

No Asaas, estamos vivendo um momento importante de evolução técnica. Nosso sistema cresceu, a operação ganhou escala, os produtos evoluíram e a complexidade do sistema aumentou junto com o negócio. Esse movimento é natural, mas traz um desafio importante: como continuar evoluindo com segurança, resiliência e autonomia dos times sem comprometer a estabilidade da plataforma?

É a partir desse contexto que entra a arquitetura celular.
Arquitetura celular é um conceito que costuma gerar curiosidade justamente por não ser um modelo tão difundido quanto outros padrões arquiteturais mais conhecidos. Além disso, em muitos casos, isso já está resolvido e o time acaba nem entendendo o funcionamento por trás do que usa. Por isso, antes de entrar nos detalhes técnicos, vale contextualizar por que esse tema se tornou tão relevante para nós.
Neste artigo, compartilhamos como esse conceito funciona na prática, quais problemas ele ajuda a resolver e por que estamos evoluindo nossa arquitetura para esse modelo no Asaas, conectando decisões técnicas com crescimento sustentável, experiência dos times e maturidade de engenharia.
Antes de tudo: o problema que queremos resolver
Durante muito tempo, escalar sistemas significou aumentar máquinas, dividir responsabilidades em serviços modulares ou aplicar técnicas como sharding de banco de dados. Essas abordagens resolvem parte do problema, mas frequentemente introduzem outros desafios.
Em arquiteturas tradicionais de escala, é comum observar que clientes insatisfeitos degradam a experiência de todos. O sistema cresce, mas a previsibilidade e a resiliência diminuem.
A arquitetura atual do Asaas é robusta e estável, mas à medida que crescemos, queremos garantir que continue sustentando o negócio com a mesma qualidade. Arquitetura celular é nossa evolução, para buscarmos o seguinte:
Preparar para escala:
- Crescimento horizontal e previsível adicionando células conforme necessário
- Bancos de dados menores e mais performáticos
- Processamento distribuído sem contenção entre clientes
Aumentar resiliência:
- Blast radius controlado: problemas afetam apenas uma fração da base
- Deploys graduais e seguros, célula por célula
- Falhas contidas, sem cascata para todo o sistema
Otimizar recursos:
- Infraestrutura dedicada para clientes com perfis muito diferentes
- Configurações e otimizações específicas por célula
- Melhor utilização de recursos, sem superdimensionamento global
Empresas como a Shopify sentiram isso de forma prática. Em 2015, ao escalar seu banco de dados por meio de sharding, conseguiram ganhos de performance, mas perderam resiliência. Uma falha em um único shard era capaz de indisponibilizar toda a plataforma. A resposta foi reorganizar a arquitetura em pods totalmente isolados, capazes de operar de forma independente.
A arquitetura celular nasce exatamente desse tipo de aprendizado.
O que é arquitetura celular
Uma arquitetura celular organiza o sistema em células independentes, onde cada célula é responsável por processar um grupo de requests, manter seu próprio estado e operar de forma autônoma. O princípio central é simples, mas poderoso: em vez de escalar um sistema monolítico cada vez maior e mais complexo, escalamos adicionando células independentes. Quando precisamos de mais capacidade, criamos uma nova célula. Quando uma célula falha, o impacto fica contido.
Essa ideia não surgiu de um único lugar. Ela aparece em diferentes momentos da história da computação:
- O Actor Model, com comunicação baseada em mensagens e isolamento de estado
- O Domain-Driven Design e seus Bounded Contexts bem definidos
- Arquiteturas orientadas a eventos e message-driven systems
- O conceito de cell-based architecture difundido por provedores como a AWS
- Os pods da Shopify, um exemplo claro dessa lógica aplicada à prática em fintech
No fundo, todas essas abordagens apontam para o mesmo princípio: isolamento como estratégia de escala.
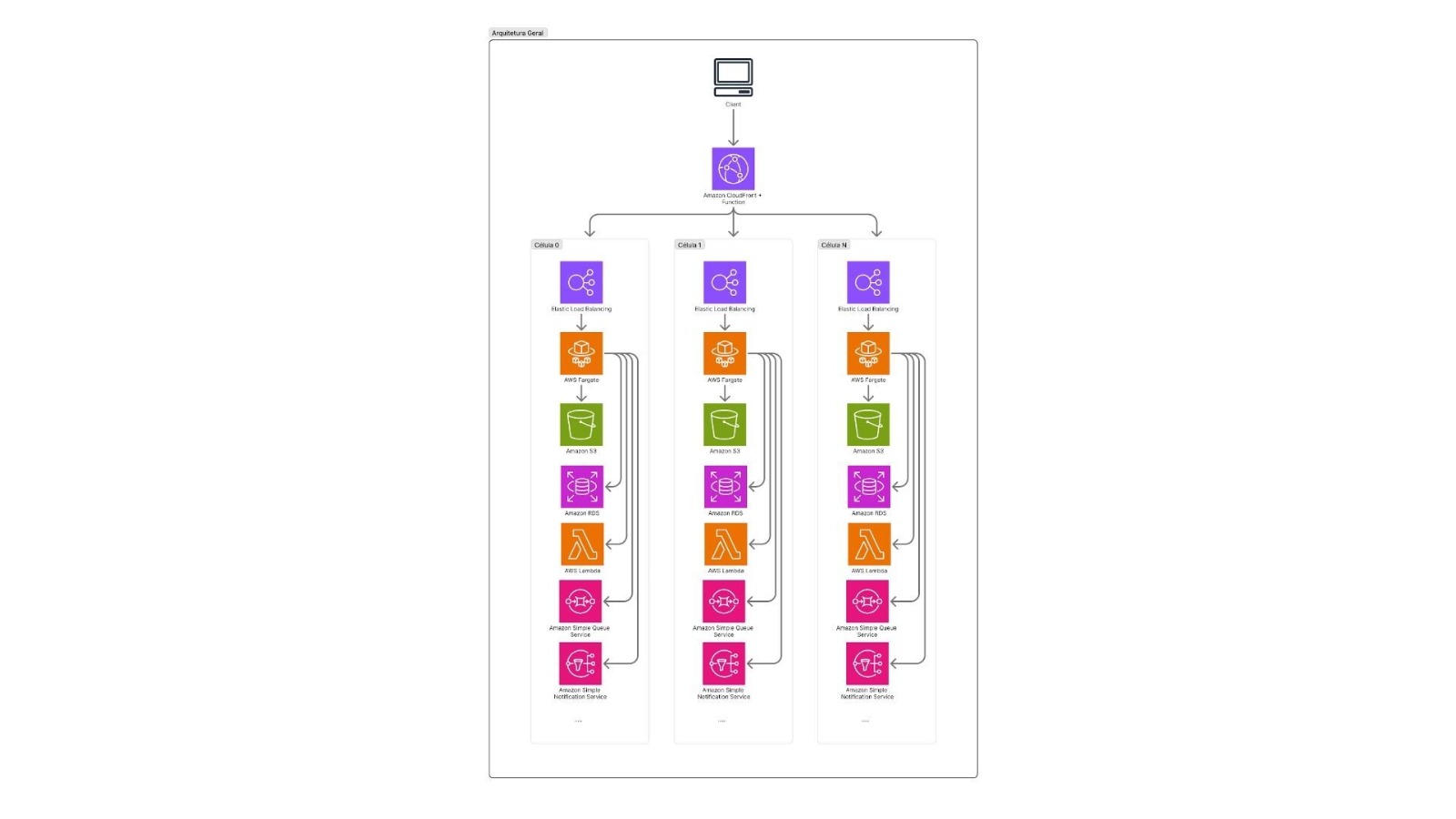
Como uma célula é composta no Asaas
No modelo que estamos construindo, uma célula arquitetural é uma unidade lógica completa e autossuficiente. Cada célula possui:
- Infraestrutura completa: toda a stack do Asaas Core replicada
- Banco de dados isolado: dedicado para aquela célula
- Processamento independente: aplicações, workers, filas e caches próprios
- Capacidade de operação autônoma: uma célula não depende de outra para funcionar
A segregação é feita por faixas de clientes. Por exemplo:
- Célula 0: clientes de 1 a 1.000.000
- Célula 1: clientes de 1.000.001 a 10.000.000
- Células especializadas: clientes detratores podem ser isolados em células dedicadas
O roteamento acontece no CloudFront, através de Functions que analisam o request (seja por identificador de cliente, token JWT ou contexto da requisição) e direcionam para a célula correta. Isso significa que o roteamento é transparente para o cliente, a experiência é a mesma, mas a infraestrutura subjacente é isolada.
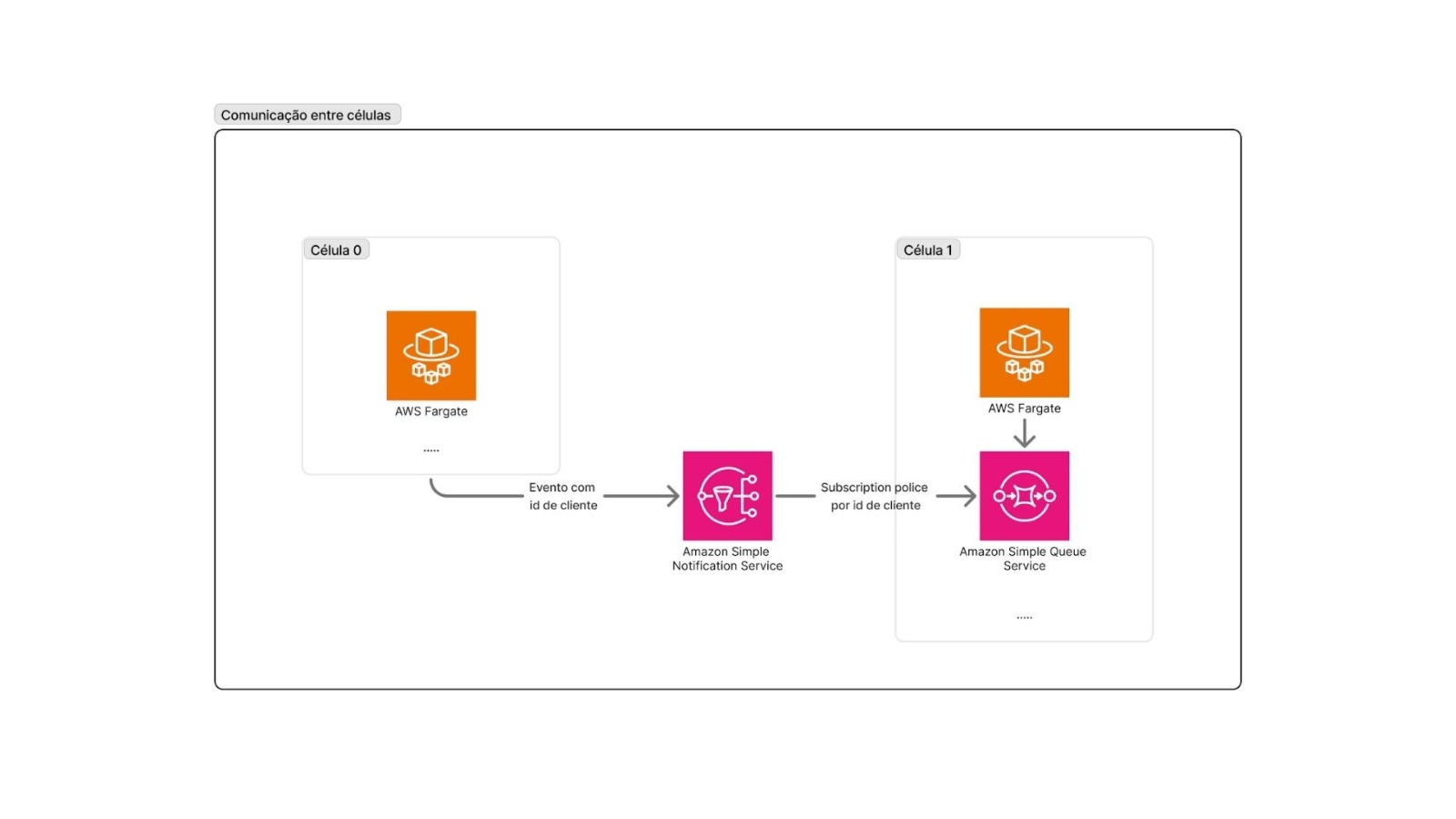
Comunicação entre células: eventos antes de tudo
Bancos isolados trazem um desafio importante: como lidar com operações que envolvem dados de clientes em células diferentes?
Exemplos práticos no Asaas:
- Buscar informações de um CPF/CNPJ que pode estar em qualquer célula
- Transferências entre contas Asaas de clientes em células diferentes
- Notificações e webhooks que precisam consultar dados cross-cell
A arquitetura celular não funciona bem quando há acoplamento síncrono excessivo entre componentes. Por isso, sempre que possível, a comunicação entre células acontece de forma assíncrona e orientada a eventos.
Utilizamos SNS + SQS para materializar esse padrão:
- Comandos acionam mudanças de estado dentro de uma célula
- Eventos comunicam que algo relevante aconteceu
- Outras células reagem apenas se tiverem interesse naquele fato
Esse modelo reduz dependências diretas e permite evolução incremental e segura. Você pode fazer deploy célula por célula, testar mudanças estruturais em produção com impacto limitado, e até manter células em versões diferentes durante migrações graduais. Chamadas síncronas podem existir, mas são exceção e passam por camadas de proteção como gateways ou proxies com circuit breakers e timeouts bem definidos.
Outro exemplo prático: transferência entre contas
Quando um cliente da Célula 0 transfere para um cliente da Célula 1:
- A Célula 0 processa o débito e publica um evento de transferência no SNS utilizando o conceito de outbox;
- SNS roteia para o SQS da célula destino;
- A Célula 1 consome esse evento via SQS e processa o crédito;
- Ambas as células mantêm consistência com mecanismos de retry e dead-letter queues para garantir a entrega.
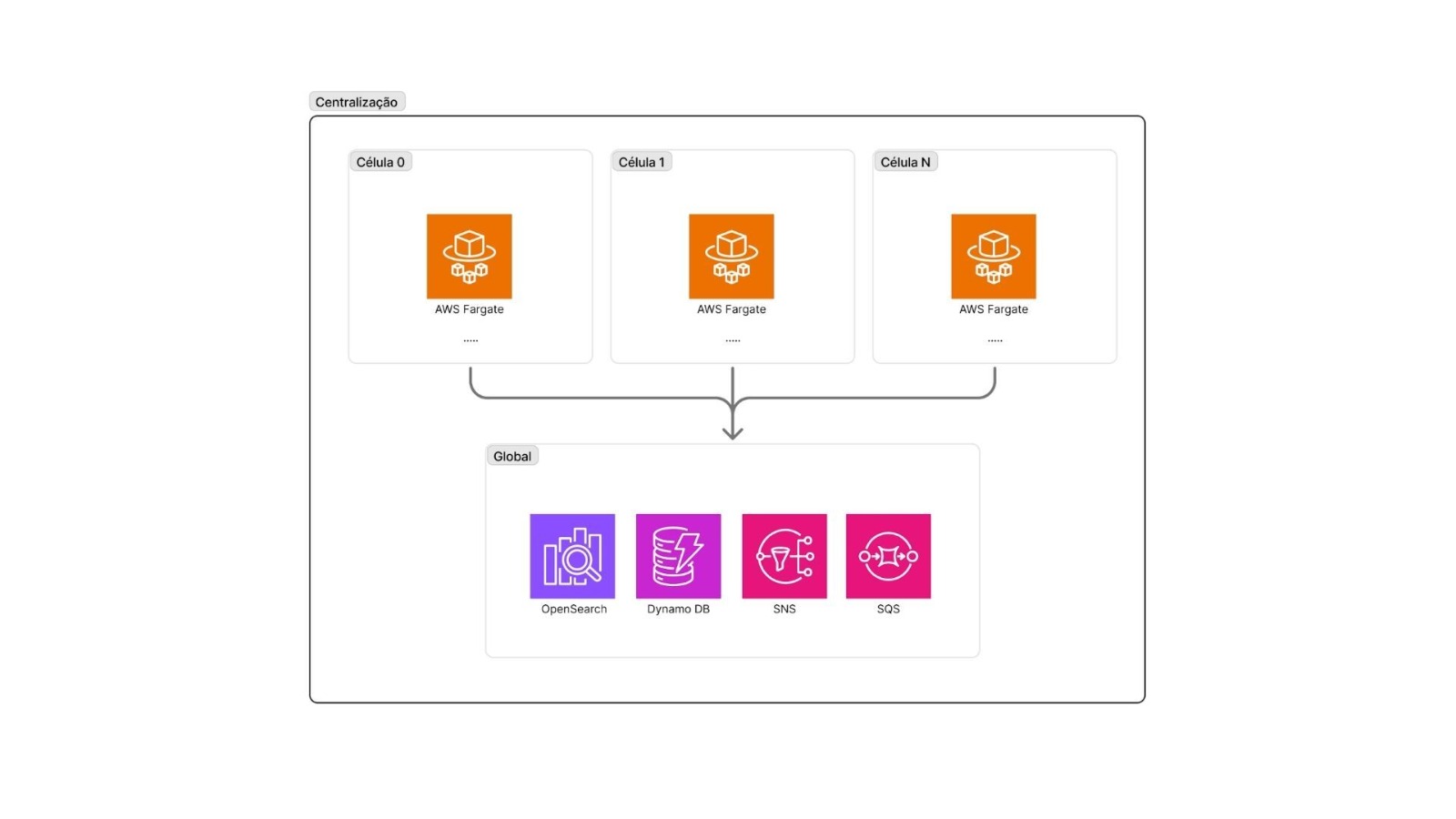
O desafio do backoffice: agregação de dados
Um backoffice que precisa consultar e manipular dados de todas as células apresenta um desafio arquitetural importante. Não queremos que operações administrativas criem dependências síncronas entre todas as células.
Nossa solução: OpenSearch como camada de agregação.
Cada célula replica os dados necessários para visualização (normalmente listas, dashboards e consultas analíticas) para um cluster OpenSearch centralizado. Quando um operador de backoffice:
- Lista clientes ou transações: a consulta vai para o OpenSearch
- Seleciona um item específico: o backoffice identifica a célula correta e faz a consulta direta
- Realiza uma operação: a ação é roteada para a célula responsável
Isso garante que o backoffice tenha visibilidade global sem criar acoplamento entre células. O OpenSearch não é a fonte da verdade, mas sim uma visualização otimizada para operações administrativas.
Dados centralizados: quando o isolamento não faz sentido
Nem tudo se beneficia do isolamento celular. Alguns dados precisam ser altamente íntegros, centralizados e de acesso ultrarrápido. O principal exemplo no Asaas é o processo de autenticação e autorização.
Para esses casos, utilizamos DynamoDB como store centralizado:
- Sessões de usuário
- Tokens de autenticação
- Permissões e ACLs
- Dados de routing (qual cliente pertence a qual célula)
O DynamoDB oferece latência consistente na casa dos milissegundos, alta disponibilidade e capacidade de escalar horizontalmente sem os trade-offs de consistência de bancos relacionais distribuídos.
Abaixo imagem exemplificando a centralização e agravação para backoffice e usuários:
O que isso muda na prática
Os ganhos da arquitetura celular são bastante concretos:
1. Contenção de falhas (Blast Radius Reduction)
Se uma célula falha, seja por bug, sobrecarga ou problema de infraestrutura, o impacto é limitado apenas aos clientes daquela célula. Os demais continuam operando normalmente.
2. Deploys graduais e seguros
Podemos fazer rollout de novas versões célula por célula, validando estabilidade antes de expandir. Se detectarmos problemas, o rollback é pontual.
3. Isolamento de performance
Um cliente com volume extremo de transações não degrada a experiência dos outros. Podemos até alocar células dedicadas para grandes clientes.
4. Escalabilidade incremental
O crescimento acontece de forma controlada: adicionamos novas células conforme necessário, sem precisar reestruturar o sistema inteiro.
5. Banco de dados gerenciável
Bancos menores significam backups mais rápidos, consultas mais eficientes, manutenções menos arriscadas e maior flexibilidade para otimizações específicas.
6. Autonomia dos times
Times podem evoluir features e realizar deploys em células específicas com menos coordenação e risco.
Desafios e trade-offs
Seria irresponsável apresentar arquitetura celular como solução mágica. Ela traz desafios próprios:
- Complexidade operacional: gerenciar múltiplas células exige automação, observabilidade robusta e processos bem definidos
- Consistência eventual: operações cross-cell precisam ser modeladas com cuidado
- Migração gradual: não se adota arquitetura celular da noite para o dia — é um processo incremental
- Custos de infraestrutura: replicar toda a stack aumenta custos (mas isso é compensado pela resiliência e performance)
- Debugging distribuído: rastrear operações que atravessam células exige ferramentas de observabilidade madura
Arquitetura celular como caminho, não como solução pronta
Arquitetura celular não é uma decisão pontual nem um padrão que se adota de uma vez só. Trata-se de um caminho arquitetural que exige clareza de domínio, disciplina técnica e escolhas conscientes ao longo do tempo.
No Asaas, essa evolução nasce da necessidade de sustentar um sistema cada vez mais crítico para milhares de clientes, sem abrir mão de resiliência, autonomia dos times e segurança operacional. Construir células nos permite crescer com mais previsibilidade, reduzir impactos de falhas e evoluir em performance.
Mais do que um modelo técnico, arquitetura celular é uma forma de pensar escala. Ela parte do princípio de que:
- Falhas são esperadas, não exceções
- Isolamento é um aliado, não um custo
- Autonomia dos componentes é fundamental para resiliência
Por que compartilhar isso?
Compartilhar essa visão faz parte do processo. Muitas empresas enfrentam desafios semelhantes à medida que crescem, e trocar aprendizados sobre arquitetura é uma forma de fortalecer o ecossistema como um todo.
Se você já trabalhou com arquitetura celular, tem dúvidas sobre a implementação ou está considerando esse modelo na sua empresa, adoraria ouvir sua perspectiva nos comentários. Quais desafios você enxerga? O que funcionou (ou não funcionou) na sua experiência?
Quer fazer parte dessa construção?
A arquitetura celular já está sendo construída no Asaas. Estamos buscando pessoas que queiram participar ativamente dessa evolução técnica, lidando com desafios reais de escala, resiliência e autonomia dos times.
Se você se interessa por arquitetura, gosta de resolver problemas complexos em escala real e quer fazer parte de um time que está redesenhando a base do produto para o futuro, esse desafio pode ser o seu próximo passo:
👉 Conheça a vaga de Engenheiro(a) de Software Full Stack Sênior (Arquitetura Celular) no Asaas

De 0 a 10, o quanto você recomendaria este artigo para um amigo?