere fortemente que eles não estavam no formato de hash:

Os dados das senhas certamente parecem pseudoaleatórios, apesar de terem sido embaralhados de alguma forma e uma vez que a Adobe oficialmente disse que eles estavam criptografados e não em forma de hash, devemos considerar essa afirmação como verdade.
O algoritmo de criptografia
A próxima pergunta é “qual algoritmo de criptografia?”
Podemos descartar cifras de stream tal como RC4 ou Salsa-20, nas quais strings criptografadas possuem o mesmo tamanho do texto original.
Cifras de stream são comuns em protocolos de rede, pois você pode criptografar um byte de cada vez, sem ter que acompanhar o tamanho do seu input em um número múltiplo ou fixo de bytes.
Com quase todos os dados possuindo um comprimento de múltiplos de oito, estamos praticamente diante de uma cifra de bloco que funciona a cada oito bytes (64bits).
Isso, por sua vez, sugere que estamos nos deparando com o DES, ou seu derivado mais moderno e resiliente, o Triple DES, geralmente abreviado para 3DES.
Outras cifras de bloco de 64 bits, como o IDEA, já foram comuns, e a besteira que estamos prestes a revelar certamente não descarta uma cifra “caseira” inventada pela própria Adobe. Mas DES ou 3DES são as suspeitas mais prováveis.
O uso de cifras simétricas aqui, assumindo que estamos certos, é um erro crasso espantoso, não apenas por ser desnecessário, mas por ser também perigoso.
Qualquer um que compute, adivinhe ou adquira a chave de descriptografia, imediatamente ganha acesso a todas as senhas na base de dados.
Por outro lado, um hash criptográfico protegeria cada senha individualmente, sem uma “chave mestre” para todas as portas, o que desembaralharia todas as senhas de uma vez – essa que é a razão pela qual os sistemas UNIX têm armazenado senhas dessa forma com sucesso por cerca de 40 anos.
O modo de criptografia
Agora precisamos nos perguntar: “que modo de cifragem foi utilizado?”
Há dois modos em que estamos interessados: no modo de cifragem de bloco bruto, conhecido como Eletronic Code Book (ECB), no qual padrões do texto original são revelados no texto cifrado; e em todos os outros, que mascaram padrões de input mesmo quando os mesmos dados são criptografados com a mesma chave.
A razão para o ECB nunca ser utilizado para outra coisa além de servir de base para modos de criptografia mais complexos é que o mesmo bloco de input criptografado com a mesma chave resulta sempre no mesmo output.
Até repetições que não estão alinhadas com o tamanho do bloco conservam padrões impressionantemente reconhecíveis, como demonstra a imagem abaixo.
Pegamos uma imagem RGB do logo da Sophos, na qual cada pixel (a maior parte dos quais é algum tipo de branco ou algum tipo de azul) toma três bytes, divididos em blocos de 8 bytes e criptografamos cada um usando DES no modo ECB.
Tratando o arquivo de saída como outra imagem RGB resulta em quase nenhum disfarce:

Modos de cifragem que disfarçam padrões do texto original necessitam de mais do que uma chave para começar – eles precisam de um vetor de inicialização único ou “nonce” (number used once, ou número utilizado uma vez), para cara item criptografado.
O nonce é combinado com a chave e o texto original de forma que o mesmo input resulta em diferentes resultados de output a cada vez.
Se o comprimento mais curto dos dados de senhas tenha sido, digamos, 16 bytes, uma boa suposição seria que cada dado de senha contivesse um nonce de 8 bytes e então no mínimo um bloco válido – outros oito bytes – de dados criptografados.
Como o menor data blob de senha tem exatamente um bloco de comprimento, não deixar espaço para um nonce claramente não vai funcionar.
Talvez a criptografia utilizou o User ID de cada entrada, o que podemos assumir como único, como um nonce contra-tipo?
Mas podemos rapidamente dizer que a Adobe não fez isso ao olhar para os padrões do texto que se repetem nos trechos criptografados.
Por haver 264 – perto de 20 milhões milhões milhões – possíveis valores de 64 bits para cada bloco cifrado, devíamos esperar nenhuma repetição nos 1 milhão de registros de nossa amostragem.Mas não foi isso que encontramos, já que a contagem de repetições revelou o seguinte:

Lembre-se de que se o modo ECB não foi utilizado, cada bloco apareceria apenas uma vez a cada 264 vezes, para uma minúscula prevalência de aproximadamente 5 x 10-18%.
Recuperação de senha
Agora vamos ao trabalho, “Qual é a senha que é criptografada como 110edf2294fb8bf4 e outras repetições comuns?”
Se o passado, com outras coisas iguais, é o melhor indicador do presente, talvez também possamos começar com alguma estatística de invasões anteriores.
Quando a Gawker Media foi hackeada três anos atrás, por exemplo, as principais senhas que foram extraídas dos hashes roubados foram:
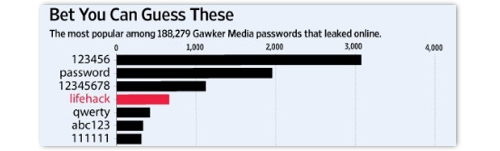
(A palavra lifehack é um caso especial aqui – já que Lifehacker é uma das marcas da Gawker – sendo as outras facilmente digitadas e escolhidas com frequência, resultando em senhas muito fracas.)
Os dados anteriores combinados com as dicas das senhas vazadas pela Adobe tornam a criação de uma tabela de semelhanças algo bastante fácil.
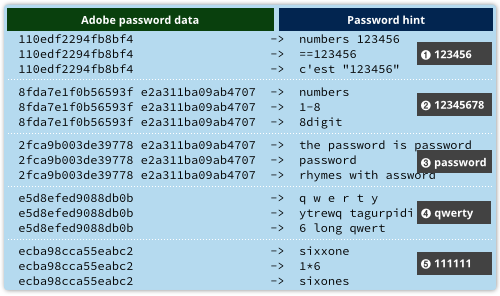
Note que os 8 caracteres da senha 12345678 e password são normalmente criptografados em 16 bytes, denotando que o texto original possuía pelo menos 9 bytes.
Uma explicação muito provável para isso é que o texto de input consistia em: senha, seguido do byte zero (ASCII NUL), usado para denotar o fim de uma string em C, seguido por 7 bytes NUL para preencher o input para múltiplos de 8 bytes de forma a igualar o tamanho dos blocos de criptografia.
Em outras palavras, estamos em um terreno seguro caso possamos inferir que e2a311ba09ab4707 é o texto cifrado que sinaliza um bloco de entrada de oito bytes zero.
Esses dados são mostrados no segundo bloco criptografado em alarmantes 27% do total de senhas, o que, caso nossa hipótese esteja correta, imediatamente nos leva a crer que todos esses 27% das senhas possuem exatamente 8 caracteres.
A escala do blunder
Com muito pouco esforço, nós já recuperamos uma quantidade terrivelmente grande de informações sobre as senhas roubadas, incluindo: identificar as cinco principais senhas com precisão, os 2,75% dos usuários que as escolheram e determinar o tamanho exato da senha de quase um terço da base de dados.
Agora que mostramos como você começa num caso desses, você provavelmente pode imaginar o quanto ainda pode ser tirado da “maior palavra-cruzada da história da humanidade”, conforme satirizou a charge do site de humor em TI, o XKCD.

Tenha em mente que hashes saltados – a abordagem programática recomendada aqui – não teria rendido as informações mostradas até aqui – e você aprecie o tamanho da tragédia da Adobe.
Há ainda mais para se preocupar.
A Adobe também descreveu que os dados de cartões de crédito dos clientes e outras informações de identificação pessoal que foram roubadas no mesmo ataque também estavam “criptografadas”.
E o escritor do Naked Security, Mark Stockeley perguntou: “esses dados estavam criptografados com o mesmo conhecimento e cuidado? O que você acha?”
Se você estivesse na lista de vazamento da Adobe (e todas as senhas foram resetadas, forçando você a escolher uma nova), por que não entrar em contato e pedir por explicações?
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://nakedsecurity.sophos.com/2013/11/04/anatomy-of-a-password-disaster-adobes-giant-sized-cryptographic-blunder/
É um apaixonado proselitista em segurança. Ele vive e respira segurança da computação, e gostaria que todos fizessem o mesmo. Ele ganhou o prêmio Individual Excellence in Computer Security da AusCERT, em 2009.



