

Gerar métricas referentes a uma ferramenta, serviço ou sistema nem sempre é uma tarefa fácil, e muitas vezes não há informações suficientes para se chegar aos dados desejados. Desde o primeiro dia deste ano, estou encarando um projeto que me colocou nesse desafio. Para encará-lo, percebi que seria necessário usar diversas ferramentas, além de ter que desenvolver um software para captação e análise dos dados.
Algumas das ferramentas que escolhi são bem conhecidas, outras menos. Não pretendo entrar aqui em detalhes extremamente técnicos, mas sim destacar a conexão que tenho feito entre elas para obter os resultados de que preciso. Espero que isso possa contribuir para a realização de outros projetos.
O primeiro passo foi avaliar quais eram a principais dificuldades para obter os dados para a elaboração das métricas. Conclui que os cinco principais pontos eram:
- A presença da empresa em 19 países: o que implica ter que contatar diversas fontes de informação;
- Além do site, há todo o tráfego das APIs que são públicas para desenvolvedores terceiros, o que aumenta o volume de informações;
- Os logs do NGINX giram em pouco mais de 7Gbps;
- Nem toda informação que as áreas de negócio precisam estão nos logs;
- Como armazenar o resultado de forma eficiente?
Considerando a quantidade gigantesca de informações que precisam ser lidas, uma coisa era certa: o software precisaria ser desenvolvido em uma linguagem robusta e de baixo consumo de memória dos servidores; caso contrário, em vez de um problema teríamos dois.
Streaming dos logs
O Kafka é uma plataforma de streaming distribuída que está sob a licença da Apache Software Foundation e foi utilizada para ser capaz de distribuir os logs do NGINX em diferentes consumidores. Na página do Kafka, é possível aprender mais a respeito e fazer o download gratuitamente.
A aplicação do Kafka foi muito bem resumida com esta imagem, a qual mostra os Producers, que são os logs da NGINX.
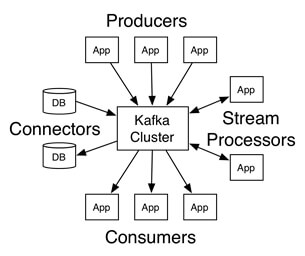
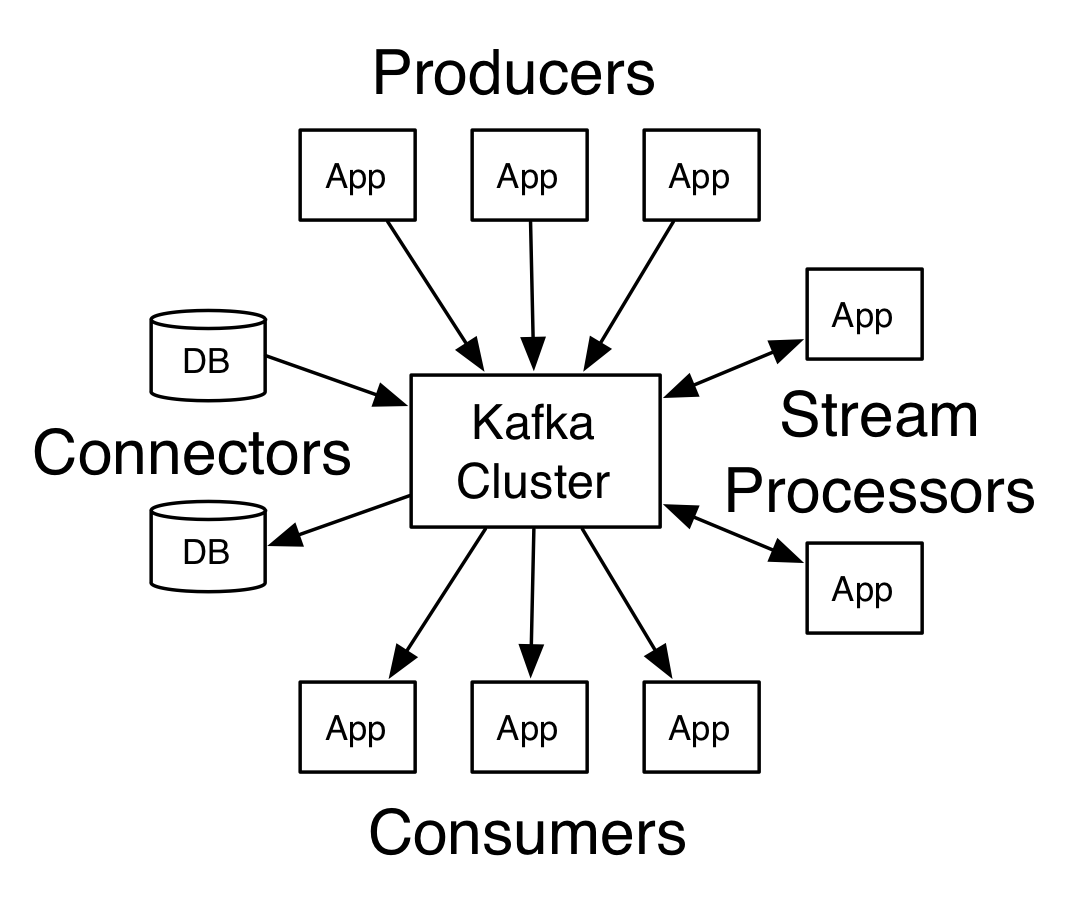{kind=link}
Consumers
Para desenvolver esse software, escolhi a linguagem Go para receber o streaming do Kafka, já que em vários testes realizados internamente ele se mostrou muito mais eficiente do que outras linguagens que já utilizamos. Em um outro artigo (veja o material através desta URL: https://goo.gl/YJJ4iE), é possível ver uma comparação entre Go e Grails e as vantagens de se migrar uma aplicação para Go – uma linguagem open source que pode ser baixada no próprio site.
Armazenamento
O Elasticsearch é uma excelente pedida quando o assunto é grande quantidade de dados, buscas complexas e fácil escalabilidade. Além de trabalhar com modo clusters e indexar os dados de forma incrível, oferece a facilidade de adicionar geolocalização às informações. Além do Elasticsearch, a empresa oferece o Kibana, que torna todas as consultas ao Elasticsearch extremamente simples – até mesmo pessoas não técnicas conseguem criar relatórios e gerar gráficos pela ferramenta.
Mas nós ainda tínhamos um problema…
Como eu disse, os logs do NGINX não atendem a 100% da necessidade de informações de que precisávamos. Decidimos utilizar o BigQueue (BQ), um sistema de tópicos de multiconsumidor, criado pelo próprio Mercado Livre e projetado para ser muito simples e escalável.
A ideia principal desse sistema é que cada tópico possa ser consumido de forma assíncrona por muitos grupos de consumidores; os grupos de consumidores inscritos em um mesmo tópico receberão o mesmo grupo de mensagens, então podemos lê-las de forma paralela, usando muitos processos de leitura. O BQ é baseado no redis http://redis.io/ como seu armazenamento principal, mas poderia ser implementado em qualquer sistema persistente.
Uma das coisas mais atraentes do BQ é a ideia de ser assíncrono, o que nos permite criar uma API Restful (poderia ser qualquer outro protocolo mais rápido, se quiséssemos) que implementa um padrão de comunicação similar ao Amazon SQS, sendo muito fácil de integrar em qualquer plataforma/sistema.
Para obter todas as informações necessárias para as métricas que eu tinha que desenvolver, passei a ter acesso aos tópicos criados por cada equipe (shipping, itens, orders, users e payments) dentro do Big Queue. Isso permite que eu acompanhe as atualizações on time e gere históricos, garantindo rapidez e precisão no trabalho.
Conclusão
Fazendo um balanço ao final dessa jornada – as métricas já estão quase todas prontas -, percebo que não foi necessária a utilização de nenhuma plataforma proprietária. Foram utilizadas apenas ferramentas gratuitas, sobre as quais cresce cada vez mais o volume de informações na Internet, tornando-se cada vez mais fácil implementá-las. E quem está pensando: “será que vale a pena mesmo utilizar essas ferramentas?”, eu o encorajo: vale, sim! Busque por mais informações e deixe também os seus comentários.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?