



Git (e Github) para dados
Este artigo descreve um “modelo de dados” simples para armazenamento e versionamento de dados utilizando ferramentas efetivas.

A habilidade de fazer controle de versão é uma grande questão para dados. Há várias opções, mas uma das mais atraentes é reutilizar ferramentas pré-existentes que fazem isso com código, como git e mercurial. Este artigo descreve um “modelo de dados” simples para armazenamento e versionamento de dados utilizando essas ferramentas que temos usado há algum tempo e que achamos muito efetivas.
Introdução
A habilidade de revisar e versionar dados – armazenar mudanças feitas e compartilhá-las com outros – especialmente de uma forma distribuída seria de enorme benefício para a comunidade de dados (abertos). Eu já discuti o porquê com algum detalhe (veja também este artigo anterior), mas resumindo:
- Permite colaboração descentralizada de forma efetiva – você pode pegar meu conjunto de dados, alterá-lo e compartilhá-lo novamente comigo (e outras pessoas podem fazer isso ao mesmo tempo!)
- Permite que qualquer um acompanhe melhor a procedência (ex.: de onde vieram quais mudança)
- Permite compartilhar e sincronizar conjuntos de dados de forma simples e eficiente – ex.: uma forma automatizada de acessar o PIB dos últimos meses ou dados de empregabilidade sem ter que baixar o arquivo todo novamente
Há muitas maneiras de resolver esse problema de “controle de versão para dados”. A abordagem aqui é ter os dados de uma forma que possamos pegar poderosas ferramentas de controle de versão pré-existentes para código, como git e mercurial e aplicá-las aos dados. Dessa forma, o melhor github para dados pode ser, na verdade, o próprio github (é claro que você pode querer uma camada específica para dados como interface sobre o git(hub) – é isso que fazemos com http://data.okfn.org/).
Há limitações nessa abordagem, e discutirei algumas delas logo abaixo, assim como modelos alternativos. Ela é particularmente interessante para “pequenos (ou mesmo micro) dados” – digamos, abaixo de 10Mb ou 100 mil linhas (um modelo alternativo pode ser encontrado no interessante projeto Dat, recentemente iniciado por Max Ogden – com o qual conversei muitas vezes sobre esse tópico).
Entretanto, dada a maturidade e o poder das ferramentas empregadas – e sua provável evolução – junto ao fato de que a maior parte dos dados é pequena, achamos que essa abordagem é muito atraente.
O modelo
A essência desse modelo é:
- Armazenar dados como texto orientado a linhas e especialmente como CSV1 (comma-separated variable, ou valores separados por vírgulas). “Texto orientado a linhas” indica que unidades individuais dos dados, tais como linhas de uma tabela (ou uma célula), correspondem a uma linha2.
- Utilizar o melhor tipo de ferramenta de versionamento (de código), tal como git ou mercurial, para armazenar os dados.
Texto orientado a linhas é importante por permitir que as poderosas ferramentas de controle distribuído de versão como git e mercurial funcionem de forma eficiente (isso é resultado dessas ferramentas terem sido feitas para código que é, por sua vez, (normalmente) texto orientado a linhas). Não se trata portanto apenas de controle de versão: há um grande número de ferramentas maduras para a utilização e a manipulação desse tipo de dados (de grep a Excel!).
Além do modelo básico, há algumas vantagens extras que você pode acrescentar:
- Armazenar os dados no GitHub (ou Gitorious, ou Bitbucket, ou…) – todos os exemplos abaixo seguem essa abordagem.
- Transformar o conjunto de dados em um pacote do tipo SDF (Simple Data Format), ao adicionar um arquivo. datapackage.json que acrescenta um pequeno conjunto de informações essenciais como licença, fontes, e esquemas (essa coluna é de números, essa é de strings etc.).
- Acrescentar os scripts que você usou para processar e gerenciar os dados – dessa forma, tudo fica junto em um único repositório
O que há de bom nesse modelo
As ferramentas existentes para administrar e manipular arquivos orientados a linhas são gigantes e maduras. Poderosos sistemas de controle distribuído de versão, particularmente o git e mercurial, já são formas extremamente robustas de realizar colaboração distribuída e peer-to-peer quando se trata de código; e esse modelo se apropria desse padrão para aplicá-lo aos dados. Aqui vão alguns exemplos concretos de por que ele é uma boa opção.
Rastreamento da origem
Git e mercurial fornecem um histórico completo da contribuição dos indivíduos com mensagens simples de commits ou diffs.
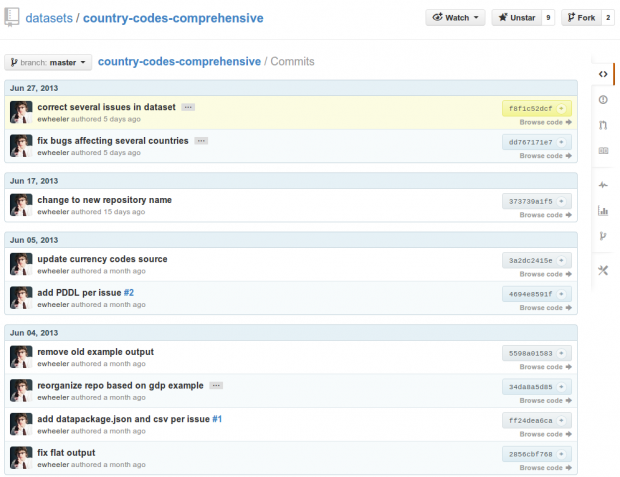
Colaboração peer-to-peer
Forks e pulls de dados permitem que contribuidores independentes trabalhem simultaneamente.

Revisão dos dados
Ao utilizar git ou mercurial, ferramentas para a revisão de código podem ser refeitas para a revisão de dados.
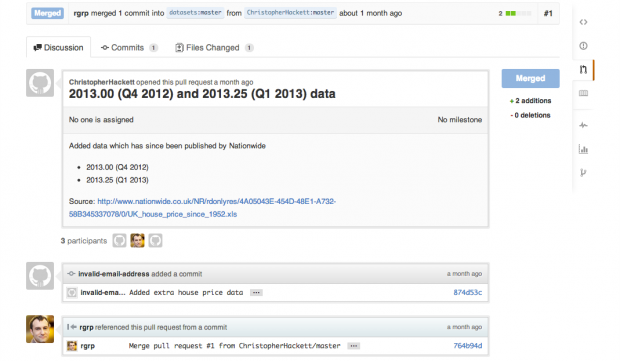
Um pacote para todos
O modelo de repositório propicia uma maneira simplificada de armazenar dados, código e metadados em um único lugar.
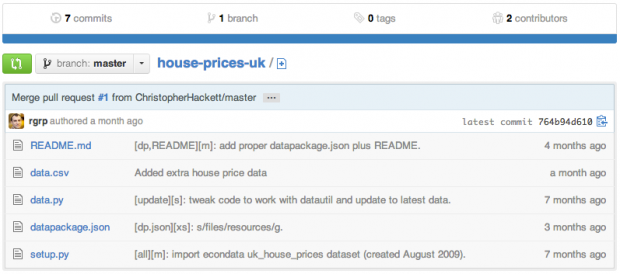
Acessibilidade
Esse método armazenamento e versionamento de dados é bastante de “baixa tecnologia”. O formato e as ferramentas são muito maduros e amplamente disponíveis. Por exemplo, toda ferramenta de planilha e todos banco de dados relacional pode lidar com CSV. Toda plataforma unix possui um conjunto de ferramentas como grep, sed e cut que podem ser utilizadas nesse tipo de arquivo.
Exemplos
Estamos utilizando essa abordagem há um bom tempo: em 2005, armazenamos CSVs pela primeira vez em subversion, depois no mercurial e então mudamos para o git (e github) há três anos. Em 2011, começamos a organizar conjuntos de dados que contêm toda uma lista de dados administrados de acordo com o padrão acima, no Github. Abaixo, alguns exemplos específicos:
- País, região e PIB mundial, coletados a partir do Banco Mundial e transformados em CSV normatizado. O script em Python utilizado para limpar os dados está incluído na pasta scripts.
- Lista de empresas no Standard e Poor 500, um índice da lista das 500 maiores ações dos EUA. Inclui os scripts em Python utilizados para processar os dados e instruções sobre como replicar a limpeza dos dados a partir da fonte. Esses conjuntos de dados fornecem exemplos interessantes sobre como se parece um diff, incluindo diffs ruins (ex.: o rearranjo de colunas).
Note que a maioria desses exemplos não contém apenas CSVs gerenciados pelo github, mas são também pacotes SDF – veja o arquivo datapackage.json que eles contêm.
Adendo
Limitações e alternativas
Texto orientado a linhas e suas ferramentas estão, obviamente, longe de ser a solução perfeita para o armazenamento de dados e seu versionamento. Eles não funcionarão para conjuntos de dados de todos os tamanhos e formatos e, em alguns aspectos, são ferramentas desajeitadas para rastrear e acrescentar mudanças em dados tabulares. Por exemplo:
- Ações simples podem resultar em mudanças muito grandes quando se trata desse tipo de formato de dados. Por exemplo, trocar a ordem de dois campos (=colunas) resulta em uma mudança em cada uma das linhas do arquivo. Dado que diffs, merges etc. são orientados a linhas, isso é indesejado3.
- Funciona melhor para pequenos dados (ex.: menos de 100 mil linhas, arquivos menores que 50Mb e melhor ainda para arquivos menores do que 5Mb). Git e mercurial não lidam muito bem com arquivos muito grandes, e recursos como diffs ficam mais difíceis com arquivos maiores4.
- Funciona melhor para dados constituídos por muitos registros similares; em condições ideais, dados tabulares. Para que o armazenamento e as ferramentas orientadas a linhas sejam apropriadas, você precisa que a estrutura de armazenamento dos dados comporte a estrutura do CSV. O padrão é menos apropriado caso seu CSV não seja muito orientado a linhas (ex.: se você tiver muitos campos com quebras de linha), causando problemas para diffs e merges.
- O CSV carece de muitas informações, por exemplo, tipos de dados (tudo são strings). Não há uma maneira de acrescentar metadados a um CSV sem comprometer a simplicidade ou fazer com que ele deixe de ser utilizável como “texto puro”. É possível, no entanto, acrescentar esse tipo de informação em um arquivo separado, e é exatamente isso que o padrão Data Package faz com o arquivo datapackage.json.
Mas a maior limitação de todas surge ao aplicar diffs orientados por linhas e merges a dados estruturados cuja unidade não é uma linha (que é uma célula, ou algum tipo transformação como uma troca de posicionamento de duas colunas).
A primeira questão é discutida abaixo, onde uma simples mudança em uma tabela é tratada como uma mudança em todas as linhas é um exemplo bem claro. Em um mundo perfeito, teríamos tanto uma estrutura conveniente quanto ferramentas robustas para nos auxiliar. Ex.: ferramentas para reconhecer a troca de duas colunas em um CSV como uma única mudança ou o trabalho no nível das células.
Fundamentalmente, um sistema de revisão é cnstruído sobre um formato diff e um protocolo de merge. Faça isso direito e o resto é consequência. As três opções básicas que você tem são: serialize para um texto orientado a linhas e utilize ótimas ferramentas como o git (que descrevi acima), identifique a estrutura atômica (ex.: um documento) e aplique o diff nesse nível (pense no CouchDB ou copy-on-write padrão para gerenciadores de bancos de dados relacionais no nível das linhas), grave as transformações (ex.: refinamentos).
Na Open Knowledge Foundation, fizemos um sistema ao longo de linhas do modelo 2 e estivemos envolvidos em explorar e pesquisar ambos os padrões 2 e 3 – veja mudanças e sincronização de dados no dataprotocols.org. Essas opções definitivamente merecem ser exploradas – e Max Ogden, por exemplo, com quem tive muitas discussões sobre esse tema, está atualmente trabalhando em um excitante projeto chamado Dat, uma ferramenta de dados colaborativos que utilizará o protocolo “sleep”.
Contudo, nossa experiência até agora é que orientação a linhas bate todas as outras opções disponíveis atualmente (pelo menos para arquivos pequenos!).
data.okfn.org
Tendo armazenado dados no Github por todos esses anos, lançamos recentemente o http://data.okfn.org/ que é explicitamente baseado nesta abordagem:
- Dados são armazenados em CSV e em repositórios no GitHub em https://github.com/datasets
- Todos os conjuntos de dados são pacotes com metadados em datapackage.json.
- O site frontend é ultrassimples – apenas fornece um catálogo, e a API e puxa dados diretamente do Github.
Por que orientação por linhas
Texto orientado a linhas é a forma natural de código e é suportado por um enorme número de excelentes ferramentas. Mas é também a forma mais simples e econômica de armazenar dados orientados a registros – e a maioria dos dados pode ser transformada em registros.
Basicamente, dados estruturados necessitam de um delimitador para campos e outro para registros. Arquivos de valores separados por vírgulas ou tabulação (CSV, TSV, na sigla em inglês) são uma implementação bastante natural e simples dessa codificação. Eles limitam os registros com o caractere de separação mais natural depois do espaço: a quebra de linha. Para um delimitador de campo, uma vez que espaços são muito comuns nos valores para poderem ser a opção mais apropriada, lança-se mão das vírgulas ou tabulações.
Sistemas de controle de versão necessitam de uma unidade atômica para funcionar. Um sistema de versionamento para dados pode, de forma útil, tratar registros como unidades atômicas. A utilização de texto orientado a linhas, como a codificação para dados codificados a registros, automaticamente nos fornece um sistema de versionamento orientado a registro, na forma de ferramentas existentes para o versionamento de código.
- Note que CSV, na verdade, significa “DSV”, uma vez que o delimitador no arquivo não precisa necessariamente ser uma vírgula. Contudo, o finalizador da linha precisa ser uma quebra de linha (ou uma quebra de linha mais um “carriage return”. ↩
- CSVs nem sempre têm uma fileira em cada linha (é possível ter quebras de linha em um campo com citações). Apesar disso, a maior parte dos CSVs tem uma-fileira-por-linha. CSVs são praticamente a estrutura de dados mais simples que você pode ter. ↩
- Como exemplo concreto, a função merge irá provavelmente funcionar muito bem para reconciliar dois conjuntos de mudanças que afetam diferentes grupos de registros, ou seja, diferentes linhas. Duas mudanças, cada uma com uma troca de coluna não funcionará tão bem, apesar disso.↩
- Para dados maiores, sugerimos trocar o git (e Github), para um storage simples como o S3. Note que o s3 pode suportar versionamento copy-on-write básico. Contudo, copy-on-write é comparativamente muito mais ineficiente.↩
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://blog.okfn.org/2013/07/02/git-and-github-for-data/



