

Se quiser ler a publicação original, acesse aqui
Um projeto de software é muito mais complexo do que parece, e acho que todos sabem disso. Um erro que eu sempre vejo as equipes cometerem é incluir os logs no banco de dados (principalmente bancos de dados relacionais), e esta é uma prática que eu não recomendo.
No banco de dados relacional eu armazeno dados tabulares, que precisam de integridade referencial, que necessitam das propriedades ACID (basicamente o rolê é esse, mas se quiser saber mais, dá uma olhada na série SQL ou NoSQL aqui do blog http://db4beginners.com/blog/sql-ou-nosql/)
Longe de mim julgar as escolhas arquiteturais de outros profissionais, mas uma excelente escolha para cuidar de logs e monitorar as suas aplicações, bancos de dados, containers e sistema operacional é utilizar os produtos da Elastic Stack, popularmente conhecida como ELK Stack
E = Elasticsearch
L = Logstach
K = Kibana
A ideia é linda, pegamos os dados do banco de dados, indexamos com o Elasticsearch e visualizamos com o Kibana.
Mas vamos mais a fundo, e entender o que é cada um destes componentes:
O Elasticsearch é um mecanismo de pesquisa e análise RESTful distribuído, capaz de resolver um número crescente de casos de uso. Como o coração do Elastic Stack, ele armazena seus dados para que você possa fazer pesquisas. O Elasticsearch permite realizar e combinar muitos tipos de pesquisas – estruturadas, não estruturadas, geográficas, métricas, etc. Ele foi desenvolvido em Java, e sendo assim pode ser executado em plataformas diferentes.
A grande sacada aqui, é que é possível explorar uma quantidade muito grande de dados em velocidade muito alta.
O Logstash é um pipeline de processamento de dados, que ingere dados de várias fontes, os transforma e os envia para uma fonte como o Elasticsearch. Os dados geralmente estão espalhados em vários sistemas, e possuem vários formatos, o que é uma zebra! Mas o logstach tem diversos plugins diferentes, e sendo assim é possível orquestrar dados de diversas fontes diferentes.
O Kibana é uma plataforma de análise e visualização casada com o Elasticsearch. Você usa o Kibana para pesquisar, visualizar e interagir com os dados armazenados nos índices do Elasticsearch. O Kibana facilita a compreensão de grandes volumes de dados. Sua interface web permite criar e compartilhar dashboards com alterações nas consultas do Elasticsearch.
Instalando os Lindos
Eu resolvi usar o Docker para fazer este post, pela simplicidade… Momento preguiça sendo exposto aos leitores…
Para quem não conhece, o Docker é uma plataforma aberta para desenvolvedores e administradores de sistemas criar, enviar e executar aplicativos distribuídos, fornecendo virtualização extremamente leve no nível do sistema operacional, também conhecida como contêineres.
Eu precisei de um tutorial para fazer tudo funcionar, e o MVP Dan Clarke tem um que me ajudou muito (obrigado Dan!!!).
O primeiro passo para tudo funcionar, é ter o Docker instalado. Ele está disponível neste link.
Feito isso, crie um diretório local, e nele faça o download do conteúdo disponibilizado no github.
O próximo passo é abrir o prompt de comando, navegar até o diretório onde você fez o download, e executar o comandinho mágico:
docker-compose up
A primeira execução é um pouco demorada, mas depois de executar você já começa a ver a maravilha toda acontecendo!
Para ficar melhor, é hora de abrir o Kibana com o endereço
http://localhost:5601, o usuário e a senha estão no arquivo kibana.yml (C:\elastic\data\docker-elk-master\kiban\config\kibana.yml) , e se você não alterou nada, são username: elastic e password: changeme

Login realizado, somos bem recebidos no Kibana!
Vamos optar por explorar por nossa conta e risco…
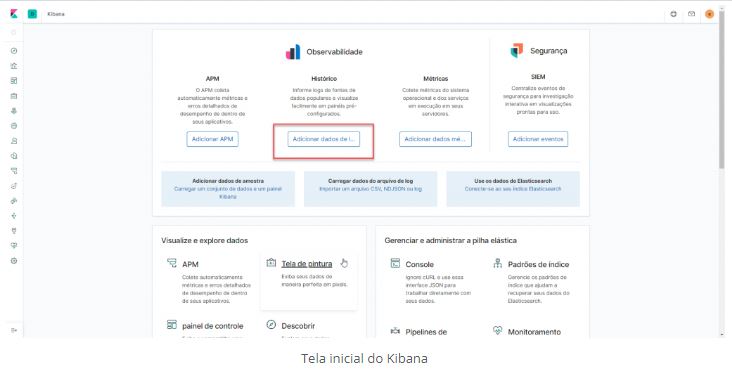
Existem várias possibilidades maravilhosas, mas eu quero monitorar os logs do MongoDB. Neste momento serão os logs automáticos, porque a primeira etapa será criar intimidade com o rolê, depois vamos nos aprofundando, e fazendo análises bem legais
Cliquei duas vezes no meu aplicativo mongod para iniciar um serviço do MongoDB (vamos usar o padrão, afinal é um teste).
Cliquei no botão destacado…
E na opção Métrics (só depois do print, vi que as telas estava traduzidas, péssimo! Mas já foi.)
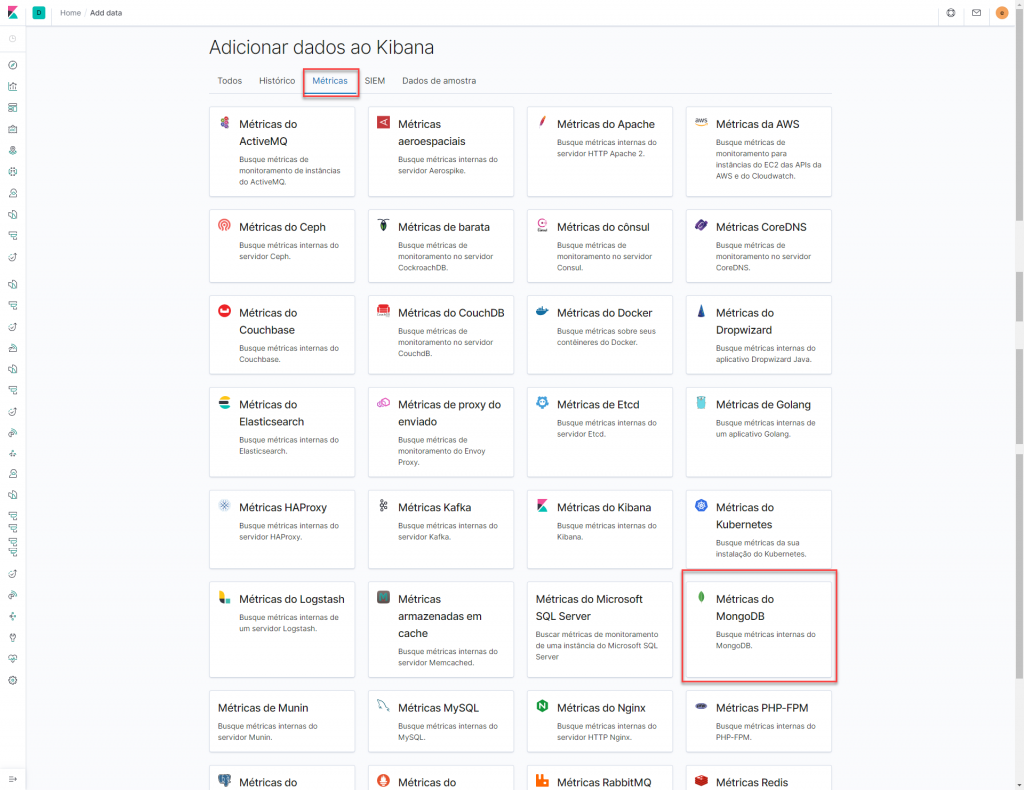
Configuramos o coletor das métricas (eu instalei no meu Windows mesmo)
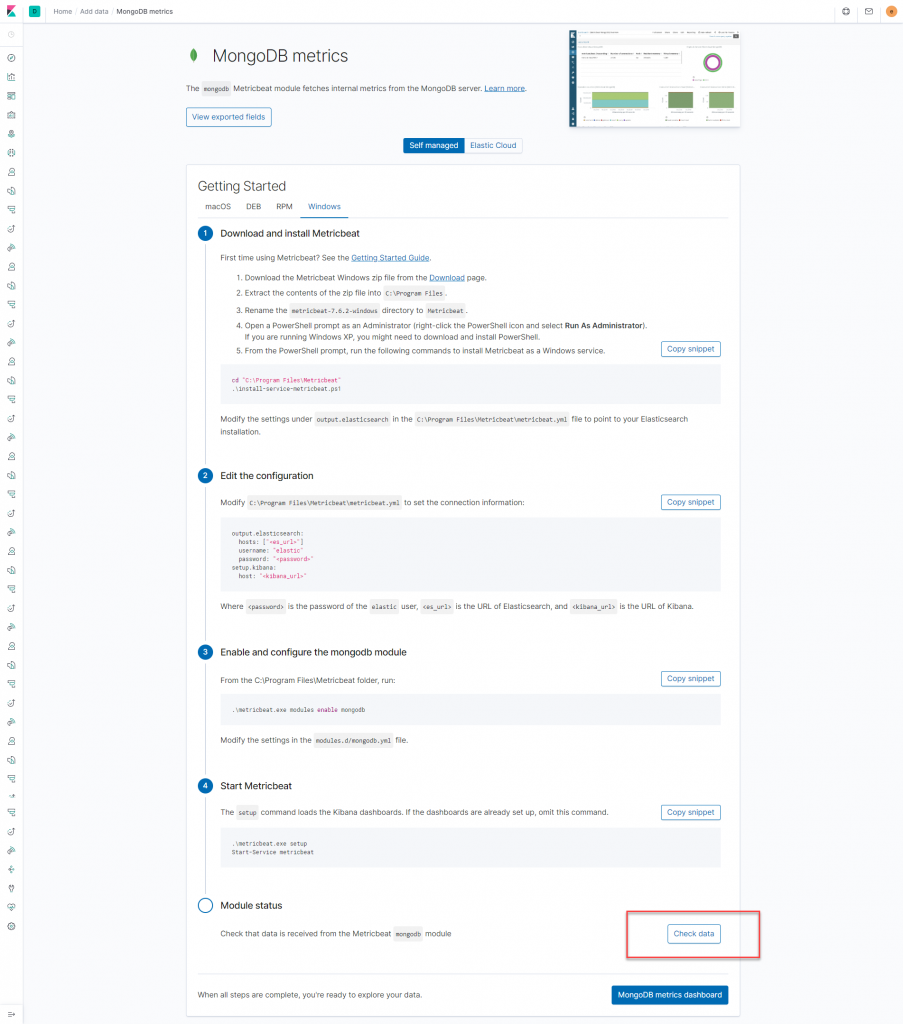
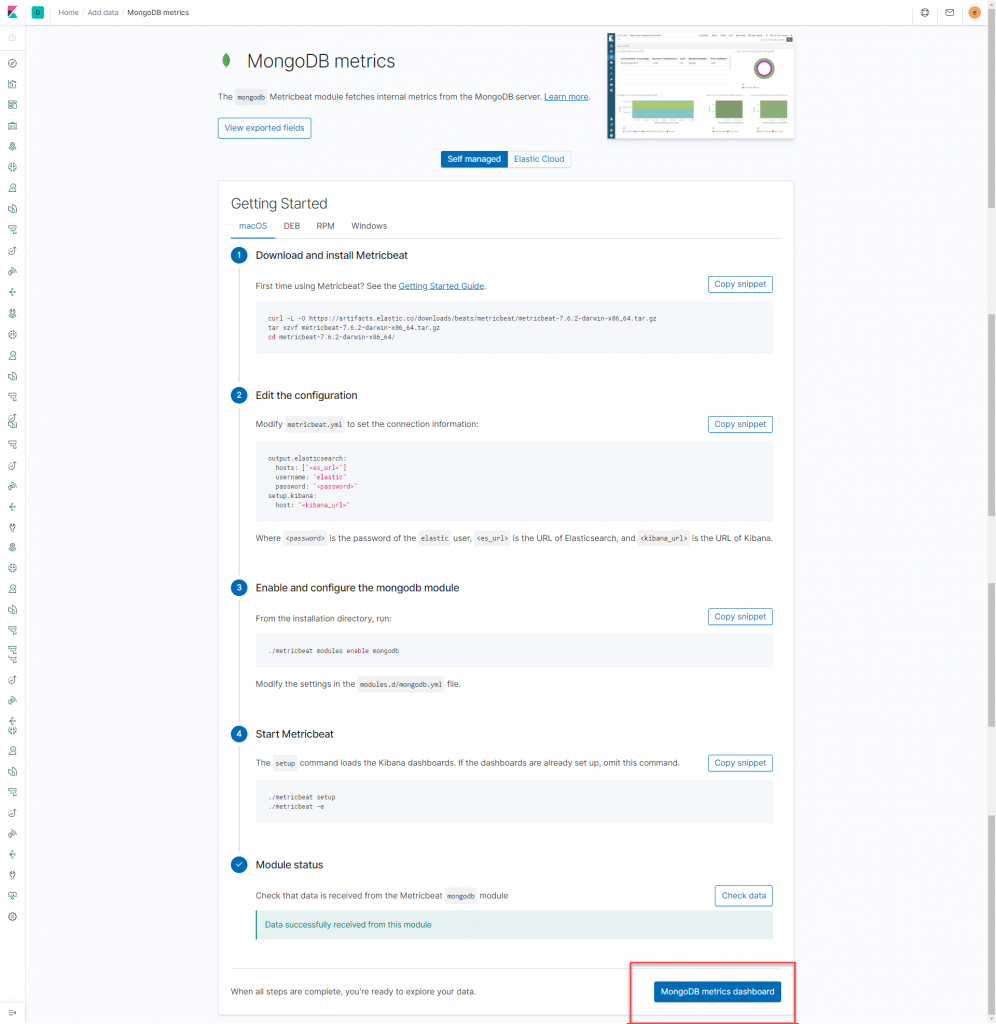
Clicando no botão destacado, hora de configurar os índices.
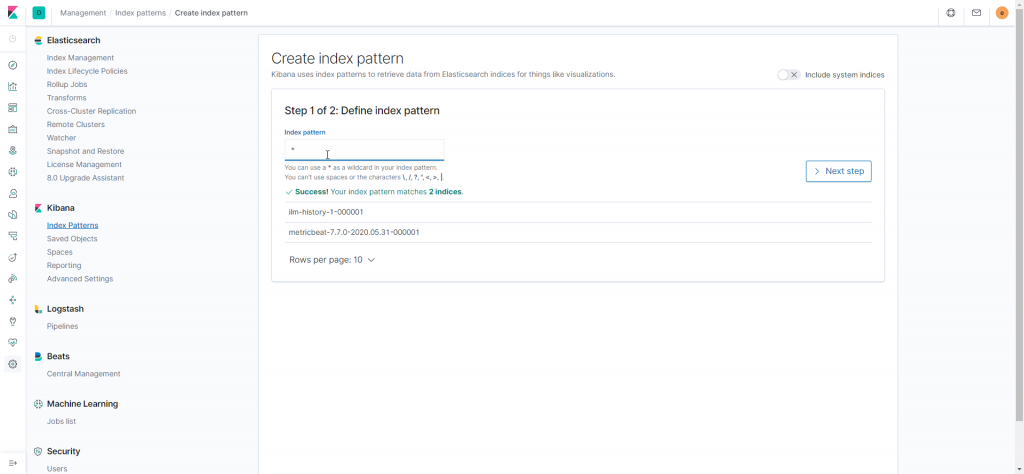
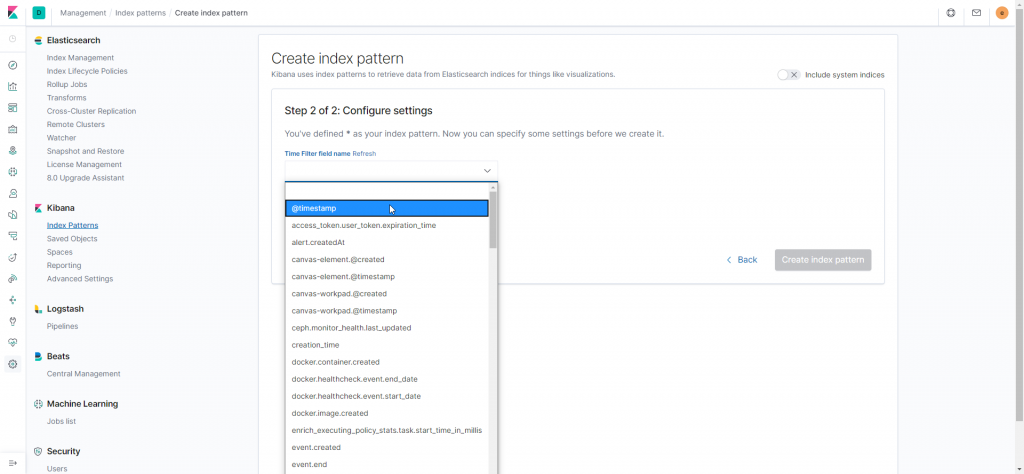
Tudo configurado, é hora de ver funcionando!
Agora temos nosso ambiente montado e funcionando.
Apesar da quantidade de passos que mostrei aqui, a configuração do nosso ambiente é super tranquila. Não tenham medo de seguir os passos que eu descrevi.
No nosso próximo post coletaremos dados do MongoDB e criaremos um dashboard com informções bem legais. Aguardem!
Referências
<https://www.elastic.co/pt/log-monitoring>
<https://www.devmedia.com.br/elasticsearch-como-gerenciar-logs-com-logstash/32939>

De 0 a 10, o quanto você recomendaria este artigo para um amigo?