



Paralelismo no Oracle Datapump – #Melhores2013
Este artigo demonstra técnicas e boas práticas para melhores resultados ao usar o Datapump, e como funciona o paralelismo nesse utilitário.

O propósito deste artigo é demonstrar um conjunto de técnicas e boas práticas para obter melhores resultados ao utilizar a ferramenta de importação e exportação do Oracle, o Datapump, tal como o funcionamento do paralelismo nesse utilitário. Este artigo se aplica somente à versão Oracle Enterprise, visto que o recurso de paralelismo não está disponível nas demais versões.
Primeiro, deve-se entender como esse recurso de paralelismo funciona no Datapump, então, pode-se concluir se ele será útil ou não para uma determinada operação de movimentação de dados.
O parâmetro Parallel
O Datapump utiliza uma arquitetura multiprocessual na qual um único processo mestre (Master Control Process – MCP) atribui funções/trabalhos para os worker process, estes, quando ativos, irão carregar/descarregar um objeto. Esse mesmo processo poderá ainda coordenar os chamados Parallel Execution Processes (PX)[1].
O valor usado nesse parâmetro indica quantos processos PX e workers ativos podem ser usados ao mesmo tempo para carregar/descarregar dados, porém, o fato é que nem sempre um worker process irá usar os processos PX para carregar/descarregar um objeto, e isso é que irá influenciar na melhoria desse procedimento.
O Oracle usa uma métrica para decidir se irá usar ou não processos PX. Primeiro, ele busca o tamanho estimado da tabela sem contar os metadados. Num segundo passo, divide esse número por 250MB; caso o resultado seja maior que 1, poderá ser usado em processos PX se e somente se a estrutura da tabela/partição permitir. Caso a tabela ou partição permita, o número obtido será a quantidade de PX que poderá ser alocada.
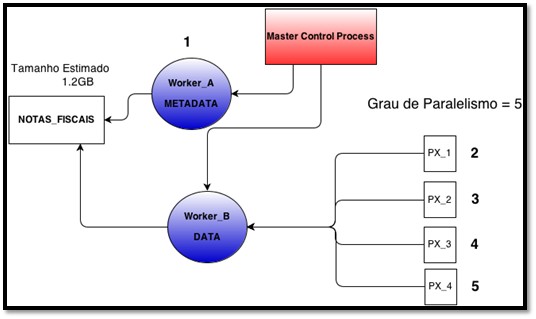
Figura 1 – Operação de export em uma tabela
Nesse exemplo hipotético de export, pode-se fazer as seguintes observações. Primeiro, como dito, o grau de paralelismo calculado só será alcançado caso o parâmetro especificado seja igual ou superior. Segundo, quando usa-se processos PX, o worker process responsável pela coordenação não é contado no grau de paralelismo.
Métodos de acesso
A primeira medida tomada pelo worker process ao receber uma tarefa de import/export é definir qual será o método de acesso usado. Entre eles, dois são os mais utilizados: External tables e Direct Path.
O método mais ágil dentre os dois é o Direct Path, mas esse método possui algumas inflexibilidades, sendo descartado quando uma delas é encontrada no objeto a ser carregado/decarregado. Entre essas limitações, as principais estão na seguinte listagem[2]:
- Colunas encriptadas;
- Tabelas com active triggers (Import);
- Colunas BFILE;
- Impossibilidade de usar os parâmetros QUERY,SAMPLE ou REMAP_DATA;
- Não consegue usar processos PX.
O método External table sempre é escolhido quando uma tabela ou partição possui mais de 250MB ou quando sua estrutura impossibilita o uso do Direct Path.
Observações úteis
- No método de import, um worker de dados só é executado a partir do momento em que finda-se o trabalho do worker de metadados, que por sua vez também começa a carregar dados;
- Datapump nunca irá paralelizar metadados, exceto em operações de import caso o objeto em questão seja um índice ou um package body;
- Em operações de export, um worker ou PX necessita de acesso exclusivo ao dumpfile, logo deve-se usar um wildcard[3] no parâmetro, caso contrário, apenas um processo estará apto a gravar as informações coletadas.
Boas práticas
- Mantenha o dumpfile em um disco diferente do de datafiles da tablespace destino, assim o Oracle irá ler num disco e gravar noutro, aumentando a performance;
- Na primeira execução, use o dobro do número de CPU’s como valor do parâmetro PARALLEL; a partir daí, mensure o valor de acordo com as experiências obtidas.
Conclusão
O aproveitamento do paralelismo no datapump está diretamente relacionado à quantidade de dados das tabelas, logo só será proveitoso quando houver tabelas com alto volume de dados.
Referências
- http://docs.oracle.com/cd/B28359_01/server.111/b28319/dp_perf.htm#i1005617
- http://download.oracle.com/otndocs/products/database/enterprise_edition/utilities/pdf/datapump11gr2_parallel_1106.pdf
[1] Para entender melhor o funcionamento destes processos, recomendado a leitura deste artigo
[2] A lista completa pode ser encontrada no My Oracle Support através do Article ID : 552424.1
[3] Exemplo: dumpfile=datapump_%U.dmp
é DBA Oracle/Consultor Técnico na empresa LB2 Consultoria e Tecnologia em Londrina-PR, onde trabalha dando consultoria em banco de dados Oracle 10g/11g para diversas empresas.


