


Atualmente, existem várias APIs em Node.js que trabalham com muito processamento, consulta em banco de dados relacionais e não relacionais, acesso em disco, serviços legados e inclusive outras APIs. Diversos fatores que geram tempo de requisição, banda e processamento nos deixam sujeitos a estruturas que, se mal planejadas, podem gerar um débito técnico no futuro, exigindo mudanças na arquitetura para melhorar a performance da aplicação. Outras vezes ficamos presos a serviços impostos pelo cliente e seus requisitos, o que nos impede de implementar algo mais estruturado.
Quando você percebe todos os detalhes da sua aplicação entende que podem existir processos que são realizados várias vezes e retornam dados que não são alterados com tanta frequência. A cada solicitação feita, como a leitura de um arquivo, serviços de terceiros ou banco, caímos em uma série de fatores que implicam em tempo, processamento e banda.
Uma situação, por exemplo, seria eu ter que acessar um arquivo e retorná-lo ao usuário. Neste caso, como já apresentado na literatura, a leitura de um arquivo é lenta e depende de diversas condições, entre tempo de Seek, o quão espalhado esse arquivo está no seu HD, entre outras.
Agora, imagine outra situação. Sua API precisa fazer uma requisição para cinco outros serviços que vão desde a uma request SOAP, consulta ao banco, serviços de terceiros e uma busca no Elasticsearch. Supondo que cada requisição demore 1000ms, precisaríamos de um tempo total de 5000ms para retornar a requisição.
No caso do Node.js, poderíamos utilizar algum pacote npm para que as requisições fossem chamadas em paralelo. Mesmo assim, se eu fizer a mesma requisição várias vezes na minha API e os dados dos outros serviços não forem alteradas constantemente, nossa aplicação realizará o mesmo procedimento várias vezes.

Não seria mais fácil nossa aplicação conseguir identificar que essa solicitação já foi feita e retornar os dados salvos em algum lugar, sem a necessidade de realizar tudo novamente?
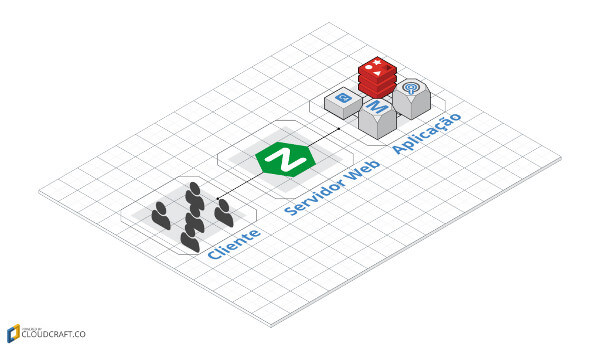
Sim! E podemos fazer isso de várias formas, mas o padrão mais conhecido é utilizando cache. O uso do cache pode ir de ponta a ponta em nosso sistema, seja na camada do cliente, do servidor web até depois, na aplicação.
Na camada do cliente, como um Browser por exemplo, deve-se criar uma forma capaz de coletar esses dados e salvar em alguma API do Browser, como as mais antigas utilizando cookie ou tecnologias um pouco mais novas como cache com Service Works, tecnologia muito usada atualmente com PWA.
Na camada do servidor web, no caso do Ngnix poderia ser adicionado o ETAG que ajudaria a identificar quando houve uma alteração naquela requisição e Expires/cache-control para tempo de vida que pode ser utilizado aquele conteúdo.
Na camada da aplicação, podemos fazer uma análise mais sucinta dos pontos que são possíveis de serem cacheados e o tempo de vida que cada requisição externa pode ter, garantindo melhor a integridade dos dados que serão repassados para o cliente. Podemos armazenar o cache na memória ou utilizar um serviço para isso.
Pontos Negativos
Na camada do cliente, mesmo criando estruturas que salvem esses dados, seria no mínimo necessário criar uma interface com a aplicação para identificar quando os dados ainda podem ser utilizados. Além disso, possuímos vários tipos de clientes. Falando somente de Browser, temos os mais antigos, que são difíceis de depurar, browsers de dispositivos móveis de versões antigas, além do suporte às APIs que cada um possui.
Na camada de servidor web podemos ter outro problema, como um controle generalizado de cache. Em um trabalho que participei tínhamos scripts de coleta de dados em e-commerces do Brasil, porém toda vez que atualizamos esse script, que estava salvo nos CDNs da Akamai, ele demorava cerca de um dia para ser propagado em todos os servidores, por conta do cache. Se ocorresse um erro, em épocas como a Black Friday, por exemplo, isso poderia ser um problema gravíssimo para a coleta dos dados que realizamos. Tudo seria perdido nesse dia.
Na camada da aplicação utilizar cache em memória também não é uma ideia tão favorável, pois uma boa prática é não salvar o estado de nada na API (Stateless). Seria uma complicação precisar escalar horizontalmente e conseguir manter a integridade desse cache.
Redis
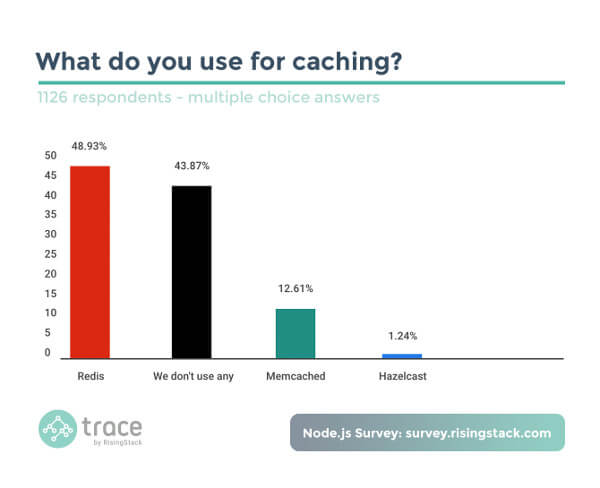
Uma das formas mais robustas de tratar esses empecilhos é ter uma qualidade melhor no cache, utilizando um servidor ou serviço. O mais comum atualmente é o Redis, que é um banco de dados NoSQL de chave e valor. Segundo um survey realizado pelo RisingStack com mais de mil desenvolvedores, essa ferramenta é adotada por quase 50% dos desenvolvedores que trabalham com Node.js, o que mostra a confiança deles nesse ecossistema.
Mas por que nte.escolher o Redis em vez do Memcached, plataforma que já está há muito tempo no mercado? Comparando os dois, ambos conseguem executar tarefas de cache com alta performance alocando tudo na memória, logo se ocorrer um problema e o servidor do memcached for reiniciado, o seu cache estaria a salvo em uma memória volátil. Com o redis o caso já é diferente, pois ele tem um fallback e salva tudo em disco. Ao ser reiniciado, seu cache voltará normalme
Outro ponto é se o Memcached não estiver aguentando a quantidade de dados alocados na memória, então será necessário aumentar o servidor verticalmente. O Redis tem a capacidade de trabalhar com cluster de até mil nós, crescendo tanto verticalmente como horizontalmente. O Redis também trabalha com PUB/SUB. Por exemplo, imagine que você tem o serviço A que faz uma chamada para o microsserviço B, o serviço A recebe os dados e depois cachea. No caso de o serviço B ser atualizado, ele avisaria o serviço A que houve uma alteração e que seria necessário limpar o cache com um canal de PUB/SUB. Todos os que estivessem escritos nesse canal seriam capazes de receber essa mensagem e limpar o cache.
O site oficial do Redis diz que ele é um Banco Open-Source que possui armazenamento de estrutura de dados em memória e realiza persistência em disco que pode ser utilizado também como fallback, caso ocorra algum problema no servidor. Possui estrutura de chave e valor e consegue salvar vários tipos de dados, desde uma simples string, como hash, até números, lista e outros. Possui a função tempo de vida para invalidar dados em um período de tempo, além de oferecer suporte a transações, oriundas dos bancos de dados relacionais, que respeitam o ACID.
O survey mencionado anteriormente mostra que 43% dos desenvolvedores de Node.js não utilizam nenhuma das ferramentas de cache citadas. Isso pode ser um indício de que muitos desenvolvedores não conhecem ferramentas de cache ou acham que a complexidade de inseri-las na sua stack pode comprometer o projeto. Depois da explicação, vamos agora criar uma aplicação Node.js que consome um banco de dados e a API do github que cria o cache com o Redis, tudo dockerizado, o que você pode acessar neste link do github.
Instalando dependências
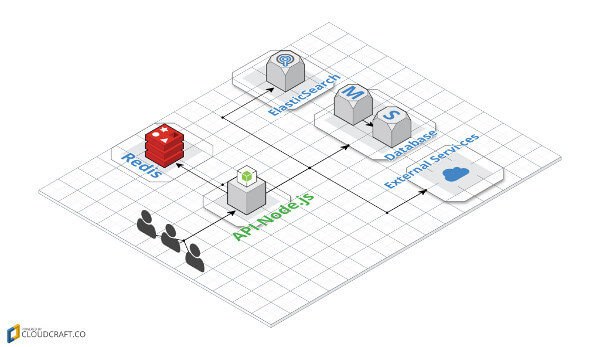
Esse projeto mostra um exemplo no qual consultaremos as organizações do github, salvaremos no banco de dados e retornaremos à consulta, caso já esteja cacheado.
São duas rotas:
- /orgs/{nomeDaOrganizacao} -> que retorna dados da organização;
- /orgs -> que retorna todas as organizações que já foram consultadas.
Biblioteca do Redis para instalar
npm i <span class="pl-k">--</span>save redis
or
yarn add redis
Inicializando o projeto
const redis = require('redis');
const cache = redis.createClient();
Verificando se a conexão ocorreu com sucesso
cache.on('connect', () => {
console.log('REDIS READY');
});
cache.on('error', (e) => {
console.log('REDIS ERROR', e);
});
Função para setar o cache
const timeInSecond = 'EX'; const time = 10; cache.set(keyName, value, timeInSecond, time)
- KeyName -> chave na qual será salvo o valor;
- value -> valor que será salvo, no geral pode ser string, inteiro ou objeto de primeira ordem;
- timeInSecond -> tipo de temporizador que será utilizado;
- ‘EX’ -> Tempo em segundos;
- ‘PX’ -> Tempo em milissegundos;
- ‘NX’ -> Inserir se não existir;
- ‘EX’ -> Inserir se existir.
Função para setar dados de cache
cache.get(keyName);
Criando um middleware para o express
const http = require('http');
const express = require('express');
const Promise = require('bluebird');
function cacheMiddleware(req, res, next) {
return Promise.coroutine(function* () {
const keyName = req.originalUrl;
const cacheRes = yield getCache(keyName);
if (cacheRes) {
return res.json(cacheRes);
}
next();
})();
}
const app = express(APP_PORT);
httpServer = http.Server(app);
app.use(cacheMiddleware);
app.get('/', (req, res) => {
res.json({ status: 'The NODE_REDIS XD' });
});
Criando um canal de PUB/SUB…
const sub = redis.createClient(REDIS_PORT, REDIS_HOST);
const sub = redis.createClient(REDIS_PORT, REDIS_HOST);
sub.on('message', () => {
});
sub.subscribe('clean_cache');
pub.publish(canal, 'clean');
… com express.js mongo redis que vai salvar.
Essas vão rodar em dois cenários, criando um middleware simples para verificar se já existe cache e retornar os dados. Em outra etapa vamos setar o cache caso necessário e limpar uma key por meio de um canal de PUB/SUB.
Para subir as dependências externas do projeto, Redis e MongoDb, basta utilizar este comando:
docker-compose up
Referências
- https://redis.io/topics/introduction
- http://www.sohamkamani.com/blog/2016/10/14/make-your-node-server-faster-with-redis-cache/
- https://goenning.net/2016/02/10/simple-server-side-cache-for-expressjs/
- https://community.risingstack.com/redis-node-js-introduction-to-caching/
- https://blog.risingstack.com/node-js-developer-survey-results-2016/
- https://www.sitepoint.com/using-redis-node-js/
E é isso! Ficou alguma dúvida ou tem algo a dizer? Aproveite os campos abaixo. Até a próxima!
Este artigo foi publicado originalmente em https://www.concrete.com.br/2017/08/14/utilizando-cache-com-redis-e-node-js/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?