

Veja também como foi o primeiro dia da conferência
O segundo dia começou mais tarde, visto que na noite do primeiro dia a turma se concentrou no lobby do hotel para trocar ideias sobre projetos e contar como estão utilizando o MySQL. Todo esse ambiente é propositalmente proporcionado pela organização do evento para que haja muita interação entre os vários administradores de bancos de dados MySQL que vistam o evento. Muita gente do mundo inteiro, mais de 1.000 pessoas reunidas para mais de 143 sessões técnicas, em um evento que concentra os grandes players mundiais de MySQL. Sendo assim, a turma começou a se reunir no Hall B, que fica bem no meio do centro de convenções, às 8:50 da manhã, enquanto os palestrantes também chagavam para compor as sessões que ganharam o nome de keynotes!
O primeiro o subir no palco foi o CEO da empresa norte-americana Percona, Peter Zaitsev, que falou de sua história relacionada com bancos de dados e resolução de grandes problemas de escala de sistemas exibindo uma foto quando ainda desenvolvia o primeiro software de sua vida. A mensagem era que, com muita interatividade e força de vontade, se pode chegar em qualquer lugar.

O pessoal da empresa também americana Continuent apresentou a nova abordagem para o produto Tungsten, já consagrado no mercado por replicar dados entre qualquer fonte de dados. Agora, tal produto tem uma abordagem simples para transportar dados do MySQL para o Hadoop através da leitura do log binário e também, utilizando o Apache Sqoop para o processo de ETL.
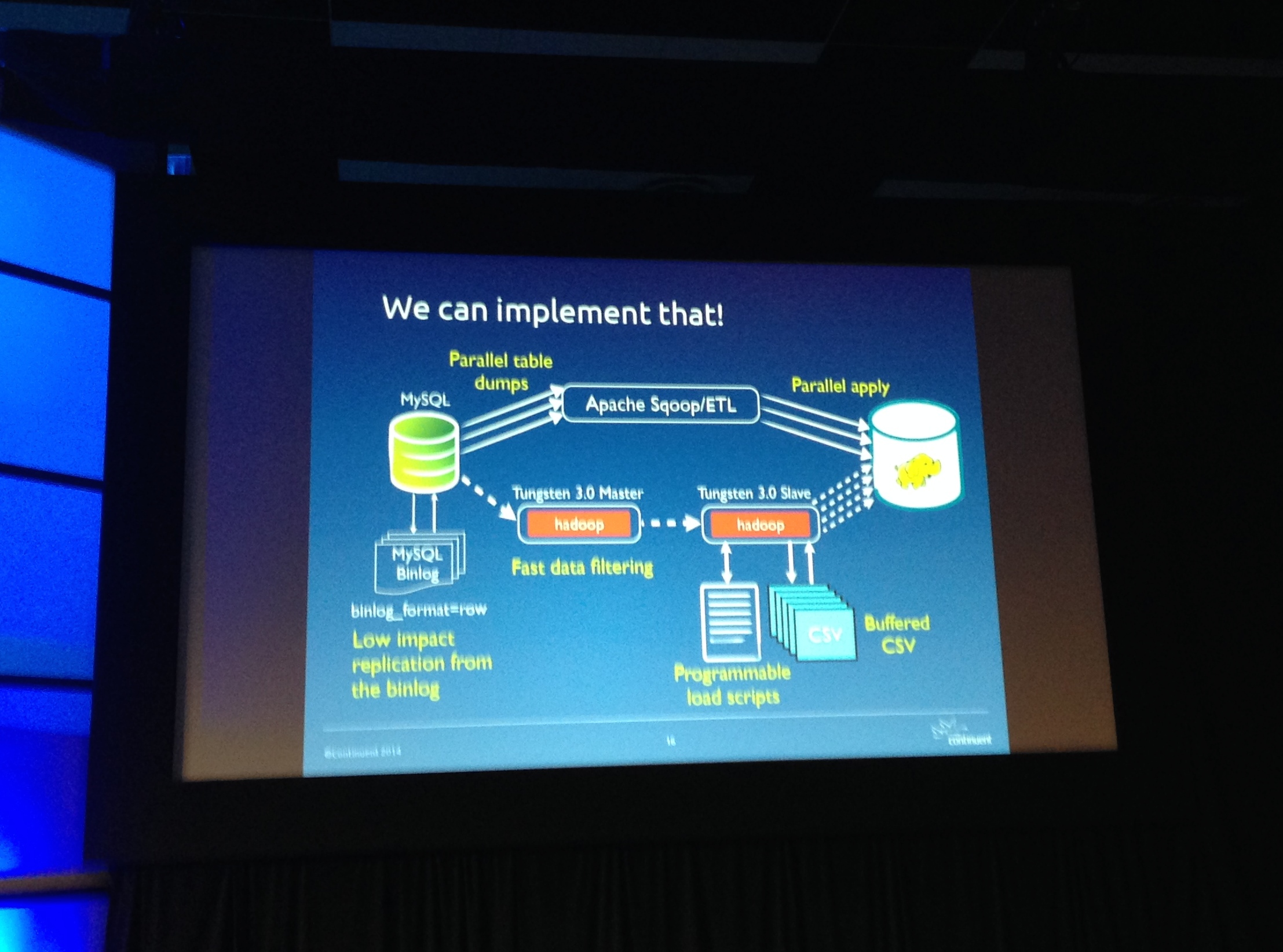
Uma abordagem interessante que eu ainda não havia pensado foi mostrada pela Continuent – uma vez que se tenha uma disco/partição formatada com o HDFS (Hadoop Ditributed File System) fica bem fácil pegar os dados do MySQL manualmente e popular o sistema de arquivos do hadoop. Uma vez que isso é feito, todas as caraterísticas podem ser viasualizadas com relação ao agrupamento natural de ocorrências do mesmo dado. No final, os dados são apresentados juntamente com sua estatísticas.
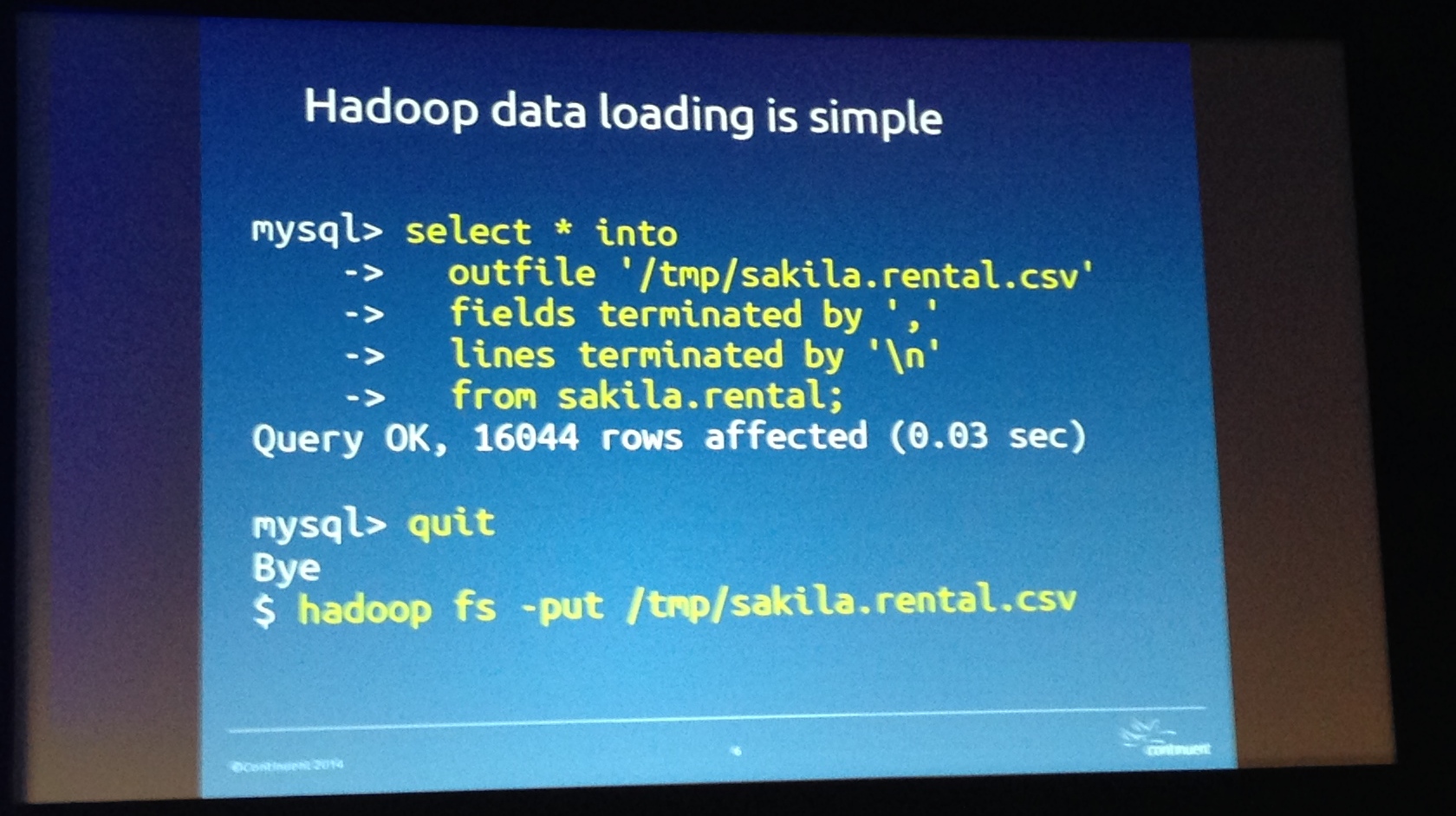
Como o formato de dados mais comum atualmente para se trabalhar com carga de dados no Hadoop é o “.csv”, o SELECT INTO OUTFILE criará um arquivo com os dados sobre o HDFS, este que organizará os dados à sua maneira – isso é um tema para um bom e longo artigo sobre Hadoop.
Bom, o momento mais esperado então do dia, Thomas Ulin no palco para a apresentação do que vinha pela frente no MySQL 5.7 e produtos que fazem parte do seu ecossistema.

Primeiramente Thomas agradeceu muito todo o feedback que vem recebendo de usuários de MySQL do mundo inteiro e ressaltou a importância de obter um feedback de testes de novos releases tão logo quanto esse puder ser enviado para que os bugs possam ser corrigidos e os novos recursos possam ser liberados. Com isso, um histórico de objetivos alcançados desde que a Oracle assumiu o MySQL.

Muitos anúncios foram feitos a começar com melhorias radicais no PERFORMANCE_SCHEMA, que vão aposentar de vez o não tão bom e velho log de queries lentas e todo o seu mecanismo. Além disso, anúncios para o InnoDB na versão 5.7 e já disponíveis no último DRM – 5.7.4 – podem ser testadas fazendo o download do MySQL 5.7 em dev.mysql.com ou labs.mysql.com.
A replicação ganhou bastante força no quesito “slave lag“ que é justamente o atraso do servidor slave e se atualizar com o master. Ainda neste aspecto e estendendo para o conceito de multi-threaded slave replication, ao contrário do que acontece com o MySQL 5.6 que disponibiliza uma thread para replicar dados por banco de dados, o MySQL 5.7 dá a possibilidade de se criar várias threads que trabalharão para replicar dados independente do número de bancos de dados – lembro que o modelo de replicação no MySQL 5.5 não permite a criação de mais de uma thread (SQL_THREAD) para servidores slave. Isso também é assunto para um novo artigo!!

O MySQL Fabric que é parte de um Python Framework desenvolvido pela Oracle e que foi batizado como MySQL Utilities tem ganhado muita força no quesito Data Sharding. Tal script permite o controle de várias instâncias de MySQL, mantendo o registro do intervalo dos dados para que estes possam ser encontrados em um dos servidores, pertencendo tal informação a um mesmo banco de dados espelhado por várias máquinas.

Outros pontos também foram ressaltados por Ulin como a possibilidade de gerar o EXPLAIN de consultas no formato JSON (JavaScript Object Notation) e a nova versão do MySQL Cluster e suas melhorias. Por fim, falou da MySQL Connect que acontece em 29 de setembro aqui em São Francisco.

Por fim, as sessões que mais chamaram a atenção da turma do InnoDB aconteceram na sala D (Ballroom D), sendo a primeira sessão sobre InnoDB Recovery no caso de um crash. A nova versão da ferramenta Percona Toolkit foi apresentada pelo amigo Marco Tusa e foi algo que realmente somou muito para quem trabalha com operações no dia-a-dia.
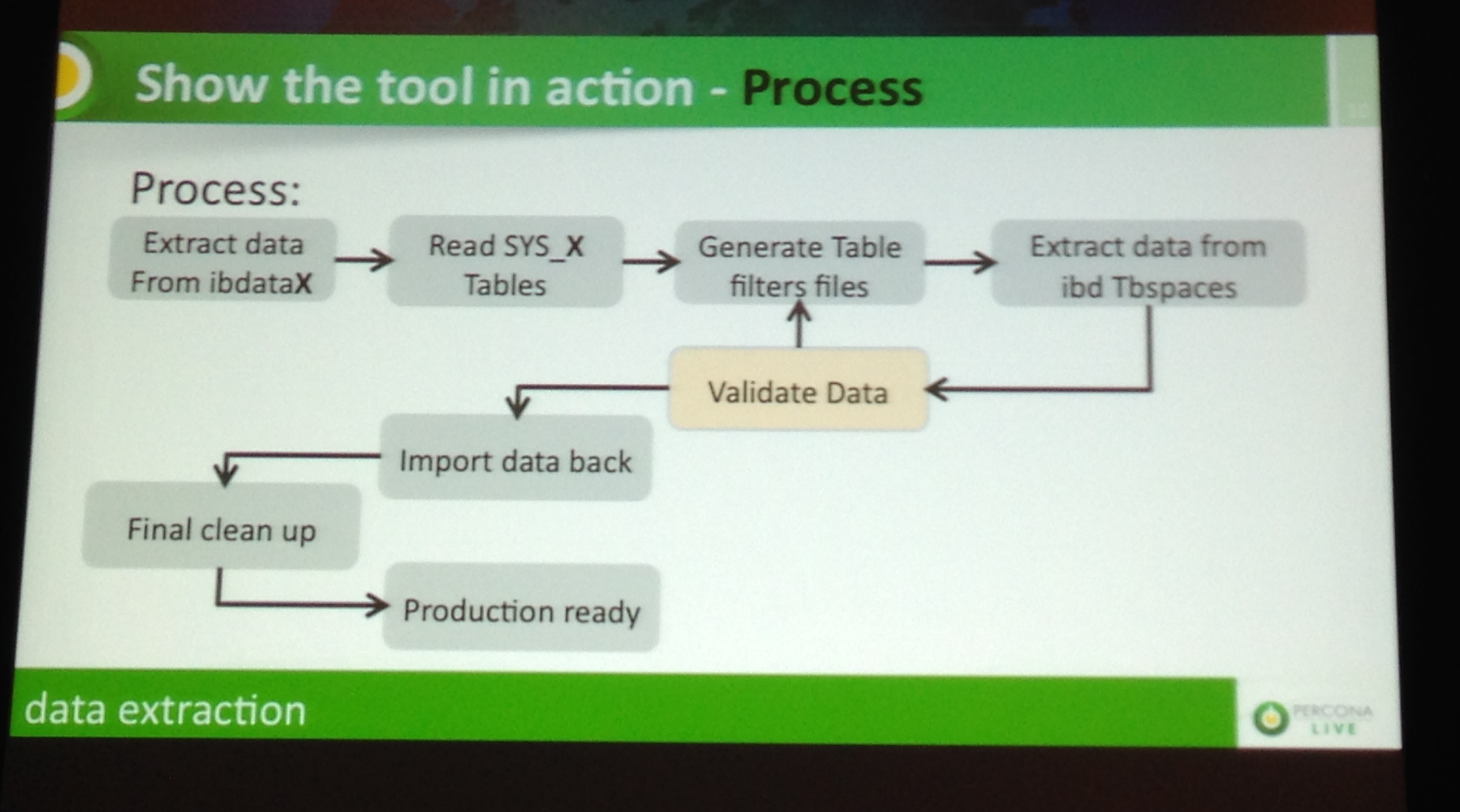
A ideia aqui é utilizar alguns aplicativos para fazer a leitura e recuperação dos dados contidos nos arquivos de tablespace .”ibd,” principalmente quando da exclusão desavisada do arquivo ibdata que é o tablespace compartilhado do InnoDB. Mesmo quando se utiliza a innodb_file_per_table=1, padrão a partir do MySQL 5.6, o arquivo ibdataX (x pode ser um inteiro a começar de 1) não pode ser excluído por conter informações de controle de objetos controlados pelo Storage Engine InnoDB. Toda a informação é armazenada nos arquivos que estão relacionados a partir de seus próprios cabeçalhos, sendo possível verificar cada space_id de cada tablespace através das tabelas SYS_* do dicionário de dados INFORMATION_SCHEMA a partir da versão 5.6 do MySQL. Com, isso, se você perder ou excluir o ibdata qualquer dia desses, lembre-se que você inda tem a oportunidade de tentar recuperar os dados com o Percona Toolkit.

Acabada a apresentação que mostrou como é possível recuperar o seu banco de dados de uma possível exclusão e/ou problemas com o arquivo ibdataX, foi a hora de aprofundar nas melhorias relacionadas com o PERFORMANCE_SCHEMA já do MySQL 5.7 com o Senior Software Developmenet Manager, Mark Leith. Além de dar um pequena introdução sobre os assunto, mostrou que o Storage Engine presente desde a versão 5.5 do MySQL, passou a ser habilitado por padrão a partir da versã0 5.6 por problemas de overhead que foram corrigidos. Além disso, algumas outras funcionalidade foram cobertas como mais instrumentos cobrindo visibilidade completa de todos os processos do MySQL que rodam em memória, os principais gargalos, locks e deadlocks e uma visão mais facilitada com relação a replicação. O abandono do log de consultas lentas também fora abordado sendo que o analise de consultas ficou bem mais elaborado se feito através do PERFORMANCE_SCHEMA.

Depois desse dia inteiro de discussões muito produtivas e sessões pra lá de satisfatórias, nada melhor que confraternizar com todo mundo do evento em um jantar que foi oferecido pela Pythian, empresa para a qual presto serviços atualmente, em parceria com o pessoal do MariaDB Foundation, que celebra a chegada do MariaDB 10.0, com vários patches desenvolvidos pelo Google.


No dia 03 teremos uma sessão muito aguardada envolvendo a turma do Fusion-IO, Percona e Continuent em um painel que deverá reservar perguntas bem interessantes com relação a performance, replicação e o que vem por aí como tendência. Aguarde o novo post!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?