



7 motivos para não usar chaves compostas
No seguinte artigo, o autor lista sete motivos importantes para não usar chaves compostas.

Peguei pesado no título, certo? Foi de propósito. É para gerar emoção mesmo. Provavelmente muitos atirarão pedras, mas às vezes precisamos expor nossas ideias, principalmente quando temos algumas convicções. Mas serei bastante racional e apoiarei minhas considerações em autores consagrados como Eric Evans, Martin Fowler, além de vivências próprias.
Provavelmente você conheça pessoas que defendam chaves primárias simples, e outras pessoas que defendam chaves primárias compostas com unhas e dentes. Neste artigo, vou tentar apresentar argumentos técnicos pelos quais eu acredito que o uso de chaves primárias simples facilita o desenvolvimento e a manutenção de sistemas complexos.
Para começar, vamos imaginar um cenário (parcial). Um sistema acadêmico, onde temos o conceito de aluno, contrato, turma, matrícula, curso, disciplina e outros. Um aluno pode ter um contrato, que por sua vez vincula o aluno a um curso.
Vamos supor que existe uma regra de negócio, que diz que um aluno só pode ter um contrato com cada curso. Assim, se ele sai do curso e volta para o curso, estamos falando do mesmo contrato que é reativado. O contrato vincula, então o aluno a um curso e possui matrículas, que são registros que vinculam aquele contrato às turmas.
Uma matrícula é o registro daquele aluno (que é representado pelo contrato) em uma turma. A matrícula não está diretamente vinculada à pessoa, pois para a montagem do histórico escolar é preciso saber de qual curso (contrato) ela se refere. A matrícula está vinculada a uma turma, que representa a ocorrência de uma disciplina dentro de um semestre.
Obviamente o sistema está incompleto, faltam muitos atributos, relações e outros. Por exemplo, teríamos que vincular as disciplinas aos cursos (N-N), mas isso não colabora para o entendimento dos propósitos deste artigo. Então vamos simplificar as coisas.
Modelo de referência usando chaves simples
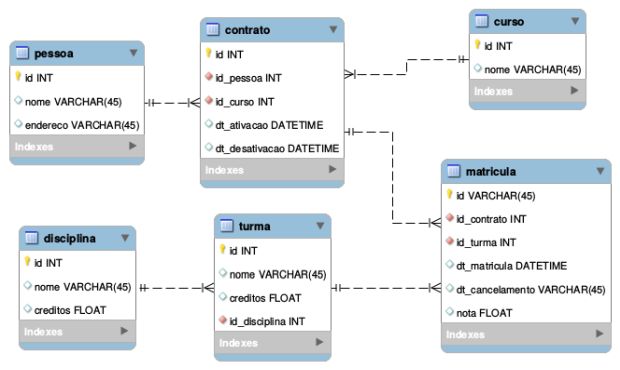
Primeiro vamos ver como seria o modelo usando chaves primárias simples. Veja que cada tabela necessariamente possui um ID para identificar uma linha de registro naquela tabela. Então sempre que precisarmos realizar uma operação sobre uma matrícula. Por exemplo, bastaria sabermos o ID do registro.
A relação para o contrato é realizada por uma chave estrangeira simples, bem como para a turma. Podemos ainda criar um índice único (unique index) para as chaves estrangeiras, para fazer com que o próprio banco impeça a inserção de combinações repetidas de registros (contrato+turma).
O que não escolher como chave primária
Ao modelarmos as classes de um sistema, algumas delas são Entities, outras Value Objects e algumas Aggregates. Para Evans, um objeto do tipo Entity é um objeto que possui uma identidade única, que dura em seu ciclo de vida. Os atributos de uma pessoa, por exemplo, podem mudar, mas sua identidade permanece. Uma Entity pode ser uma pessoa, um contrato, uma matrícula, etc.
Uma Entity pode ser transmitida por um Web Service, armazenada e obtida no Banco de dados múltiplas vezes. Em cada processo, um novo objeto é instanciado na memória. O que mantém a identidade é um atributo único e imutável, que pode ser garantido também em banco de dados.
Muitas pessoas são tentadas a usar atributos do mundo real como chave de um objeto. Identificar uma pessoa pelo CPF, uma empresa pelo CNPJ, um livro pelo ISBN são alguns exemplos. Mas por que evitar essas estratégias que utilizam atributos do mundo real para identificar objetos?
Um objeto deve ser identificado de maneira única e imutável. Caso contrário, o que seria de seu banco de dados se as chaves ficassem mudando toda hora? Impensável. Mas por que campos como CPF e CNPJ mudariam? Eu explico. Eles representam uma pessoa (física ou jurídica) perante nosso sistema de registros do Brasil, e não identificam unicamente aquela pessoa no universo.
Assim sendo, o Brasil pode mudar seu sistema de registros e codificações, mudando também os valores dessas chaves, e até seus nomes. Assim, sua base de dados ficaria suscetível a essas mudanças. Imagine você tendo que dar Update em várias tabelas que referenciavam o CPF da pessoa, que nem se chama mais CPF, e agora possui uma outra estrutura e formato.
Então, para evitar esses problemas, lembre-se de que uma chave deve ser única e imutável. Para garantir essas condições, e vincular os registros da base de dados de maneira que a estrutura não precise passar por mudanças futuras devido a mudanças na maneira como o mundo real identifica aquele objeto, utilize chaves artificiais (surrogate), geradas pelo próprio banco (auto_increment), numéricas. Assim, você garantirá que estas não sofrerão mudanças, o que trará maior estabilidade para a estrutura (relações de chave primária e chave estrangeira).
O amigo Elton Minetto acrescenta ainda que “uma grande tendência é a utilização de UUIDs para campos de chave, evitando usar os auto_increment dos bancos de dados”. Para ele, UUIDs “ajudam a migrar de banco ou mesmo ter bancos distribuídos em algum momento do projeto”. O amigo Renato Mendes Figueiredo complementa ainda que UUIDs “aliviam a carga do banco de gerar ids e fazem com que a aplicação não se preocupe com ordem ou unicidade”.
Modelo de referência usando chaves compostas
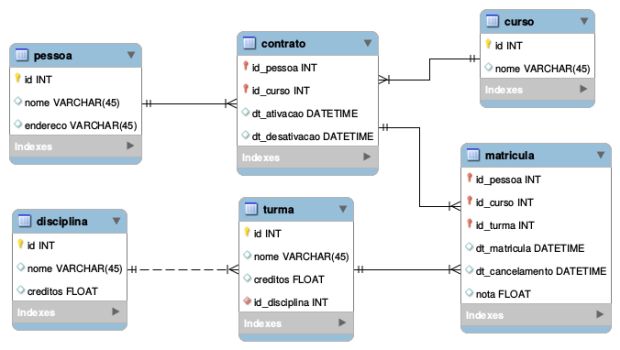
Mesmo que você persista na ideia de usar chaves primárias compostas, nessa versão do modelo teríamos algumas mudanças. As tabelas mais simples (pessoa, disciplina, curso) continuariam da mesma forma, pois elas somente possuem um atributo para identificação, de qualquer maneira.
A coisa começa a mudar para contratos. Como um contrato é único pela combinação pessoa+curso, ele teria uma chave primária composta por id_pessoa e id_curso. Assim, sempre que quisermos realizar alguma operação sobre o contrato, precisaríamos informar as duas chaves. O mesmo ocorre com a matrícula, que antes tinha a chave do contrato e da turma.
Como a chave do contrato é composta, agora ela é representada por uma chave composta tripla (pessoa, curso, e turma), para evitar que essa combinação se repita. E sempre que quisermos realizar alguma operação sobre um registro de matrícula (select, update), todas chaves deverão ser informadas.
Agora voltamos para a motivação original deste artigo. Motivar o leitor a construir sistemas com o uso de chaves primárias simples, não compostas. Procuramos organizar os motivos em tópicos para facilitar a discussão, e também a visualização das razões.
1. A persistência é muito mais simples
Um Design Pattern consagrado para implementar a persistência de uma Entity é um Active Record. Para Fowler, um Active Record é “um objeto que representa uma linha de uma tabela, encapsula o acesso aos dados e adiciona lógica de domínio”. Active Record é possivelmente o padrão de projetos mais utilizado em camadas de persistência por sua facilidade de uso.
A seguir, temos um exemplo onde carregamos o objeto Contrato para a memória, baseado em seu ID. Pense na facilidade que é o mapeamento entre um registro da base de dados e a memória com um campo único e simples para identificar aquele objeto.
Agora imagine o carregamento deste objeto a partir de vários atributos que o identificariam ao trocarmos para chaves compostas. Você pode recorrer a outros padrões como Data Mapper, mas aí a brincadeira não é tão divertida, pois cada classe demandaria de um mapper para ela, ou seja, mais código para dar manutenção.
<?php $contrato = Contrato::find($param[‘id’]); $contrato->dt_desativacao = date(‘Y-m-d’); $contrato->save(); ?>
Uma das premissas para utilização do Active Record é outro padrão chamado Identity Field. Para Fowler, um Identity Field “salva um campo de ID do banco de dados no objeto para manter a identidade entre o objeto da memória e a linha no banco de dados”.
Enquanto no Banco de dados utilizamos chaves primárias para referenciar registros, na memória, usamos ponteiros (variáveis) para referenciar objetos. Para manter a relação entre Banco de dados e memória, é necessário um campo de identificação que deve ser preservado em memória, para saber que quando for atualizado no banco, trata-se do mesmo registro, não um novo. Geralmente, os mecanismos de persistência se dão muito melhor com chave única, não composta. Lembre-se de usar uma chave sem significado (surrogate), menos suscetível à mudanças do mundo real.
2. Cache de objetos (Identity Map)
Há alguns anos, tínhamos um problema de performance em um cliente, a Universidade Univates. Durante a matrícula haviam cerca de 5 mil alunos fazendo o processo simultaneamente (simultaneamente mesmo), sendo que o processo carregava muitos objetos para a memória para fazer cálculos financeiros, registros de matrículas e mais uma série de regras de negócio. O servidor estava no limite e aumentar o hardware era uma opção existente, porém cara.
Verificamos que alguns objetos (como os de configuração) eram carregados inúmeras vezes durante uma mesma matrícula. Resolvemos criar um cache de objetos em memória RAM usando a tecnologia APC do PHP. Assim, uma vez que o objeto fosse carregado do banco, ele ia para o cache.
Em requisições posteriores, buscávamos sempre do cache em primeiro lugar. Apenas uma tabela era consultada 250 vezes nesse processo, visto que era uma tabela chave/valor usada para buscar diferentes parâmetros de configuração.
Mas aplicamos esta técnica também para tabelas de cursos, de cidades, de pessoas. Essa técnica poupou milhares de consultas no banco por processo de matrícula, e milhões de consultas ao longo de um mês. Não foi necessário fazer upgrade de hardware, e o processo ficou muito mais fluido, visto que o tempo de consulta no cache era ínfimo perto do tempo de consulta no banco de dados relacional.
Essa técnica é descrita por Fowler no Design Pattern Identity Map. Para Fowler, um Identity Map “garante que cada objeto é carregado apenas uma vez, armazenando-o em um mapa. Procura pelos objetos no mapa quando necessário referenciá-los”.
O buscador do Identity Map, busca no mapa, geralmente pela PK (surrogate). Poupa recursos, carrega somente uma versão do objeto por transação. Quando vai carregar do BD, primeiro verifica o mapa. Se não está no mapa, coloca no mapa.
// Abre transação Curso::find($curso_do_aluno); // se não está no cache, carrega e põe no cache Curso::find($curso_do_aluno); // carrega do cache Curso::find($curso_do_aluno); // carrega do cache // Fecha transação
Você perguntaria: por que alguém carregaria o mesmo objeto várias vezes? Perceba que não estamos falando de um mesmo método, mas métodos de diferentes classes, executados dentro da mesma transação. Métodos que carregam um objeto que já tenha sido carregado anteriormente, na mesma transação, ou até mesmo por outro usuário em outra transação.
Imagine um programa de matrículas onde precisaremos do objeto Curso em diversos lugares, como em registros acadêmicos e registros financeiros. Este objeto Curso seria carregado N vezes para apenas um aluno durante o processo de matrícula. Ao utilizarmos cache, este objeto não seria mais carregado da base de dados, e sim do cache, por todos alunos que se matriculassem naquele curso. Além disso, funcionários administrativos, ao realizarem operações de retaguarda (relatórios, operações de registro acadêmico) também utilizariam a versão cacheada do registro, tornando todo o sistema mais rápido e fluido.
Ferramentas de cache, como o APC e o Redis, operam geralmente no padrão chave-valor. Agora imagine a complexidade da implementação de cache com chaves compostas. Veja que neste tipo de implementação (chave simples), a própria chave primária simples identifica o objeto no cache.
Referências
3. Manutenção de cadastros
Formulários
Agora imagine operações básicas no dia a dia como o formulário de cadastro de um objeto. Ao trabalharmos com chaves primárias simples, fica muito simples decidir se realizaremos um Insert ou Update na ação de salvar do formulário.
Imagine que estamos cadastrando um contrato novo. Se o objeto possui um ID, executamos um Update, caso contrário, executamos um Insert na base de dados. O Insert em um campo de chave primária serial/sequência é mais simples, pois basta não informarmos este campo que o banco usa o auto increment (ex: PostgreSQL).
Mas com chaves compostas, precisamos antes consultar o banco de dados com um critério combinado (ex: id_pessoa + id_curso) para verificar se aquele registro existe antes da gravação.
if (empty( $object->id ))
{
insert...
}
else
{
update...
}
Datagrids
Agora imagine uma datagrid com listagem de contratos. Você tem uma datagrid com ações (ex: cancelar, reativar, excluir). Ao trabalharmos com chaves primárias simples, basta passar um campo somente pela URL (GET) para identificar o contrato que aplicaremos à ação.
Ao trabalharmos com chaves primárias compostas, precisamos passar mais campos pela URL (id_aluno + id_curso) para identificar o mesmo registro a ser manipulado. Além disso, o tempo de carregamento com filtro por campo único, em situações normais de temperatura e pressão, é menor do que o tempo de carregamento com filtro por mais de um campo (chave composta).
Agora imagine manutenção de registros pelo terminal. Alguém fez alguma coisa errada e você precisa corrigir isso pelo console. Pode ser um Update ou um Delete, mas sobre alguns registros. Com chaves primárias simples você pode fazer do jeito que está a seguir. Agora imagine como seria dar manutenção nesses registros específicos com chaves primárias compostas.
// excluir alguns registros errados DELETE from contrato where ID IN (5000, 5020, 5030); // corrigir alguns registros UPDATE matricula set dt_cancelamento=NULL where ID IN (40300, 40301);
Widgets
Agora imagine que você precise fazer uma Combo (SELECT) para listar os contratos de um aluno, para selecionar o contrato sobre o qual fará uma operação. Geralmente esses componentes visuais (Widgets) estão preparados para uma chave (ID) e um valor (ex: outros campos concatenados). Mas se o contrato possui chave composta, qual será a chave da Combo? Aí você começará a contornar a situação concatenando os campos e fazendo um parsing para no outro lado do Post, desmembrar os campos.
4. Proliferação de campos na estrutura
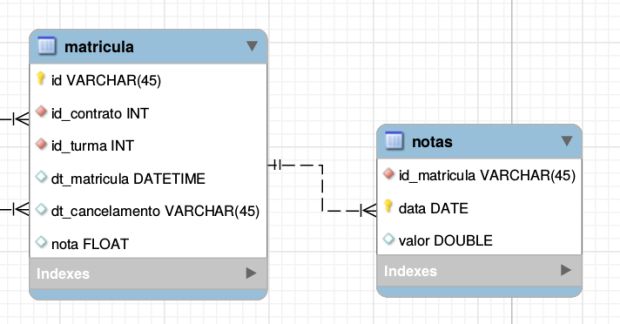
Agora imagine que o aluno não tem mais somente uma nota por matrícula, e sim várias. Então você precisa criar uma tabela que referencia a tabela de matrículas. No modelo de chave primária simples, você precisa adicionar uma única chave estrangeira, e registrar a data e o valor da nota.
Já no modelo de chave primária composta, você precisa adicionar três chaves estrangeiras, uma vez que são as três que identificam unicamente uma matrícula.
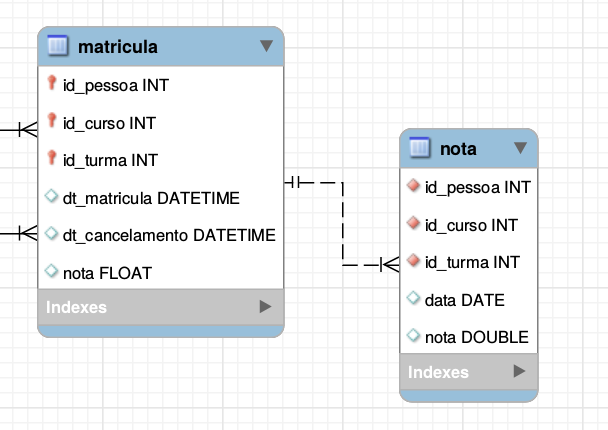
Você percebeu que houve uma proliferação de chaves. Esse cascateamento de chaves só tende a piorar com o tamanho do banco. Mais tabelas, mais chaves, e mais Joins em consultas.
5. Consultas com Joins
Agora, imagine que você precisa construir relatórios com queries, cruzando várias tabelas, pois você precisa pesquisar dados de diferentes lugares. Ao utilizarmos chaves primárias simples, temos ligações mais simples em Joins de queries também.
Ao utilizarmos chaves primárias compostas, temos mais campos para lembrar ao fazer as ligações. Devido ao nosso modelo ser minimalista, esta diferença não ficará tão evidente quanto gostaríamos, mas a medida em que o sistema se torna maior, as diferenças se tornarão maiores.
Aqui veja que a tabela de matrícula se ligará com contrato por apenas um campo de ligação.
SELECT pessoa.nome,
disciplina.nome,
matricula.dt_matricula,
matricula.nota
FROM pessoa, contrato, matricula, turma, disciplina
WHERE pessoa.id = contrato.id_pessoa
AND contrato.id = matricula.id_contrato
AND matricula.id_turma = turma.id
AND turma.id_disciplina = disciplina.id
AND turma.id = 5003;
Aqui veja que é necessário conectarmos cada um dos campos de chave estrangeira.
SELECT pessoa.nome,
disciplina.nome,
matricula.dt_matricula,
matricula.nota
FROM pessoa, contrato, matricula, turma, disciplina
WHERE pessoa.id = contrato.id_pessoa
AND contrato.id_pessoa = matricula.id_pessoa
AND contrato.id_curso = matricula.id_curso
AND matricula.id_turma = turma.id
AND turma.id_disciplina = disciplina.id
AND turma.id = 5003;
Em princípio, vimos que serão necessários mais Joins. Mas além disso, no quesito performance, note que mais Joins são necessários para obter o mesmo resultado. Ao utilizarmos chaves primárias simples, os índices acabam sendo mais compactos, o que privilegia as estratégias de busca.
6. Logs de alterações de registros
Hoje em dia é quase impensável construirmos uma boa aplicação de negócio sem logs. Nas nossas aplicações, no mínimo fazemos logs de acesso (login, logout), logs de SQL executados (Insert, Update), e logs de alteração de registros. Os logs de alteração de registros armazenam o estado de um objeto antes e depois da alteração.
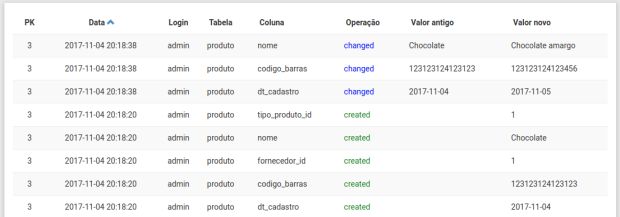
A tabela a seguir apresenta os logs de alteração. Veja que temos uma estrutura bem simples com: chave do registro alterado, data da alteração, login do usuário, tabela, nome da coluna, operação realizada, valor antigo, e valor novo. A estrutura é sempre essa, independente da tabela, e do campo a ser logado.
Para implementar este Log, também é bastante simples. Como utilizamos um Active Record, o próprio objeto realiza a comparação com seu estado prévio antes da gravação na base de dados.
Agora, como realizaríamos o registro de logs de registros que possuem chaves compostas? Criar várias colunas para identificação seria inviável, pois o número de colunas que identifica um registro usando chave composta é variável por tabela.
Teríamos de novamente contornar a situação fazendo com que a coluna de identificação seja alguma coisa serializada ou concatenada. Caso optássemos por fazer dessa maneira, como você localizaria facilmente esses logs depois? Imagine que precisa identificar todas alterações em um contrato específico. Vai pensando.
7. REST API
Boa parte das API’s REST são construídas seguindo o padrão apresentado na tabela a seguir, onde o recurso a ser manipulado é identificado única e exclusivamente por um ID simples. Veja que nem ao menos o nome do atributo (ID) identificamos. Agora imagine que precisamos obter os dados de um contrato via API (operação GET por ID). Ao trabalharmos com chave simples, a operação também é simples GET https://dominio/contrato/1.
| Método | Exemplo | Descrição |
| GET | https://dominio/pessoas | Lista todas as pessoas |
| GET | https://dominio/pessoa/1 | Lista apenas pessoas com id = 1 |
| POST | https://dominio/pessoas | Para cadastrar pessoas |
| PUT | https://dominio/pessoa/1 | Para editar pessoas |
| DELETE | https://dominio/pessoa/1 | Para apagar pessoas |
Agora imagine como ficaria a chamada com o contrato representado por chaves primárias compostas. Teríamos que definir rotas formadas por vários atributos que identificam o objeto, o que não é a linguagem comum do universo REST.
Complicou, né? É claro que você vai encontrar uma saída, mas pense bem, ela poderá ser mais um “contorno” em seu projeto. O default todo mundo implementa, o diferente possivelmente gerará mais um trabalho extra não esperado.
| Método | Exemplo | Descrição |
| GET | https://dominio/contrato/53/87 | Contrato do aluno 53, curso 87 |
| GET | https://dominio/contrato?aluno=53&curso=87 | Contrato do aluno 53, curso 87 |
A segunda ideia é ruim, pois vincula (acopla) o resource com o schema da base de dados.
O amigo, Renato Mendes Figueiredo, acrescenta também que “no caso do restful tem uma desvantagem também, criar todos os resources com um modelo de dados muito segmentado faz com que diversas calls sejam necessárias na API para criar todo o modelo de dados”.
Considerações finais
Neste artigo procurei apresentar padrões de projeto de dois dos mais respeitáveis engenheiros de software do mundo: Eric Evans e Martin Fowler, além de exemplos bem práticos que trabalhamos no dia a dia.
Meu objetivo com este artigo é mostrar que o somatório de detalhes podem fazer uma grande diferença. Ao implementarmos um sistema grande, temos que eliminar pequenos obstáculos e facilitar nossa vida, não complicá-la.
É possível utilizarmos tanto a abordagem de chaves primárias simples, quanto compostas. Mas veja que ao escolhermos chaves primárias simples, teremos vários atalhos, facilidades. Essas facilidades se traduzem em ganho de tempo, código mais enxuto, e menos dor de cabeça tentando adaptar técnicas que nasceram para ser simples, não complexas.
Gostaria ainda de agradecer os amigos Renato Mendes Figueiredo e Elton Minetto pelas contribuições preciosas.
***
Este artigo foi publicado originalmente em: pablo.blog.br
Graduado em Análise de Sistemas e Mestre em Engenharia de Software pela Unisinos. Autor de livros sobre PHP e palestrante em eventos sobre o tema desde 2002. Pioneiro em PHPOO no Brasil.



