

O HTTP Archieve é um baú de tesouro de dados sobre desempenho na web. Lançado no final de 2010, o projeto rastreia, duas vezes por mês, mais de 300 mil sites entre os mais populares e registra como a web é feita: números e tipos de recursos, se os recursos estão comprimidos ou marcados como “cacheáveis”, tempos de renderização da página, tempo até a primeira renderização e assim por diante – acho que você entendeu.
O site do HTTP Archieve fornece várias estatísticas interessantes e agrega tendências, mas os dados no site apenas arranham a superfície das perguntas que você pode fazer! Para satisfazer a sua curiosidade, tudo que você precisa é baixar e importar aproximadamente 400 GB de dados em SQL/CSV. Fácil, certo? Não muito… Em vez disso, não seria legal se tivéssemos o conjunto completo dos dados do HTTP Archieve para fazer buscas sob demanda e em questões pontuais?
Google BiQuery + HTTP Archieve
Bom, agora você pode satisfazer a sua curiosidade em minutos (ou mesmo segundos). Todo o conjunto de dados do HTTP Archieve está disponível no BigQuery! Para começar, inscreva-se no BigQuery, vá para bigquery.cloud.google.com e clique na flecha embaixo de “API Project”: Switch to project > Display project > entre em “httparchive”
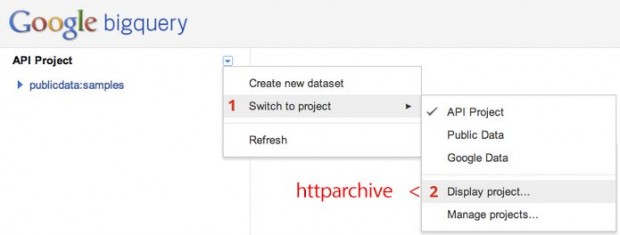
Uma vez que o projeto foi importado, expanda-o no menu à esquerda, e você verá uma coleção de tabelas para páginas individuais e dados de requisições para cara execução do crawler do HTTP Archieve. De lá mesmo, chame o console SQL e “vá à loucura”! Por exemplo, vamos começar devagar: qual o tempo médio para a primeira renderização?
SELECT NTH(50, quantiles(renderStart,100)) median, NTH(75, quantiles(renderStart,100)) seventy_fifth, NTH(90, quantiles(renderStart,100)) ninetieth FROM [httparchive:runs.2013_06_01_pages]
E a resposta é: média de 2.2s, 3.3s para 75% e 4.7s para 90%. O BigQuery fornece algumas funções convenientes, como quantis, aproximações estatísticas, extensões para expressões regulares para combinação e extração, e muito mais. Cheque a referência para queries e o livro de receitas de query para aprender mais.
Apenas um framework JS não é suficiente
Para aumentar nossas novas habilidades em BigQuery, vamos encontrar páginas que usam múltiplos frameworks JavaScript na mesma página:
SELECT pages.pageid, url, cnt, libs, pages.rank rank FROM [httparchive:runs.2013_06_01_pages] as pages JOIN (
SELECT pageid, count(distinct(type)) cnt, GROUP_CONCAT(type) libs FROM (
SELECT REGEXP_EXTRACT(url,
r'(jquery|dojo|angular|prototype|backbone|emberjs|sencha|scriptaculous).*\.js') type, pageid
FROM [httparchive:runs.2013_06_01_requests]
WHERE REGEXP_MATCH(url, r'jquery|dojo|angular|prototype|backbone|emberjs|sencha|scriptaculous.*\.js')
GROUP BY pageid, type
)
GROUP BY pageid
HAVING cnt >= 2
) as lib ON lib.pageid = pages.pageid
WHERE rank IS NOT NULL
ORDER BY rank asc
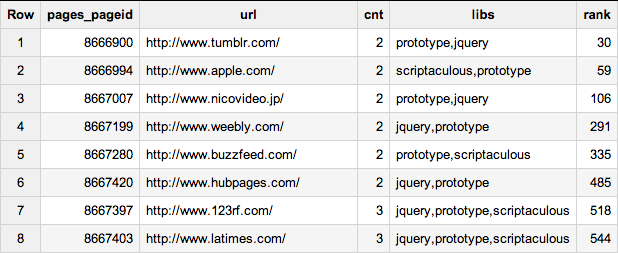
JQuery é claramente o favorito da maioria, mas o prototype (apesar da idade) continua forte. Pior, há muitos sites com três ou quatro frameworks diferentes e mesmo versões diferentes de cada um deles na mesma página!
Bom dremel – ou melhor BigQuerying! Para mais exemplos, cheque este gist com queries de exemplo.
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://www.igvita.com/2013/06/20/http-archive-bigquery-web-performance-answers/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?