



Gerenciamento centralizado de múltiplas instâncias
Como gerenciar de forma eficiente suas instâncias através do Data Collector e Policy-Based Management? Apresentamos tecnologias de gerenciamento SQL Server.


Aprenda como gerenciar de forma eficiente suas instâncias através do Data Collector e Policy-Based Management.
De que se trata o artigo
São apresentadas algumas tecnologias que facilitam o gerenciamento centralizado de múltiplas instâncias de banco de dados SQL Server. Através do Policy-Based Management e do Data Collector, é possível criar políticas e coletar métricas de todas as instâncias de SQL Server existentes na sua infraestrutura, facilitando no controle dos recursos de hardware utilizados e identificando os principais pontos de contenção existentes.
Em que situação o tema é útil
Este artigo visa auxiliar o administrador de banco de dados que é responsável por um grande parque de servidores de banco de dados SQL Server e necessita otimizar o processo de administração de um ambiente com múltiplas instâncias de banco de dados SQL Server.
Neste artigo, serão abordadas as principais técnicas para o gerenciamento eficiente de múltiplas instâncias em um ambiente de banco de dados SQL Server 2014 através das ferramentas Data Collector, e Policy–Based Management.
Além disso, será demonstrado de forma prática como configurar cada uma das ferramentas e também como extrair e analisar as métricas coletadas.
Com o crescimento exponencial da quantidade de dados gerados pelas aplicações, aumentou a complexidade no gerenciamento dos ambientes de banco de dados para o administrador de banco de dados.
Este crescimento, combinado com o baixo custo dos meios de armazenamento nos servidores, iniciou um cenário no qual o administrador de banco de dados deixou de administrar algumas dezenas de bancos de dados e passou a administrar centenas de banco de dados.
Como as principais responsabilidades de um administrador de banco de dados são garantir a integridade, o desempenho e estabilidade de todas as instâncias de SQL Server sob sua administração, quanto maior o número de instâncias e bancos de dados utilizados dentro de uma empresa, maior a dificuldade em monitorar e administrar o ambiente de banco de dados de forma pró ativa e automatizada.
Para este tipo de cenário, o SQL Server possibilita centralizar tanto a execução das tarefas rotineiras de um administrador de banco de dados, quanto à coleta de métricas de desempenho de todas as instâncias e banco de dados existentes, através das ferramentas Data Collector (DC) e Policy-Based Management (PBM). Por exemplo, existe a necessidade de que todos os bancos de dados que possuam o parâmetro recovery model definido como Full realizem um backup do arquivo de log a cada hora. Ao invés desta política existir apenas de forma escrita, e ser verificada manualmente em todos os servidores de banco dados, é possível utilizar o PBM para garantir que esta política seja aplicada de uma única vez em todas as instâncias de SQL Server existentes.
A fim de facilitar o entendimento do gerenciamento de múltiplas instâncias, a apresentação das ferramentas será realizada na seguinte ordem:
Policy-Based Management;
Data Collector;
O que é o Policy-Based Management?
O Policy-Based Management (PBM) é uma funcionalidade disponível a partir do SQL Server 2008 e que permite a criação e implementação de políticas em suas instâncias de SQL Server. O PBM funciona de forma semelhante às políticas de grupo criadas através do Active Directory. As políticas de grupo oferecem um gerenciamento centralizado de aplicações e usuários, por meio de regras criadas pelos administradores de sistema e que podem ser aplicadas em vários níveis da estrutura de diretórios criada no Active Directory.
Através do PBM aplica-se uma política em um determinado target, por exemplo, um banco de dados, uma tabela, uma view ou uma stored procedure e avalia se o target está de acordo com as regras desta política. Caso o target não esteja de acordo com as regras da política, é possível tanto impor as regras da política quanto disparar um alerta para que o administrador de banco de dados saiba da violação desta política.
Uma das grandes vantagens do PBM é a aplicação de uma política em várias instâncias de banco de dados SQL Server de uma única vez, facilitando a administração e gerenciamento de toda a infraestrutura de banco de dados da corporação.
Muitas funcionalidades do SQL Server 2014, tais como Resource Governor, Compressão de Dados e In-Memory OLTP, necessitam das edições Enteprise ou Developer. Este não é o caso do PBM, que está disponível em todas as edições do SQL Server, incluindo a edição Express (embora com a edição Express não seja possível à criação de um Central Management Server).
Assim que a instância de SQL Server 2014 estiver instalada, já é possível criar e avaliar as políticas contra qualquer SQL Server existente no ambiente, inclusive em versões anteriores ao SQL Server 2014.
Componentes do Policy-Based Management
O PBM é composto por três principais componentes: Policies, Conditions e Facets, conforme mostra a Figura 1. Os componentes estão dispostos em uma espécie de ordem hierárquica para a utilização do PBM. Uma facet é necessária para a criação de uma condition, e a condition é necessária para a criação das policies. As policies são aplicadas em targets específicos.

Targets
Os targets são os objetos gerenciados por uma determinada política e podem ser de vários tipos: servidores, bancos de dados, instâncias, stored procedures, entre outros. Uma política pode conter múltiplos targets.
Facets
Uma facet é um grupo de propriedades relacionadas a um determinado target. O SQL Server 2014 possui 86 facets, cada uma contendo várias propriedades diferentes. Isto permite a utilização de centenas de propriedades na criação de uma política.
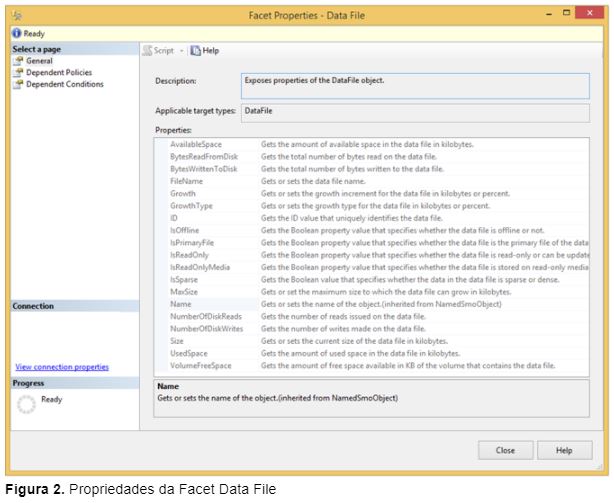
É possível visualizar as propriedades de uma facet expandindo a pasta Facets e clicando duas vezes em uma determinada facet. Por exemplo, a facet Data File possui várias propriedades, tais como tamanho máximo do arquivo de dados, número de leituras e escritas e se o arquivo de dados está online, conforme mostra a Figura 2.
Nota: As facets são apenas para leitura e não é possível criar uma nova facet customizada.
Conditions
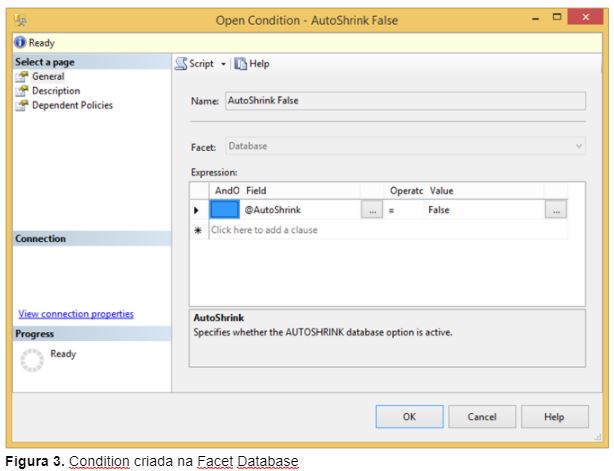
Uma condition é um determinado estado para que uma política seja avaliada. Basicamente, a política verifica a condition de um target e caso este target não esteja de acordo com a condition, a política falha. Uma política pode avaliar apenas uma condition, porém é possível avaliar várias propriedades em uma mesma condition.
Uma condition pode ser visualizada expandindo a pasta Conditions e clicando duas vezes em uma determinada condition, conforme mostra a Figura 3.
Nota: Não existirão conditions customizadas ao menos que sejam previamente importadas ou criadas manualmente. Inicialmente só existirão as conditions de sistema.
Policies
As policies são pacotes completos que incluem conditions, facets, targets, modos de avaliação e restrições de servidor (modos de avaliação e restrições de servidor serão discutidos no próximo tópico).
Quando criadas, as policies são armazenadas no banco de dados de sistema msdb, mas é possível exportá-las em um formato XML. Esta portabilidade permite aos administradores de banco de dados uma maior facilidade para compartilhar e comparar as policies criadas.
É possível visualizar uma política expandindo a pasta Policies e clicando duas vezes em uma determinada política, conforme mostra a Figura 4.
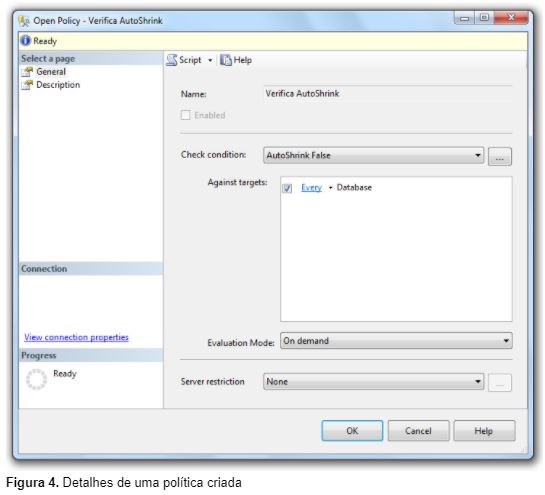
Nota: Não existirão policies customizadas ao menos que sejam previamente importadas ou criadas manualmente. Inicialmente só existirão as policies de sistema.
Modos de avaliação da política
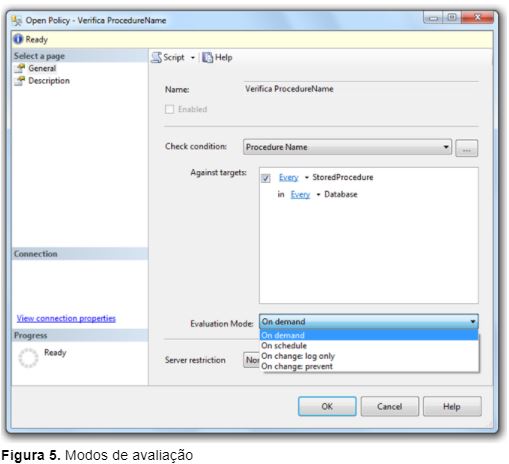
O PBM possui quatro maneiras distintas de uma política ser executada e determinam como uma política será avaliada sob um target predefinido. Os seguintes modos de avalição podem estar disponíveis, dependendo da facet utilizada na política:
- On Demand: Este modo de avaliação especifica que uma política será executada manualmente. Por padrão, qualquer política com este modo de avaliação é desabilitada automaticamente após ser criada. Mesmo estando desabilitada, essa política pode ser avaliada a qualquer momento.
- On Schedule: Selecionando este modo de avaliação é possível agendar a política para ser avaliada a qualquer momento. Por padrão, pode-se selecionar um agendamento já criado ou criar um novo agendamento que atenda sua necessidade. A criação de um agendamento permite que sejam definidas opções como a recorrência de execução, frequência de execução por dia, frequência de execução por hora e por quanto tempo uma política deve ser executada. Por exemplo, executar uma determinada política pelas próximas duas semanas.
- On Change: Log Only: Selecionando este modo de avaliação a política será avaliada apenas se alguma alteração for realizada no target especificado dentro da política. Caso o evento de alteração viole a política, o evento será executado e os resultados da violação da política serão armazenados no event log e no banco de dados de sistema msdb. Este modo de avaliação auxilia o administrador de banco de dados sem afetar o desempenho do ambiente.
- On Change: Prevent: Este modo de avaliação é muito parecido com o On Change: Log Only, ou seja, a política será avaliada no momento em que um evento realizar alguma alteração no target definido dentro da política. Mas diferente da opção Log Only, a opção Prevent realizará o procedimento de rollback de qualquer alteração que viole a política.
A Figura 5 mostra um exemplo de uma política e os modos de avaliação disponíveis para a mesma.
Restrições de servidor
Em conjunto com os targets e as facets, as restrições de servidor são outra maneira de controlar como uma política será avaliada. Uma restrição de servidor nada mais é do que uma condição utilizada para excluir um determinado servidor de uma política através da facet Server.
É possível criar uma restrição de servidor que limite a avaliação de uma política apenas nas instâncias de SQL Server que utilizam as edições Standard ou Enteprise. Quando esta política for aplicada, não serão avaliadas as instâncias que não utilizem estas edições específicas.
Gerenciamento das políticas
O SQL Server 2014 possui algumas funcionalidades que facilitam o gerenciamento e a avaliação das políticas criadas. Podem-se utilizar categorias para agrupar políticas parecidas e utilizar o Central Management Server (CMS) para executar as políticas por todo o ambiente de banco de dados.
Categorias
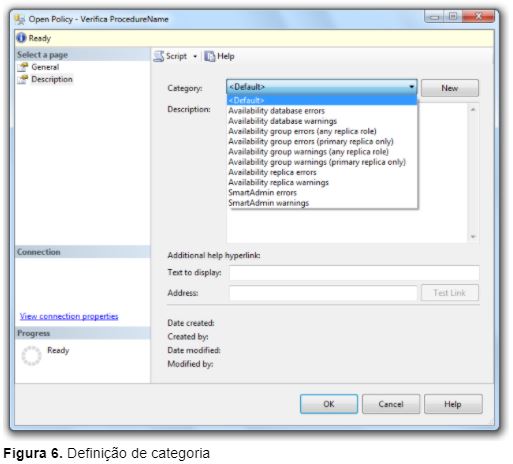
As categorias são um grupo lógico de uma ou mais políticas e que auxiliam no gerenciamento e execução das mesmas. Por exemplo, é possível criar um grupo de políticas que serão avaliadas apenas em ambientes de teste ou desenvolvimento. Quando uma política é criada, especifica-se uma categoria na opção Description, conforme mostra a Figura 6.
Central Management Servers (CMS)
A funcionalidade CMS não é parte da arquitetura do PBM, porém tornou-se extremamente importante na utilização das políticas em um ambiente de banco de dados SQL Server composto por múltiplos servidores.
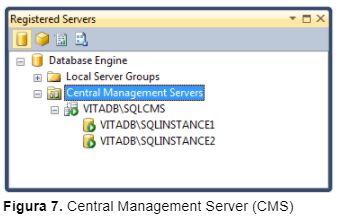
No SQL Server 2014 é possível especificar uma instância de banco de dados SQL Server (Standard ou maior) para ser uma central de gerenciamento. O CMS armazena uma lista de instâncias registradas e que podem ser organizadas e um mais grupos, conforme mostra a Figura 7.
Alertas
Uma vez que as políticas estejam configuradas e implementadas, não é necessário verificar constantemente os servidores para termos certeza de que estão de acordo com as condições definidas nas políticas. Ao invés disso, podemos utilizar os alertas do SQL Server Agent para recebermos automaticamente notificações quando uma política for violada.
[CHECKPOINT]
Criação de uma política
No SQL Server 2014 é possível criar uma manualmente através do T-SQL, exportando políticas já existentes em uma instância de banco de dados SQL Server ou importando políticas criadas pela própria Microsoft. Com a utilização de condições avançadas quase não existem limites para os tipos de políticas que podem ser criadas. Assim que iniciarmos a criação de políticas, ficará clara a vantagem em agruparmos políticas similares em uma mesma categoria.
Para facilitar o entendimento de todos os componentes utilizados na criação de uma política e como os mesmos interagem entre si, criaremos uma política do zero. Para criarmos manualmente uma política é necessário primeiro definirmos uma condição e então poderemos criar uma política que utilizará esta condição. Uma vez que a política estiver criada, será possível categorizá-la e definir em quais targets deverá ser avaliada. Nesta parte do artigo realizaremos a criação de uma política que avaliará se todos os bancos de dados de uma determinada instância SQL Server estão com a propriedade AutoShrink desabilitada.
Criando uma condição
Vamos iniciar criando uma condição que será utilizada em uma política. Neste exemplo, criaremos uma condição que avaliará se um banco de dados está com a propriedade AutoShrink desabilitada.
A criação de uma condição pode ser realizada de duas maneiras. A primeira opção é através do SQL Server Management Studio (SSMS):
1 – Utilizando o Object Explorer, abra a pasta Management e depois a pasta Policy Management (Figura 8);
2 – Dentro dessa pasta, clique com o botão direito na pasta Conditions e selecione a opção New Condition;
3 – Feito isso, será aberta a janela para criação da nova condição (Figura 9);
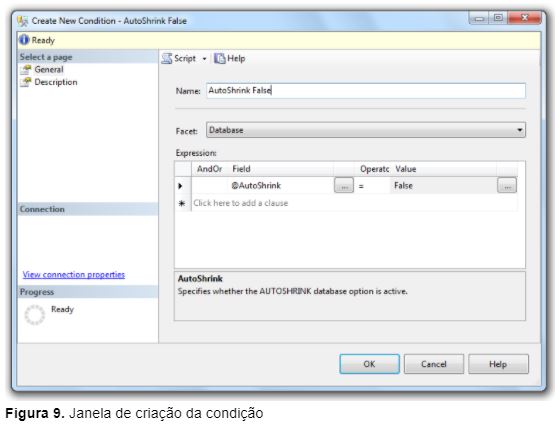
Conforme ilustrado na Figura 9, durante a criação da condição foram definidas as seguintes opções:
- Name: A condição foi criada com o nome de AutoShrink False;
- Facet: A facet utilizada foi a Database;
- Expression: A propriedade avaliada foi a @AutoShrink e o seu valor deve ser igual a false;
Opcionalmente, podemos incluir uma descrição detalhada sobre a condição através da opção Description, conforme mostra a Figura 10.
A segunda opção para a criação da condição é através da stored procedure de sistema SP_SYSPOLICY_ADD_CONDITION. A Listagem 1 exemplifica a criação da condição AutoShrink False, com as mesmas opções definidas no SSMS.
Listagem 1. Criação da condição com T-SQL
Declare @condition_id int
EXEC msdb.dbo.sp_syspolicy_add_condition @name=N'AutoShrink False', @description=N'', @facet=N'Database', @expression=N'<Operator>
<TypeClass>Bool</TypeClass>
<OpType>EQ</OpType>
<Count>2</Count>
<Attribute>
<TypeClass>Bool</TypeClass>
<Name>AutoShrink</Name>
</Attribute>
<Function>
<TypeClass>Bool</TypeClass>
<FunctionType>False</FunctionType>
<ReturnType>Bool</ReturnType>
<Count>0</Count>
</Function>
</Operator>', @is_name_condition=0, @obj_name=N'', @condition_id=@condition_id OUTPUT
Select @condition_id
GOCriando uma política
Agora que temos uma condição já criada, podemos criar uma política que utilizará esta condição.
Como na criação de uma condição, a política pode ser criada tanto através do SQL Server Management Studio (SSMS), como através de T-SQL.
Primeiramente criaremos a política utilizando o SSMS:
1 – Utilizando o Object Explorer, abra a pasta Management e depois a pasta Policy Management (Figura 8);
2 – Dentro dessa pasta, clique com o botão direito sobre a pasta Policies e selecione a opção New Policy;
3 – Feito isso, será aberta a janela para a criação da nova política (Figura 11);
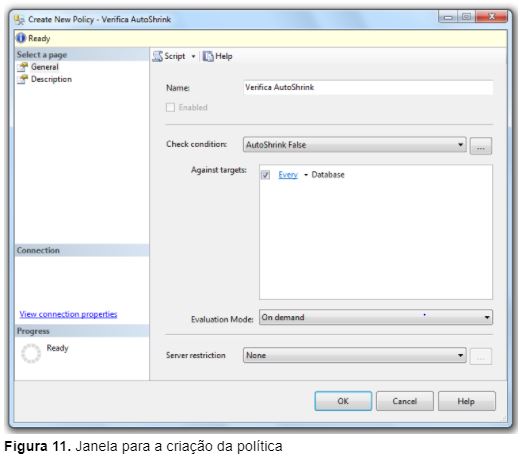
De acordo com a Figura 11, durante a criação da política foram definidas as seguintes opções:
- Name: A política foi criada com o nome de Verifica AutoShrink;
- Check Condition: A condição que será avaliada pela política é a AutoShrink False;
- Against Targets: A política deverá ser avaliada em qualquer banco de dados existente na instância de SQL Server;
Nota: Um target não será sempre um banco de dados. Os targets mudam baseados no contexto de avaliação da condição. Por exemplo, se criarmos uma política para padronizar o nome de novas tabelas utilizando a facet Tables, a opção Against Targets exibirá All Tables.
- Evaluation Mode: O modo de avaliação selecionado foi o OnDemand, ou seja, esta política deverá ser executada manualmente;
Nota: Os modos de avaliação disponíveis na lista dependem das facets utilizadas na condição. Todas as facets suportam o OnChange e o OnSchedule, mas o OnChange: Prevent depende da facet que pode utilizar as triggers de DDL para realizar o procedimento de rollback da transação. O modo de avaliação OnChange: Log Only baseia-se na capacidade das alterações realizadas na facet serem capturadas por um evento.
- Server Restriction: Para esta política não haverá condições que restrinjam os servidores de banco de dados avaliados;
Podemos adicionar mais detalhes referentes à política através da opção Description, conforme mostra a Figura 12
Figura 12. Janela de descrição da política
Também é possível realizar a criação da política através das stored procedure de sistema SP_SYSPOLICY_ADD_OBJECT_SET, SP_SYSPOLICY_ADD_TARGET_SET, SP_SYSPOLICY_ADD_TARGET_SET_LEVEL e SP_SYSPOLICY_ADD_POLICY. A Listagem 2, exemplifica a criação da política Verifica AutoShrink, com as mesmas opções definidas no SSMS.
Listagem 2. Criação da política com T-SQL
Declare @object_set_id int
EXEC msdb.dbo.sp_syspolicy_add_object_set @object_set_name=N'Verifica AutoShrink_ObjectSet_1', @facet=N'Database', @object_set_id=@object_set_id OUTPUT
GO
Declare @target_set_id int
EXEC msdb.dbo.sp_syspolicy_add_target_set @object_set_name=N'Verifica AutoShrink_ObjectSet_1', @type_skeleton=N'Server/Database', @type=N'DATABASE', @enabled=True, @target_set_id=@target_set_id OUTPUT
GO
EXEC msdb.dbo.sp_syspolicy_add_target_set_level @target_set_id=@target_set_id, @type_skeleton=N'Server/Database', @level_name=N'Database', @condition_name=N'', @target_set_level_id=0
GO
Declare @policy_id int
EXEC msdb.dbo.sp_syspolicy_add_policy @name=N'Verifica AutoShrink', @condition_name=N'AutoShrink False', @execution_mode=0, @policy_id=@policy_id OUTPUT, @root_condition_name=N'', @object_set=N'Verifica AutoShrink_ObjectSet_1'
GOTodas as políticas criadas são armazenadas no banco de dados de sistema msdb. Depois de criarmos nossas políticas, temos de nos certificar que o banco de dados de sistema msdb faça parte da estratégia de backup utilizada no ambiente.
Importando políticas
Podemos importar políticas disponibilizadas pela Microsoft durante o processo de instalação do SQL Server. Estas políticas são armazenadas em arquivos no formato XML e que ficam localizados no diretório Tools onde o SQL Server foi instalado.
A importação de políticas predefinidas tem algumas vantagens, pois além de criadas as políticas também são criadas todas as condições necessárias para o funcionamento correto da política. No entanto, não podemos importar apenas as políticas disponibilizadas pela Microsoft, mas também qualquer arquivo XML que possua as informações necessárias para a criação e uma política.
Para executar a importação de uma política temos os seguintes passos:
- Utilizando o Object Explorer, abra a pasta Management (Figura 8);
- Dentro dessa pasta, clique com o botão direito na pasta Policies e selecione a opção Import Policy;
- Feito isso, será aberta a janela para importação do arquivo XML com as definições da política (Figura 13);

Selecione a opção Replace duplicates with Items Imported para sobrescrever qualquer política e condição que tenha o mesmo nome da política que está sendo importada. Ao sobrescrever uma política já existente, não serão perdidas as informações das validações já realizadas com a política sobrescrita.
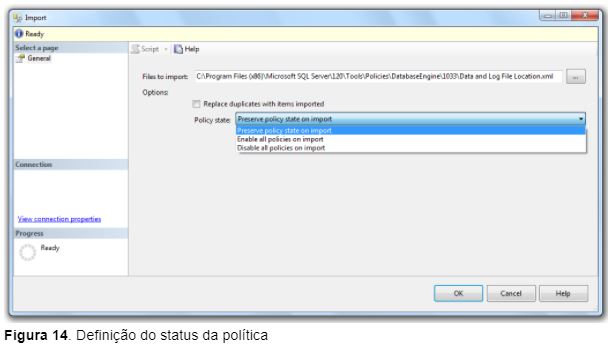
Também podemos preservar o status da política que está sendo importada, habilitar a política após a importação ou desabilitar a política após a importação, conforme mostra a Figura 14.
Após a importação do arquivo XML contendo as definições da política, podemos visualizá-la na pasta Policies. A nova política foi criada com o nome de Data and Log File Location, conforme mostra a Figura 15.
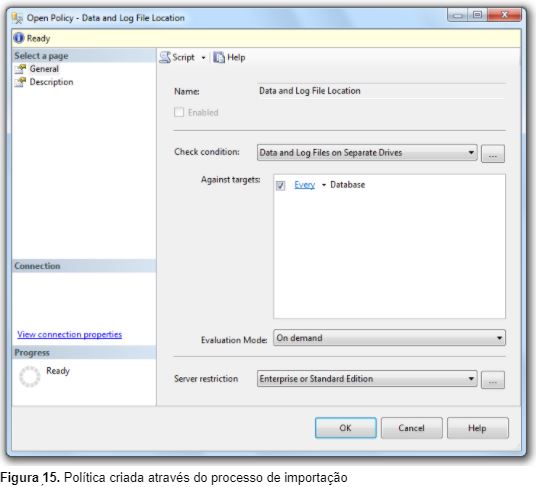
É interessante observar que diferentemente da política criada anteriormente, a política criada através do processo de importação possui uma restrição de servidor que limita a validação das condições existentes na política apenas nas instâncias de SQL Server que utilizem as edições Enterprise ou Standard.
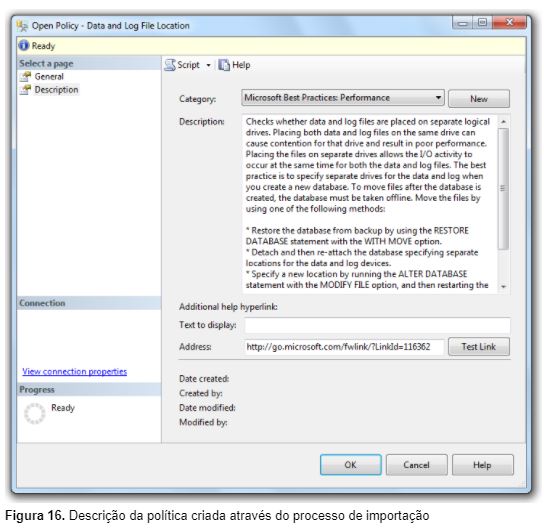
A Figura 16 mostra as informações gerais que foram automaticamente inseridas quando importamos a política através do arquivo XML. A categoria, descrição e hyperlinks foram populadas, facilitando o processo de documentação que informa o motivo desta política ter sido implementada.
Exportando políticas
Da mesma forma que podemos importar políticas utilizando arquivos no formato XML, é possível exportar as políticas já criadas para arquivos no formato XML. Através destes arquivos podemos importar estas mesmas políticas em outros servidores de banco de dados SQL Server. Existem duas maneiras de exportar uma política:
- Exportando uma política já existente;
- Exportado o estado atual de uma facet;
É extremamente fácil exportar uma política já existente para um arquivo XML, basta executar os seguintes passos através do SQL Server Management Studio (SSMS):
1 – Utilizando o Object Explorer, abra a pasta Management (Figura 8);
2 – Dentro dessa pasta, abra a pasta Policy ManagementPolicies para listar as políticas já existentes (Figura 17);
3 – Clique com o botão direito na política que deseja exportar e seleciona a opção Export Policy (Figura 18);
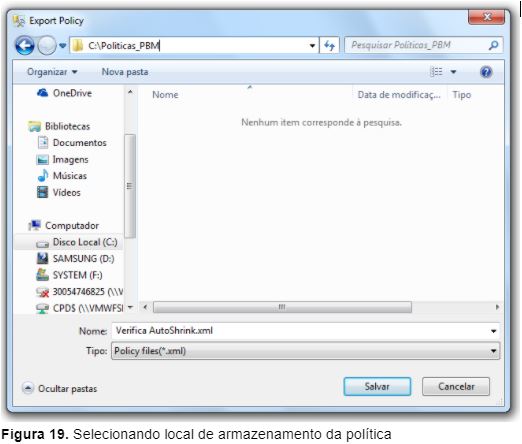
4 – Selecione o local desejado para a gravação do arquivo no formato XML e o nome do mesmo (Figura 19);
Muitas políticas podem ser exportadas de acordo com o estado atual de uma facet. Uma vez que as propriedades de uma facet tenham sido configuradas, podemos exportar essa configuração no formato de uma política.
Por exemplo, após configurarmos todas as propriedades da facetchamada Surface Area Configuration, pode-se exportar estas configurações para um arquivo no formato XML da seguinte forma:
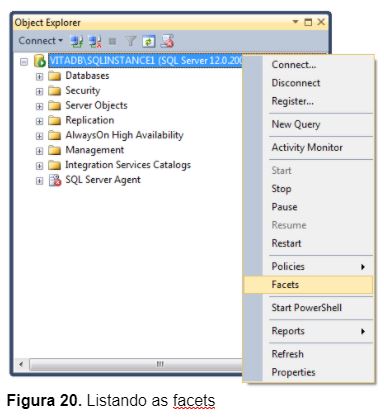
1 – Através do Object Explorer, clique com o botão direito na instância SQL Server e selecione a opção Facets(Figura 20);
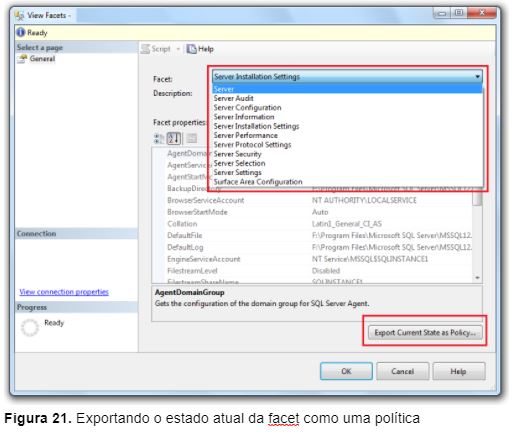
2 – Seleciona a facet desejada e clique no botão Export Current State as Policy (Figura 21);
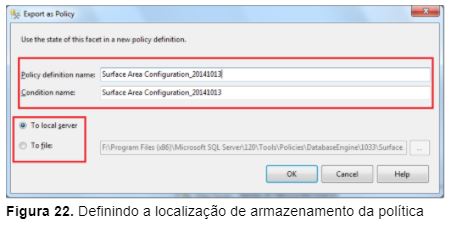
3 – Preencha com o nome da política, o nome da condição e a destino de exportação da política (Figura 22);
Avaliação da política
A avaliação da política é o processo no qual executamos a política em um target determinado e revisamos os resultados retornados pela mesma. O PBM permite que uma política seja avaliada em uma única instância ou em um grupo de instâncias utilizando o CMS. Como a proposta deste artigo é o gerenciamento de múltiplas instâncias, utilizaremos o CMS para avaliarmos a política Verifica AutoShrink, criada anteriormente, em duas instâncias de banco de dados SQL Server.
A Tabela 1 mostra as instâncias de banco de dados SQL Server que serão utilizadas para a avaliação da política criada através do PBM.

Inicialmente definimos a instância VITADB\SQLCMS como a nossa instância central de gerenciamento, através dos seguintes passos:
1 – Clique com o botão direito na opção Central Management Servers e selecione a opção Register Central Management Server (Figura 23);
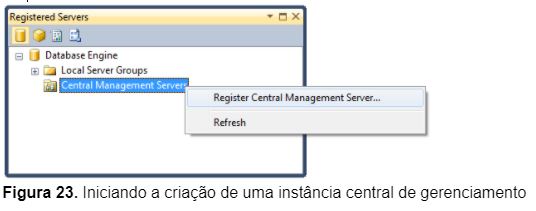
2 – Na caixa de diálogo New Server Registration, preencha com as informações de conexão (Figura 24);
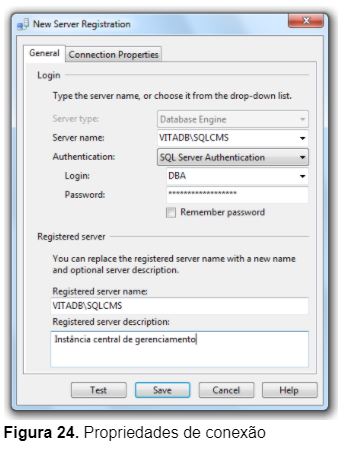
3 – Clique com o botão direito na instância VITADB\SQLCMS e selecione a opção New Server Registration (Figura 25);
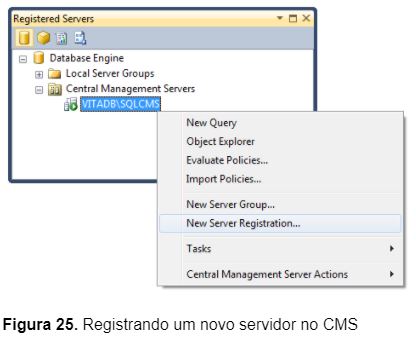
4 – Repita o procedimento descrito na etapa 3 e registre as instâncias VITADB\SQLINSTANCE1 e VITADB\SQLINSTANCE2;
5 – Clique com o botão direito na instância VITADB\SQLCMS e na opção Evaluate Policies;
6 – Na caixa de diálogo selecione a instância que possui a lista de políticas, qual política será avaliada e clique no botão Evaluate (Figura 26);
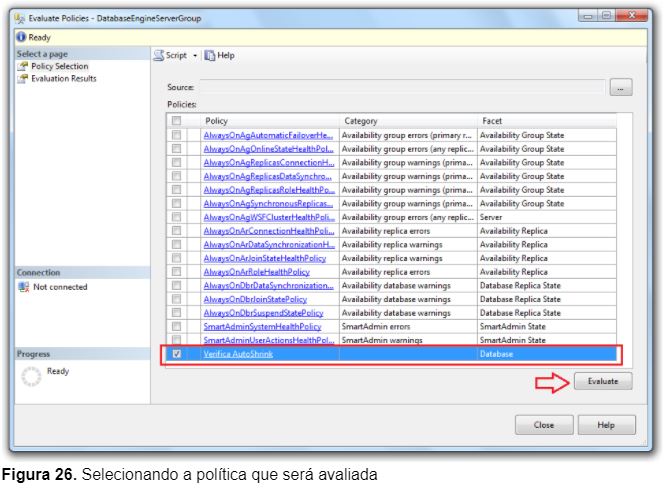
Após a avaliação da política Verifica AutoShrink podemos analisar, através da Figura 27, que existe um banco de dados chamado DBTeste1 na instância VITADB\SQLINSTANCE1 e um banco de dados chamado DBTeste2 na instância VITADB\SQLINSTANCE2 que estão fora da política, ou seja, nos quais a propriedade AutoShrink está habilitada quando o correto seria estar desabilitada.
Como vocês puderam notar, através do PBM podemos criar e avaliar políticas em uma ou mais instâncias de banco de dados SQL Server. Desta forma temos um gerenciamento mais simples e eficiente de um ambiente composto por múltiplas instâncias.
Vamos agora conhecer a ferramenta Data Collector e como utilizá-la para uma monitoração centralizada das instâncias de banco de dados SQL Server.
O que é o Data Collector?
O Data Collector (DC) é um dos principais componentes do conjunto de ferramentas para coleta de dados fornecido pelo SQL Server. Com o DC é possível definir um ponto centralizado para o armazenamento de todas as métricas coletadas através das instâncias de banco de dados SQL Server existentes em sua infraestrutura, sendo que estas métricas podem ser de várias origens diferentes e não apenas relacionadas a métricas de desempenho.
Para aumentar a eficiência das métricas coletadas, é possível ajustar o DC de acordo com cada ambiente existente em sua infraestrutura (desenvolvimento, homologação, produção). O DC armazena todas as informações coletadas em um datawarehouse de gerenciamento (MDW) e permite que sejam configurados diferentes períodos de retenção para cada métrica que será coletada.
Como o DC possui uma interface de programação (API), podemos customizar coletas para qualquer outro tipo de métrica desejada, porém neste artigo nos concentraremos apenas nas três coletas de sistema do DC: Disk Usage, Query Activity e Server Activity.
A Figura 28 mostra como o DC encaixa-se na estratégia para a coleta e gerenciamento de dados em um ambiente de banco de dados SQL Server.
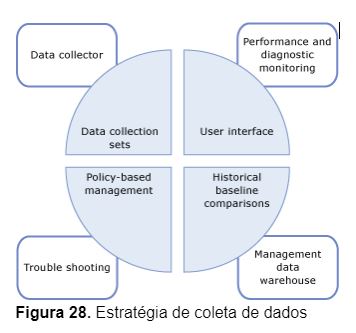
Arquitetura do Data Collector
Antes de iniciar a implementação do DC, é necessário entender quais componentes fazem parte desta funcionalidade. São eles:
- Target: Uma instância de banco de dados SQL Server que suporte o processo de coleta de métricas através da utilização do DC;
- Target Type: Define o tipo de target do qual serão coletadas métricas. Por exemplo, uma instância de banco de dados SQL Server possui métricas diferentes do que as métricas coletadas de uma base de dados SQL Server;
- Data provider: Uma origem de dados que proverá métricas para o collector type;
- Collector Type: Um delimitador lógico para os pacotes do SQL Server Integration Service (SSIS) e que fornece o mecanismo para a coleta e armazenamento das métricas no MDW;
Nota: No SQL Server 2014 temos os seguintes collector types: Generic T-SQL Query, Generic SQL Trace, Performance Counters e Query Activity
- Collection Item: É um item de coleta no qual são definidas quais as métricas serão coletadas, com que frequência esta coleta será realizada e qual o tempo de retenção da métrica armazenada;
- Collector Set: Um conjunto de Collection Items;
- Collection Mode: A forma que as métricas serão coletadas e armazenadas no MDW. As métricas podem ser coletadas de forma contínua (Cached Mode) ou de forma esporádica através de um agendamento (Non-Cached Mode);
- Management Data Warehouse (MDW): O banco de dados relacional utilizado para o armazenado de todas as métricas coletadas.
A Figura 29 mostra as dependências e os relacionamentos existentes entre os componentes do DC.
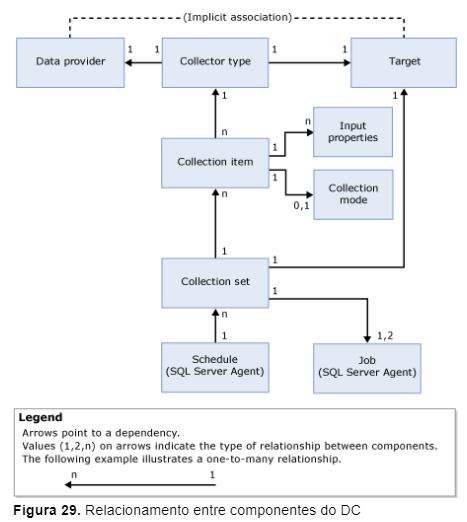
É possível notar que o data provider é um componente externo na arquitetura do DC e que, por definição, possui um relacionamento implícito com o target. Um data provider é específico para um determinado target e fornece métricas através de views de sistema, contadores de performance e componentes de WMI que são consumidos pelo DC.
Um collector type é específico para um determinado target type, de acordo com o relacionamento lógico de um data provider com um target type. O collector type define como as métricas serão coletadas e qual o esquema de armazenamento das métricas coletadas.
O collector type também fornece a localização do MDW, que pode ser no servidor que está executando a coleta ou em um servidor centralizado. Um collection item possui uma frequência de coleta predefinida e só pode ser criado dentro de um collector set.
O collector set é criado na instância de banco de dados SQL Server que será monitorada através do DC e é composto por um ou mais collection items. A coleta do conjunto de métricas definidas no collector set é realizada através de Jobs executados pelo serviço SQL Server Agent, e as métricas coletadas são armazenadas no MDW periodicamente por meio de agendamentos predefinidos.
A Figura 30 mostra um collector set de sistema chamado Disk Usage, que está com o collection mode definido como Non-Cached, utilizando dois collection items do tipo Generic T-SQL Query Collector Type, coletando métricas a cada 60 segundos e com retenção destas métricas no MDW por 730 dias.
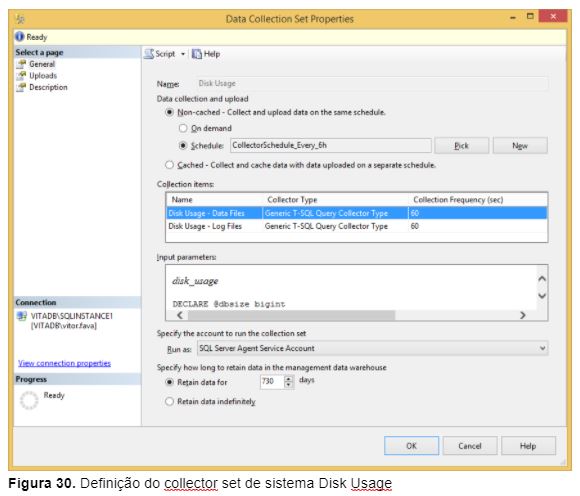
É importante ressaltar que o DC é totalmente integrado com o serviço SQL Server Agent e com o Integration Services, utilizando ambos de forma intensiva. Após a configuração do DC, o processo de coleta a gravação das métricas é realizado por um conjunto de Jobs do SQL Server Agent.
Management Data Warehouse (MDW)
Para que possamos utilizar a coleta de métricas através do DC, é necessário primeiro realizar a criação do MDW, que será o banco de dados relacional responsável por armazenar todas as métricas coletadas pelos collector sets.
Podemos utilizar um banco de dados relacional já existente e configurá-lo como um MDW, porém é recomendável que seja criado um novo banco de dados, pois durante o processo de configuração do MDW diversos esquemas e tabelas referentes ao DC serão criadas. Os esquemas criados, automaticamente após a configuração do DC, são o core e o snapshot. Um terceiro esquema, custom_snapshots, será criado quando um collectior set customizado for definido pelo administrador de banco de dados.
O esquema core possui as tabelas, stored procedures e views que serão utilizadas para organizar e identificar as métricas coletadas. Estas tabelas são utilizadas por todos os collector types. Todos os objetos de banco de dados pertencentes ao esquema core só poderão ser alterados pelos membros dos perfis de banco de dados db_owner e mdw_admin do MDW.
A Tabela 2 lista todas as tabelas existentes no esquema core e suas respectivas descrições.

O esquema snapshot possui os objetos necessários para o armazenamento das métricas coletadas através dos collectior sets de sistema DC. As tabelas deste esquema só podem sofrer alterações dos membros pertencentes ao perfil de banco de dados mdw_admin.
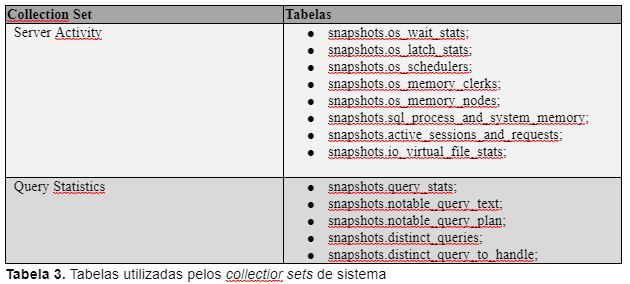
A Tabela 3 ilustra quais tabelas são utilizadas pelos collection sets de sistema Server Activity e Query Statistics, criados após a configuração do DC.
O esquema custom_snapshot possui as tabelas e views que foram criadas quando um collector
set customizado foi configurado. Qualquer collector set customizado que necessitar de uma nova tabela para armazenar métricas coletadas poderá criar tabelas neste esquema. As tabelas podem ser adicionadas por qualquer membro do perfil de banco de dados mdw_writer.
[CHECKPOINT]
Configurando o Data Collector
Neste exemplo de coleta de métricas utilizando o DC, teremos a instância VITADB\SQLCMS que hospedará o banco de dados MDW e as instâncias VITADB\SQLINSTANCE1 e VITADB\SQLINSTANCE2 que terão suas métricas coletadas através dos collector sets de sistema.
A primeira etapa de configuração do DC é a criação do MDW na instância VITADB\SQLCMS, conforme os seguintes passos:
- Através do Object Explorer seleciona a pasta Management
- Clique com o botão direito na opção Data CollectionTask Configure Management Datawarehouse;
- Na caixa de diálogo (Figura 31) selecione a instância VITADB\SQLCMS e crie o banco de dados MDW através do botão New;
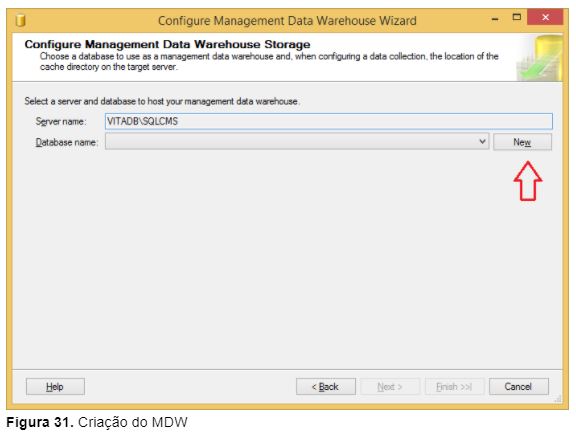
Selecione quais logins terão acesso ao banco de dados MDW (Figura 32) e clique em Finish;
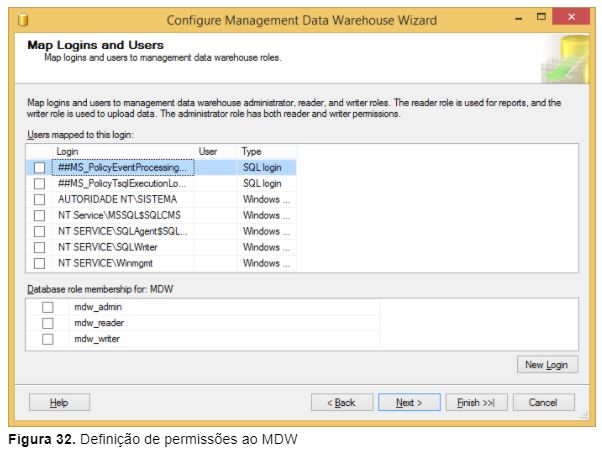
Nota: Os membros do perfil de banco de dados mdw_admin possuem permissão de SELECT, INSERT, UPDATE e DELETE, além de poder alterar qualquer esquema do MDW e executar os Jobs de manutenção do DC.
Os membros do perfil de banco de dados mdw_writer possuem permissão de carregar as métricas coletadas para o MDW.
Os membros do perfil de banco de dados mdw_reader possuem apenas permissão de SELECT no MDW.
Após a criação e configuração do MDW na instância VITADB\SQLCMS, será necessário iniciar o processo de coleta de métricas nas instâncias VITADB\SQLINSTANCE1 e VITADB\SQLINSTANCE2 configurando os collector sets de sistema em cada uma das instâncias e direcionando as métricas coletadas para o banco de dados MDW.
Para a configuração dos collector sets de sistema temos os seguintes passos:
- Através do Object Explorer, selecione a pasta Management;
- Clique com o botão direito na opção Data Collection Tasks Configure Data Collection;
- Na caixa de diálogo (Figura 33), conecte-se na instância VITADB\SQLCMS, selecione o banco de dados MDW, o collector set desejado e clique em Finish. Para este exemplo utilizaremos o collector set de sistema System Data Collection Sets;

Finalizada a configuração da coleta, temos a criação de três collector sets de sistema: Disk Usage, Query Statistics e Server Activity.
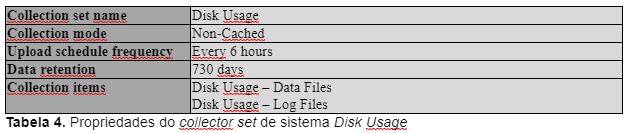
O collector set de sistema Disk Usage coleta métricas sobre o crescimento dos arquivos de dados (.mdf e .ndf) e dos arquivos de log (.ldf) dos bancos de dados de usuário e de sistemas existentes na instância monitorada pelo DC. Com estas informações é possível saber qual a tendência de crescimento diário, em MB, dos arquivos analisados.
A Tabela 4 mostra as propriedades do collector set de sistema Disk Usage.
O collector set de sistema Server Activity coleta métricas de atividades do servidor, estatísticas, performance, cadeias de bloqueio, informações gerais de memória, CPU e rede.
A Tabela 5 mostra as propriedades do collector set de sistema Server Activity.

O collector set de sistema Query Statistics coleta métricas referentes as consultas executadas no banco de dados monitorado pelo DC, como estatísticas, planos de execução, consultas mais custosas em relação a utilização de disco, CPU, memória e as consultas que mais tempo demoraram para serem finalizadas.
A Tabela 6 mostra as propriedades do collector set de sistema Query Statistics.

Visualizando as métricas coletadas
As métricas coletadas pelo DC podem ser acessadas diretamente por consultas T-SQL, entretanto após a configuração dos collector sets de sistema, alguns relatórios padronizados estão disponíveis para visualização. Para acessá-los é necessário clicar com o botão direito na opção Data CollectionReports Management Data Warehouse. Após a configuração dos collector sets de sistema, três relatórios estarão disponíveis:
- Server Activity History;
- Disk Usage Summary;
- Query Statistics History;
Server Activity History
Todas as informações disponíveis neste relatório são referentes à utilização de recursos do servidor de banco de dados, como total de CPU ou memória alocados, quais os maiores wait types existentes no SQL Server, qual o valor de IOPs, entre outros. Todas essas informações são extremamente úteis para um processo de troubleshooting e tuning.
A Figura 34 mostra a parte superior do relatório Server Activity History, extraído da instância VITADB\SQLINSTANCE2.

No topo do relatório é possível visualizar de qual instância SQL Server são as métricas exibidas e em que data e hora foram solicitadas. Abaixo desta informação é possível selecionar qual o período de tempo coletado deve ser carregado no relatório. Cada gráfico apresenta informações sobre o sistema operacional (linhas de cor verde) e sobre o SQL Server (linhas de cor azul).
A Figura 35 mostra a parte inferior do relatório Server Activity History, extraído da instância VITADB\SQLINSTANCE2.
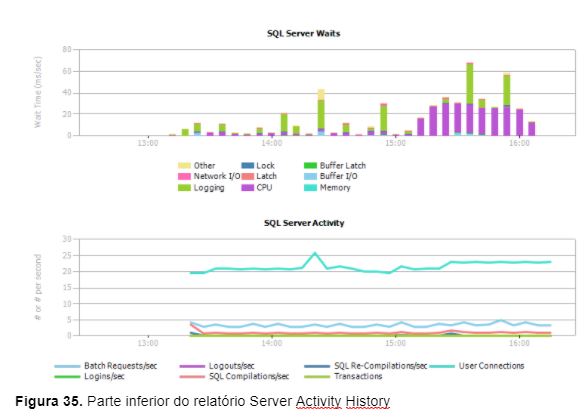
Estes relatórios também são extremamente úteis no processo de análise de desempenho e troubleshooting, pois exibem quais os maiores wait types e quais os principais tipos de atividades que ocorrem na instância. Através de qualquer um destes relatórios é possível visualizar mais detalhes selecionando uma das linhas ou barras de dados e iniciar um drill-down na informação desejada.
Nota: Imediatamente após a configuração do DC, não haverá informação para ser carregada nos relatórios. Quanto mais métricas forem coletadas e armazenadas no MDW, maior é o detalhamento alcançado através dos relatórios.
Disk Usage Summary
Este relatório lista o tamanho dos bancos de dados monitorados pelo DC e qual a média de crescimento dos mesmos durante um período de tempo. As métricas exibidas pelo relatório estão separadas por arquivos de dados e pelos arquivos de log dos bancos de dados monitorados pelo DC. Cada um dos arquivos de dados e arquivos de log possui a informação do tamanho inicial, do tamanho atual e a média de crescimento por dia em MB, conforme mostra a Figura 36.
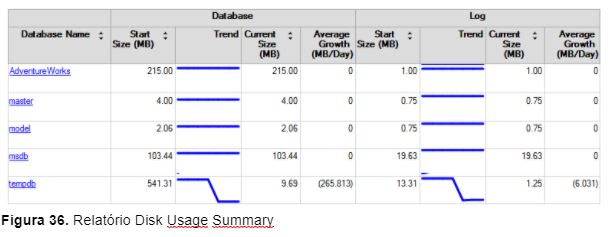
Query Statistics History
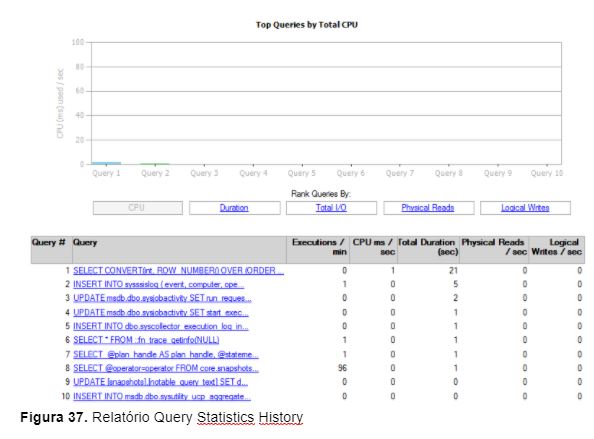
O motivo mais comum para os problemas de desempenho encontrados no SQL Server é a escrita de comandos T-SQL de forma ineficiente. A coleta de métricas de desempenho destas consultas é uma parte essencial para o processo de tuning. Por padrão, são exibidas as 10 consultas que mais consumiram CPU, mas é possível alterar este filtro e visualizar as consultas que realizaram mais operações de IO, mais tempo ficaram em execução, realizaram mais leituras físicas ou realizaram mais escritas lógicas.
A Figura 37 mostra o relatório Query Statistiscs History, extraído da instância VITADB\SQLINSTANCE2.
Recomendações para a configuração do DC
Para minimizar o impacto causado pelo processo de monitoração do ambiente de banco de dados do SQL Server pelo DC, siga as seguintes recomendações:
Utilize um servidor centralizado para o MDW, pois isto permite que exista apenas um único local para a execução e visualização dos relatórios;
Todos os servidores de banco de dados SQL Server que serão monitorados pelo DC devem fazer parte do mesmo domínio;
Quando criar um collector set customizado utilizando o collector type Generic SQL Trace, defina um conjunto de filtros para que somente as métricas realmente necessárias sejam coletadas, pois desta forma o MDW não armazenará informações desnecessárias;
Antes de criar um collector set customizado utilizando contadores de desempenho, tenha certeza de que o collector set de sistema Server Activity já não esteja coletando esta métrica;
Caso existam coletas de métricas através de várias consultas T-SQL e estas sejam executadas com a mesma frequência, combine-as em um mesmo collector set. Fazendo isso diminuiremos a quantidade de memória utilizada pelo executável do DC (DCCEXEC.exe) durante a coleta de métricas. De maneira similar, combine vários collection items do tipo Performance Counters em um único collection item sempre que possível;
Combine vários collection items em um único collector set sempre que possível. O único motivo para criarmos collector sets separados é se houverem períodos de retenção diferentes ou agendamento de coletas diferentes;
Um collector set que utilize o collection mode: Cached, sempre manterá um processo de coleta em execução. Se as métricas forem coletadas frequentemente, isto é mais eficiente do que iniciar e parar o processo de coleta sempre que novas métricas devam ser coletadas. Em contraste, o collection mode: Non–Cached não terá um processo de coleta em execução durante a maior parte do tempo. Um novo processo de coleta será iniciado de acordo com o agendamento predefinido de uma única vez e então será parado novamente. Se a coleta de métricas ocorrer raramente, o collection mode: Non–Cached é mais eficiente do que deixar o processo de coleta em espera a maior parte do tempo. Como regra geral, se a métrica necessita ser coletada a cada cinco minutos ou mais frequentemente que isso, considere configurar um collector set que utilize o collection mode: Cached. Se a coleta de métricas puder ser realizada com uma frequência maior do que 5 minutos é recomendado configurar collector set que utilize o collection mode: Non-Cached;
Quanto maior a frequência de coleta, maior será a sobrecarga no servidor de banco de dados. Portanto sempre configure a menor frequência possível que atenda a necessidade de coleta;
Conclusão
Conforme descrito no artigo, a partir do SQL Server 2008, temos duas ferramentas que facilitam o gerenciamento de um ambiente de banco de dados SQL Server composto por múltiplas instâncias. São eles: o Policy-Based Management (PBM) e o Data Collector (DC).
Com a utilização do PBM é possível criarmos políticas que avaliam determinadas condições nos objetos existentes na instância de banco de dados SQL Server. Estas políticas podem ser criadas manualmente ou importadas através de arquivos XML disponibilizados após a instalação do database engine. As políticas podem ser avaliadas manualmente (OnDemand), seguindo um agendamento predefinido (OnSchedule) ou no momento em que uma determinada propriedade de um objeto do SQL Server for alterada (OnChange). As políticas podem ser avaliadas em múltiplas instâncias de SQL
Server de uma única vez através da funcionalidade Central Management Server (CMS).
Com o DC temos uma funcionalidade que coleta de métricas de todas as instâncias SQL Server e as armazena em um banco de dados centralizado chamado Management Data Warehouse. A coleta das métricas é realizada automaticamente através de Jobs criados no SQL Server Agent. Após a configuração do DC, são criados três collector sets de sistema que coletam métricas referentes à utilização dos recursos de hardware do servidor (CPU, memória, disco e rede), crescimento dos arquivos de dados e log dos bancos de dados monitorados e as consultas T-SQL mais custosas executadas no servidor de banco de dados.
O DC também possui uma diversidade de relatórios já criadas para que as métricas coletadas através dos collector sets possam ser avaliadas durante os processos de troubleshooting e tuning.
Por fim, vimos que o DC é uma ferramenta de monitoração completa mas que precisa ser configurada da melhor maneira possível para evitar uma alta sobrecarga nos servidores de banco de dados durante o processo de coleta.
Até a próxima.
Links
Administering Servers by Using Policy-Based Management
http://technet.microsoft.com/en-us/library/bb510667(v=sql.105).aspx
Monitoring Best Practices by Using Policy-Based Management
http://technet.microsoft.com/en-us/library/cc645723(v=sql.105).aspx
Data Collection Terminology
http://technet.microsoft.com/en-us/library/bb677279(v=sql.105).aspx
Data Collector Architecture and Processing
http://technet.microsoft.com/en-us/library/bb677355(v=sql.105).aspx
SQL Server 2008 Management Data Warehouse
http://technet.microsoft.com/en-us/library/dd939169(v=sql.100).aspx
Atua no ramo de tecnologia há mais de 14 anos, dos quais a 11 trabalha como DBA. É Bacharel em Sistemas de Informação pela Universidade Presbiteriana Mackenzie. Certificado Microsoft SQL Server 2012, 2008, 2005 e 2000 com os títulos MCSE Data Plataform, MCITP Database Administrator, MCT, MCSA, MCTS e MCP. Palestrante em vários eventos de tecnologia como SQL Saturday, SQL Server Day, SQL Server Saturday Night e Microsoft Community Day. Chapter Leader do grupo SQLManiacs.Trabalha atualmente como especialista em SQL Server na empresa Indra.



