

Estamos extremamente acostumados a utilizar bancos de dados relacionais e não relacionais. Porém, você já parou para se perguntar por quê estes tipos de bancos são tão utilizados? Você já parou para pensar que, talvez, o modelo que você esteja utilizando para armazenar seus dados pode não ser o ideal?
Nossa quantidade de dados cresce exponencialmente a cada dia. Isto é um problema que temos que lidar diariamente. Porém, será que este é o único problema?
Bancos relacionais
Os bancos relacionais foram criados em meados de 1970. Desde então, eles têm sido o principal modelo de armazenamento de dados que tivemos. Porém, não são os mais simples e nem os mais rápidos bancos de dados em existência. Por que, então, ainda utilizamos eles?
Simplesmente pelo fato de que, por ser um padrão muito antigo, a comunidade adotou boas práticas e construiu todo um ecossistema sobre este paradigma, então, como uma biblioteca muito famosa, a comunidade cresceu ao redor deste tipo de banco de dados e se estabeleceu como o padrão primário para este tipo de função.
O problema dos relacionamentos
Bancos de dados relacionais tem esse nome justamente porque gerenciam os relacionamentos entre dois ou mais dados. Por exemplo, vamos imaginar uma ACL (Access Control List) com uma matriz de permissões. Um usuário pode estar atrelado a um ou mais Roles em uma aplicação, ele pode ser um operador e, ao mesmo tempo, um visualizador de dados. Cada role possui uma série de escopos permissivos como: Inserir novo cliente, alterar cliente, remover cliente, extrair relatório e etc. Teríamos um modelo relacional mais ou menos desta forma:
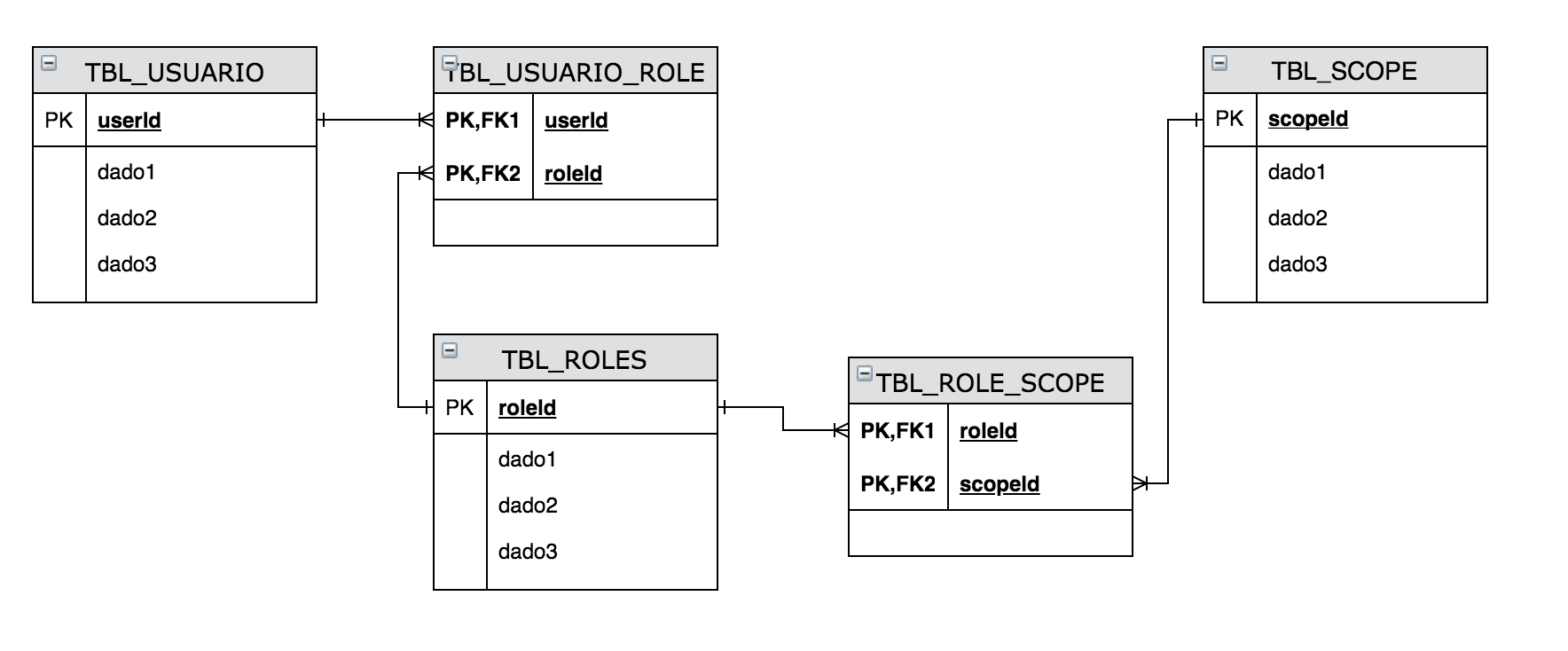
Veja que temos duas tabelas de relacionamento para podermos relacionar um usuário com mais de um role ao mesmo tempo, e também para relacionar o um role a mais de um escopo. Se quisermos saber quais são as permissões de um usuário, teremos que fazer uma query com os seguintes passos:
- Encontrar o role do usuário buscando SELECT roleId FROM TBL_USUARIO_ROLE WHERE userId = <id>
- Encontrar qual é o ID do escopo do role que estamos buscando com SELECT scopeId FROM TBL_ROLE_SCOPE WHERE roleId = <id>
- A query anterior vai nos retornar uma lista de escopos, então temos que pegar todos os escopos que estão pertinentes a ele com uma query SELECT scopeName FROM TBL_SCOPE WHERE scopeId IN (<lista>)
Obviamente podemos transformar isso tudo em uma única query utilizando JOINS e trazendo todos os dados em um único comando, porém o mais alarmante aqui é o número de relacionamento que fizemos. Perceba que, para cada usuário, temos pelo menos 2 relacionamentos novos, o usuário com o Role e o Role com o usuário.
Este é o grande problema que enfrentamos atualmente. Como expliquei anteriormente, os nossos dados estão crescendo exponencialmente de forma diária, este é um problema que os bancos de dados atuais já resolvem de forma satisfatória. O número de dados e a busca por eles já foi resolvida de várias maneiras diferentes ao longo dos anos, mas, além dos dados, há outro fator que cresce duas vezes mais rápido: os relacionamentos.
Como no nosso exemplo anterior, para cada novo dado na tabela de usuário, criamos dois novos relacionamentos, isto é uma taxa de crescimento de dois para um, ou seja, sempre teremos o dobro de relacionamentos do que os nossos dados.
Bancos não relacionais
Para resolver o problema do crescimento dos relacionamentos, tivemos uma ideia interessante: removemos os relacionamentos dos bancos. E foi assim que os modelos não relacionais foram criados. Isto aumentou muito a velocidade com o que trazemos dados e informações do banco, porém veio ao custo de não termos as verificações de integridade e constraints que os bancos relacionais nos davam por padrão.
Porém, como todas as coisas, sempre que resolvemos um problema, criamos outro problema igualmente complexo. Vamos ao nosso mesmo exemplo de ACL anterior. Imagine que agora estamos usando MongoDB para armazenar todos os nossos dados. Temos uma coleção de usuários, mas então caímos no dilema dos embedded documents: Devemos incluir os roles dentro do usuário? Ou devemos referenciar os usuários nos roles?
Fora este questionamento, temos mais vários que podemos seguir:
- Devemos incluir os roles dentro do usuário ou não?
– Prós: Teremos sempre uma query única que trará o usuário e seus roles
– Contras: Se o role mudar por algum motivo, temos que atualizar todos os usuários
- Seguindo a ideia acima, devemos incluir os scopes dentro dos roles ou apenas referenciá-los?
– Prós: Somente uma query para trazer tudo sobre o usuário (desde que os roles estejam dentro do mesmo)
– Contras: Scopes podem ser adicionados ou removidos. Vamos ter que alterar todo mundo, se um role ganhar ou perder um escopo
- Se separarmos usuários e roles, mas mantivermos os scopes dentro dos roles
– Prós: Não precisamos atualizar os usuários se os roles mudarem
– Contras: Temos que lidar com integridade referencial no nosso código
- Se separarmos tudo, usuários, roles e escopos, em collections diferentes
– Prós: Temos controle fino de cada entidade sem precisar atualizar o banco todo
– Contras: Muitas queries para trazer informação, a integridade referencial fica mais complexa
Veja que agora temos que nos preocupar com a localização e a modelagem dos documentos, que pode ser boa em determinados casos ou ruim para outros casos. Além disso, utilizar relacionamentos em um banco não relacional soa um pouco estranho, já que poderíamos facilitar muito a nossa vida simplesmente usando um banco relacional.
E então, como ficamos?
Grafos
Grafos são um conceito extremamente antigo (a primeira menção a isso remonta a Leonhard Euler em 1736) de armazenamento e visualização de dados e suas relações. Basicamente um grafo é composto de duas partes básicas:
- Nó: O nó é o representante de uma entidade do sistema, por exemplo, um usuário, um role, um scope
- Arestas: As arestas são os relacionamentos em si
Este é o exemplo de um grafo simples:

Aqui temos dois nós, 1 e 2 que estão conectados através de uma relação de “FOLLOWS”, que possui uma propriedade since que diz desde quando aquela pessoa 1 segue a pessoa 2. Perceba que os nós também podem ter propriedades, e além disso, podemos definir labels para cada um dos nós. Então, como estamos falando de pessoas, poderíamos ter um nó alice:Person, onde alice seria o identificador do nó e Person seria a categoria, ou a label deste nó. Então, podemos montar um grafo simples, como:
Ou, então, algo mais complexo, como:

Para dar uma noção da importância de grafos, hoje, principalmente, eles são muito utilizados em diversas aplicações reais, principalmente em logística (veja o problema do caixeiro viajante) e até mesmo na Internet, que, se pensarmos bem, é um grafo gigante e roteadores se utilizam de algoritmos de menor caminho (como Dijkstra) para encontrar o menor caminho entre outros roteadores até o IP de destino.
Com estes dois conceitos básicos nós já podemos mudar a forma como armazenamos os nossos dados de forma radical, isto porque nós estamos dando muita enfase para os relacionamentos, e não só para os dados que temos.
Neo4J
Durante muito tempo tivemos o conceito de grafos, mas não aplicamos ele à tecnologia na forma de armazenamento ou de definição de dados. Até que criamos os chamados bancos de dados orientados à grafos. Estes bancos de dados armazenam fisicamente não só os dados, mas também suas relações, de forma que se tornam muito mais rápidos e muito mais eficientes do que um banco de dados relacional normal.
O Neo4J é um de muitos exemplos de bancos de dados orientados à grafos. Criado em 2007, ele se tornou rapidamente o banco mais utilizado no seguimento, e também um dos mais rápidos. Isto se dá por conta de que o Neo4J é o que chamamos de “grafo nativo”, ou seja, fisicamente, na memória, os nós e relacionamentos apontam uns para os outros. Isso cria o que é chamado de adjacência livre de índices (index-free adjacency) e, desta forma, os sistemas de grafos nativos, como o Neo4J, podem fazer uma query através de travessias de grafos, pulando de um endereço para outro na memória de forma absurdamente rápida. Na verdade, o chamado pointer hoping é a forma mais rápida de um computador acessar um dado relacionado. Você pode ver mais detalhes sobre este tema neste excelente artigo.
O outro tipo de banco orientado a grafos é o chamado “grafo não nativo”, que se apoiam sobre bancos de dados relacionais ou não relacionas já existentes para que possam gerenciar seus relacionamentos. Em outras palavras, eles tem uma representação de um grafo em forma de tabelas ou documentos, o que os torna cerca de 1000x mais lento do que um grafo nativo, somente pelo fato de que a maioria dos dados que precisamos acessar não está diretamente carregado na memória.
Por que grafos?
Naturalmente, você deve estar pensando: “Por que eu deveria usar grafos, se eu já tenho meu banco de dados aqui?”. Além da velocidade de execução de queries (no site do Neo4J, é dito que uma query demora “o tempo de um tweet”), a flexibilidade e a facilidade de modelagem são muito maiores do que um banco tradicional.
Você deve estar pensando “Flexibilidade? Facilidade de modelagem?”, justamente, um banco de grafos é muito mais flexível porque você pode mudar o schema todo do banco ou, então, alterar qualquer atributo ou valor que você precise de fato alterar os dados existentes, porque cada relacionamento e nó é único e separado. Agora, em termos de facilidade de modelagem, pense o seguinte: Vamos modelar uma rede social igual ao Twitter.
Primeiramente, temos a relação inicial, a mais fundamental de todas: “Um usuário pode seguir outro usuário e ser seguido”. Agora, imagine esse relacionamento na sua cabeça. Você pensou em um grafo, não é mesmo? Um pequeno círculo apontando para outro círculo com uma label “Segue” entre eles. Pois é, naturalmente, o cérebro humano pensa em termos de relacionamentos entre coisas, então é muito mais simples você modelar um grafo, porque você pode simplesmente pensar no que você quer e ele já estará modelado!
Além disso, qualquer dado pode ser modelado em termos de grafos, de forma que você poderia também utilizá-lo para tarefas mais corriqueiras como armazenamento de usuários ou outras funcionalidades que teríamos delegado a um banco relacional ou não relacional logo de cara. Então, por que não fazemos isso?
Prós e contras
Acredito que os prós foram muito explicados nos parágrafos anteriores, certo? Temos velocidade, flexibilidade, facilidade de modelagem. Além disso, temos uma agilidade bastante incomum para bancos relacionais em queries, pois elas executam absurdamente rápido em um ambiente onde tudo já está carregado na memória.
Infelizmente, por não ser ainda um modelo muito difundido, os bancos de grafos não contam com bibliotecas ou suportes muito grandes. Apesar de o Neo4J, por exemplo, ter bibliotecas para a maioria das linguagens mais utilizadas, estas bibliotecas ainda precisam de alguns ajustes finos, principalmente no que diz respeito a queries.
Além disso, não existem hoje boas ou excelentes ferramentas de visualização para este tipo de grafo que possam ser distribuídas em larga escala para o front-end, sem divulgar dados sensíveis como usuários e senhas do banco. Isto porque a maioria das bibliotecas boas (como o NeoVis.js) precisam das credenciais do banco para montar o canvas com um grafo. E outras como o D3.js e libs de charting mais genéricas tem uma API bastante controversa para manipulação deste tipo de dado. Porém, dado que a exibição de um grafo em forma de grafo é somente para visualização e, raramente, apresenta algum valor analítico, então estamos bem com a representação em forma de JSON ou tabelas que o Neo4J também nos proporciona.
Em suma, os prós ultrapassam os contras, principalmente quando falamos de escala, pois um grafo “grande” no Neo4J é considerado um grafo com mais de 2 bilhões de nós, ou seja, este modelo de grafos pode escalar muito se você tiver a infra para suportá-lo.
Conclusão
Para não alongar este artigo ainda mais, vou quebrá-lo em várias partes. No próximo artigo, veremos como podemos iniciar com Neo4J, instalá-lo e começar a inserir nossos próprios dados e criar nosso próprio grafo!
Até mais!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?