



Machine Learning, aprendizado profundo
Machine Learning é uma abordagem para análise de dados que automatiza a construção do modelo analítico e é usado em todos os quatro tipos de análises.

A relevância do Analytics nos dias de hoje
Os dados em seu estado bruto e natural não oferecem muito valor, mas com as técnicas de analytics certas, eles podem oferecer informações valiosas que podem ajudar em vários aspectos da vida, tais como a tomada de decisões de negócios, campanhas políticas, além de fazer avançar a ciência médica.
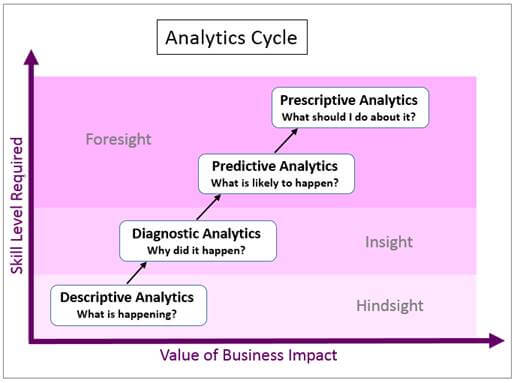
Como mostrado na Figura 1, os ciclos de analytics podem ser classificados em quatro categorias ou fases: descritiva, diagnósticos preditivos e prescritivas. Machine Learning é uma abordagem para análise de dados que automatiza a construção do modelo analítico e é usado em todos os quatro tipos de análises.
Quatro tipos de Analytics
- Análise descritiva: Este tipo determina o que está acontecendo com base em dados existentes;
- Análise de diagnóstico: Este tipo dá um passo adiante para determinar por que uma situação específica aconteceu;
- Análise preditiva: Este tipo olha através de um conjunto mais amplo de dados, talvez ao longo de um longo período de tempo para ver as tendências e os exemplos, e então usa essa informação histórica para prever ocorrências futuras;
- Análise prescritiva: Este tipo vai além de previsão para fornecer sugestões sobre a melhor forma de mudar as situações futuras de atender às suas metas.
Figura 1. Os quatro tipo de analytics do ciclo
A relevância e o crescente uso de analytics utilizando aprendizado de máquina pode ser demonstrado pelo seu uso generalizado na campanha presidencial dos EUA de 2016. O crescimento sem precedentes na disponibilidade de informações úteis, juntamente com os avanços na tecnologia, está tornando a análise mais atraente para usar, para criar e para executar uma melhor campanha. Equipes de campanha analisam o sentimento do eleitor, a segmentação da população e padrões de voto históricos, e usam essas informações para planejar melhor em quais estados e em quais perfis de eleitores eles devem concentrar os seus esforços de campanha, a fim de garantir o máximo de participação.
O aprendizado de máquina é o cerne do que torna isso possível. Com essa nova tendência, o ativo real mudou rapidamente em qualquer campanha política. Agora, os fundos para os dados do eleitor são recolhidos a partir de pesquisas de opinião, fundraisers, trabalhadores de campo, bancos de dados de consumidores, empresas privadas, bem como por meio de cookies e programas rastreadores em sites de campanha e aplicativos de mídias sociais. A aplicação de algoritmos de aprendizagem de máquina sobre esse repositório colossal de dados dos eleitores mudou a paisagem das campanhas eleitorais, fornecendo percepções orientadas para a ação: previsões para cada eleitor individual. Esses insights são usados pelas campanhas para traçar estratégias de levantar fundos, melhorar os anúncios, e criar modelos detalhados de eleitores swing-estaduais. O aprendizado de máquina tem o potencial de aumentar a eficácia dos esforços da campanha através do cálculo da probabilidade de um candidato aparecer nas urnas, a probabilidade de levar às urnas uma pessoa que não vota normalmente e, finalmente, quão persuadível alguém seria pelos diversos meios de contato da campanha. Como resultado, o aprendizado de máquina permite que as campanhas seja mais direcionadas pelas métricas.
Visão geral do aprendizado de máquina
Os algoritmos de aprendizado de máquina aprendem de forma iterativa, a partir de dados, permitindo assim que computadores encontrem ideias ocultas sem ser explicitamente programados para procurar por isso. Aprendizado de máquina é, essencialmente, ensinar o computador a resolver problemas através da criação de algoritmos que aprendem olhando para centenas ou milhares de exemplos, e então usar essa experiência para resolver o mesmo problema em novas situações. Tarefas de aprendizagem automática são tipicamente classificadas nas seguintes três macrocategorias, dependendo da natureza do sinal de aprendizagem ou do feedback disponível para um sistema de aprendizagem:
1 – Aprendizagem supervisionada: O algoritmo é treinado sobre os dados históricos marcados e aprende as regras gerais que mapeiam entradas para as saídas-alvo. Por exemplo, com base em dados históricos de eleitores (detalhes de eleitores rotulados com os seus votos – etiqueta – nos anos anteriores), as campanhas presidenciais podem prever quais os tipos de eleitores tendem a votar em um determinado candidato ou quais tipos de eleitores estão persuadíveis por esforços de campanha e usar essas informações para melhor utilização dos recursos.
Na aprendizagem supervisionada, a descoberta de relações entre as variáveis de entrada (por exemplo, os detalhes de eleitores, tais como idade e renda) e a variável rótulo/alvo (por exemplo, o voto pelo eleitor em particular na última eleição) é feito com um conjunto de treinamento. O computador aprende com os dados de treinamento.
Um conjunto de teste é utilizado para avaliar se as relações descobertas possuem a força e se a utilidade da relação preditiva é avaliada por alimentação do modelo com as variáveis de entrada dos dados de teste e comparando o rótulo previsto pelo modelo com o rótulo real dos dados.
A decisão sobre a divisão proporcional entre os dados totais e os dados de teste é muitas vezes considerada complicada. Ter uma maior proporção de dados como dados de teste garante uma melhor validação de desempenho do modelo. Além disso, poucos dados para treinamento fornecem menos dados para o modelo aprender. Opiniões sobre uma boa separação geralmente variam de uma proporção de dados de comboio e teste nas faixas de 60:40 a 80:20.
2 – Aprendizado não supervisionado: O algoritmo é treinado em dados não marcados. O objetivo desses algoritmos é explorar os dados e encontrar alguma estrutura dentro. Por exemplo, com esses algoritmos, as campanhas presidenciais podem identificar segmentos de eleitores com atributos semelhantes, que podem então ser tratados da mesma forma na campanha, personalizando os esforços da campanha para cada grupo. Os algoritmos de aprendizagem não supervisionada mais amplamente utilizados são Análise de Agrupamento e Análise Market Basket.
3 – Treinamento de reforço: O algoritmo aprende através de um sistema de feedback. O algoritmo leva ações e recebe feedback sobre a adequação de suas ações e, com base no feedback, modifica a estratégia e adota outras ações que maximizam a recompensa esperada ao longo de um determinado período de tempo. Aprendizado por reforço é mais amplamente utilizado em carros automáticos, drones, e outras aplicações de robótica.
Visão geral do aprendizado profundo
Aprendizado profundo é um tipo especial de Machine Learning que envolve um nível mais profundo de automação. Um dos grandes desafios da aprendizagem de máquina é a extração de características, onde o programador precisa dizer ao algoritmo que tipos de coisas ele deve procurar a fim de tomar uma decisão, e apenas alimentar o algoritmo com dados brutos raramente é eficaz. A extração de características coloca um enorme fardo sobre o programador, especialmente em problemas complexos, tais como reconhecimento de objetos. A eficácia do algoritmo depende muito da habilidade do programador. Modelos de aprendizagem profunda resolvem esse problema, pois eles são capazes de aprender a concentrar-se sobre as características corretas por si só e requerem pouca orientação do programador, fazendo a análise melhor do que os seres humanos podem fazer. Modelos de aprendizagem profunda têm sido muito eficazes em tarefas complexas, como análise de sentimento e visão computacional. No entanto, os algoritmos de aprendizado profundo, devido ao seu processo de aprendizagem lento, associado a uma hierarquia em camadas profundas da aprendizagem das abstrações de dados e representações de uma camada de nível inferior a uma camada de nível superior, são muitas vezes proibitivos e computacionalmente intensivos.
Começando com Machine Learning no IBM Power Systems
Usar aprendizado de máquina requer uma variedade de habilidades e técnicas de engenharia. Fazer uso do aprendizado de máquina em sua empresa provavelmente vai exigir uma equipe de especialistas que possuam conhecimentos e habilidades em diferentes aspectos de dados e análises. As habilidades variam de compreender e acessar dados a serem utilizados, saber como usar ferramentas de limpeza de dados, compreeder conceitos de aprendizagem de máquina e algoritmos, ter experiência com ferramentas de análise, as aplicações de programação e configuração do hardware e software necessários para implementar e implantar o ambiente de processamento de aprendizado de máquina.
Aqui está uma visão dos passos comuns para o uso de Aprendizado de Máquina (tutorial da IBM):
- Obter uma vantagem inicial na execução de cargas de trabalho de Aprendizado de Máquina, instalar e configurar o servidor IBM Power Systems;
- Determinar o problema de negócios para resolver;
- Identificar e recolher os dados a serem usados, pré-processar os dados para limpar e transformá-los em um estado utilizável, e dividi-los em dados do comboio e dados de teste, usando um algoritmo de aprendizado supervisionado;
- Determinar que algoritmo de aprendizado de máquina usar. O algoritmo é determinado com base na pergunta de negócios que precisa ser respondida. Por exemplo, uma rede neural pode ser usada para a análise preditiva e, para a segmentação de cliente, pode-se usar a análise de agrupamento. O melhor algoritmo para usar também depende do estado dos dados disponíveis. Por exemplo, se os dados têm um número de valores em falta, uma árvore de decisão pode ser o algoritmo preferido porque pode lidar melhor com valores em falta;
- Selecionar as ferramentas de análise e instalá-las no IBM Power Systems. Cada ferramenta de análise suporta uma ou mais linguagens de programação. Assim, a linguagem de programação usada para construir o modelo muitas vezes depende da ferramenta selecionada. Ferramentas de exemplo incluem SPSS, SAS, de fonte aberta, e spark MLlib. Exemplos de linguagem são R, Java ™ e Python;
- Escrever o código para construir um ou mais modelos usando seu algoritmo de Aprendizado de Máquina de escolha e treinar os modelos com os dados de treinamento. Se você construiu um modelo de aprendizagem supervisionada, teste-o com os dados de teste e faça os ajustes de configuração necessários para alcançar maior precisão. Se você tem vários modelos, selecione o melhor, com base no seu desempenho nos dados de teste;
- Executar o modelo no IBM Power Systems;
- Usar Apache Spark para aumentar o desempenho através da execução do modelo em um modo distribuído ou em um cluster de nós do servidor baseados no processador IBM POWER8®;
- Visualizar os resultados em uma ferramenta de análise, como o IBM Cognos Business Intelligence em IBM Power Systems.
Comece agora
Junte-se à IBM Data Science Experience para interagir e colaborar com os cientistas de outros dados, que assim como você começaram a usar aprendizado de máquina e aprendizado profundo no IBM Power Systems.
No mês passado, OpenPower anunciou uma maratona hacker chamado de OpenPower Developer Challenge que está aberta para inscrições até 1° de setembro. Uma das faixas é em aprendizagem profunda com Apache Spark em servidores OpenPower (a aceleradora Spark Rally). Essa é uma grande oportunidade de experimentar aprendizagem profunda! Para participar, clique aqui.
Recursos
Há mais coisas acontecendo na IBM com aprendizado de máquina. Aqui estão dois recursos adicionais:
***
Beth Hoffman faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://www.ibm.com/developerworks/library/l-machine-learning-deep-learning-trs/index.html
Artigo feito junto com Rupashree Bhattacharya, que atua na área de Business Intelligence na IBM.


