


E chegamos ao quarto artigo da minha série de tutoriais de MongoDB para iniciantes em NoSQL. Caso esteja caindo de pára-quedas nesta série, seguem os links dos artigos e seus respectivos assuntos:
- Parte 1: conceitos básicos, criação do servidor, banco, coleções e documentos;
- Parte 2: CRUD (comandos básicos de consulta, inserção, atualização e exclusão);
- Parte 3: backup, restauração e alteração de metadados/schema;
Neste quarto artigo tratarei de um tópico complicado, denso e muitas vezes controverso: modelagem de dados orientada a documentos.
Me basearei aqui em experiências próprias de mais de dois anos trabalhando com esta tecnologia, em projetos de todos os tamanhos, além das guidelines oficiais, obviamente. Ao invés de ficar falando sobre como você deve modelar, usarei uma didática baseada em comparação entre exemplos com modelos relacionais famosos para auxiliar na assimilação dos conhecimentos.
Preparado para finalmente entender como modelar seus bancos MongoDB?
Princípios importantes
Primeiramente, tenha a mente aberta. Entenda que tudo que você aprendeu nas disciplinas de banco de dados da faculdade estão certas, mas em outro contexto, não nesse. Que as Formas Normais não significam nada aqui.
Eu tive a sorte de ter conhecido o MongoDB em um projeto já maduro que rodava há três anos e tinha muitos dados. Com isso, já aprendi do “jeito certo”, pois quando você cria um banco em um projeto pequeno, qualquer modelagem funciona e é difícil de imaginar como algumas decisões realmente podem lhe afetar no futuro.
O primeiro ponto a entender, e que muitas se recusam veemente é que você deve evitar relacionamentos entre documentos diferentes. Apesar dos avanços neste sentido nas últimas versões do MongoDB, este ainda é um banco não-relacional e, portanto, não faz sentido algum modelá-lo pensando em relacionamentos.
O segundo ponto é que documentos não são equivalentes a linhas de banco de dados. Essa é uma comparação muito simplória e que tende a levar ao erro. Documentos são entidades auto-suficientes, com todas as informações que lhes competem. Uma analogia que me ajuda a pensar nos documentos do jeito certo são as INDEXED VIEWS dos bancos relacionais. O plano é que, na maioria das consultas, com um filtro e sem “JOIN” algum, você consiga trazer todos os dados que necessita para montar uma tela de sua aplicação.
O terceiro e último ponto é manter simples. Não é porque o MongoDB permite que você aninhe até 100 níveis de subdocumentos dentro de um documento que você deve fazê-lo. Não é porque o MongoDB permite até 16MB por documento que você deve ter documentos com este tamanho. Não é porque você pode ter até 64 índices por coleção que você deve ter tudo isso. Essas e outras limitações estão lá na documentação oficial.
MongoDB não é magia, encare ele com a mesma seriedade que encara os bancos relacionais e estude bastante. A curva de aprendizagem inicial é realmente mais simples do que SQL, mas a longo prazo, é tão difícil quanto. Como já mencionei no artigo sobre persistência poliglota, os bancos não-relacionais não são melhores que os relacionais. Eles não eliminam os problemas dos relacionais, ao invés disso eles possuem os seus próprios problemas.
Para que você entenda tudo isso na prática, preparei um case simples de banco de dados que é bem comum, enquanto que futuramente espero ter tempo para apresentar cases mais complexos. Obviamente podem haver variações tanto na implementação relacional citada aqui, quanto a não-relacional que eu sugeri. Se apegue mais às ideias do que aos detalhes e use a seção de comentários para discutirmos o que você não concorda e/ou não entendeu.
Modelagem de Blog: Relacional
Bom, você está em um blog neste exato momento, então nada que eu disser aqui será uma novidade para você. Um blog possui basicamente artigos com id, título, data de publicação, conteúdo, categorias, tags, autor, status (rascunho, agendado, publicado, etc) e URL. As categorias possuem id, nome e descrição. Os autores possuem id, nome, foto, permissões, usuário, senha e bio. Além disso, temos os comentários. Ah os comentários, possuem toda uma complexidade própria: autor, data, texto, etc.
Em um banco relacional, como faríamos? (note que uso tabelas no singular e sem prefixos)
- Tabela 1: Artigo, com ID (PK), Titulo (NVARCHAR), DataPublicacao (DATETIME), Conteúdo (NVARCHAR), IDAutor (FK), Status (INT – considerando um enumerador) e URL (NVARCHAR). Esta é a tabela principal e como era de esperar, o IDAutor vai referenciar outra tabela. Mas cadê tags e categorias?
- Tabela 2: Autor, com ID (PK), Nome (NVARCHAR), Bio (NVARCHAR), Foto (NVARCHAR – porque guardarei apenas o caminho da foto), Usuario (NVARCHAR, unique) e Senha (NVARCHAR)
- Tabela 3: Categoria, com ID (PK), Nome (NVARCHAR) e Descricao (NVARCHAR). A descrição é útil nas páginas de posts de uma mesma categoria.
- Tabela 4: ArtigoCategoria, com ID (PK), IDArtigo (FK), IDCategoria (FK). Um artigo pode ter várias categorias e cada categoria pode estar em vários artigos, o clássico “N para N”, um câncer dos bancos relacionais na minha opinião.
- Tabela 5: Tag, com ID (PK), IDArtigo (FK), Nome (NVARCHAR). Aqui podemos fazer um “1 para N”, onde cada artigo pode ter várias tags ou um “N para N”, se quiser a não-repetição dos nomes de tags.
- Tabela 6: Comentario, com ID (PK), IDArtigo (FK), Nome (NVARCHAR – autor do comentário), Texto (NVARCHAR – o comentário em si), Data (DATETIME).
Pode ser mais complexo e poderoso que isso, mas vamos manter assim, visto que o objetivo aqui não é modelar o melhor banco de dados para blogs do mundo, mas sim apenas para mostrar como uma modelagem dessas pode ser feita em um banco relacional e em um não-relacional no mesmo artigo.
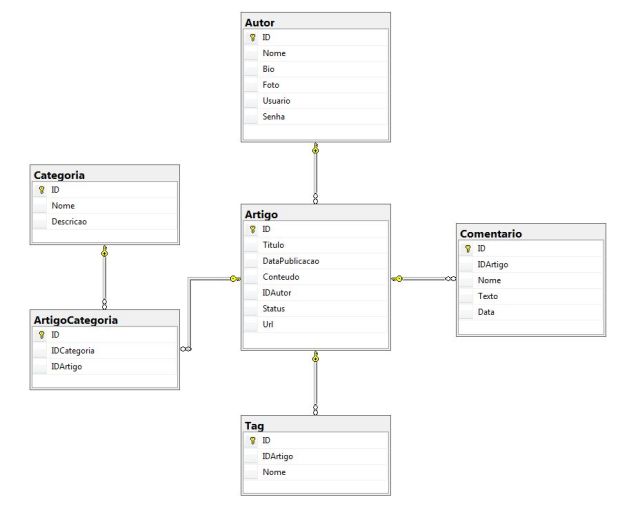
Considerando o banco descrito acima, como faríamos para montar uma tela de uma postagem completa no site do blog?
SELECT Artigo.*, Autor.Nome, Autor.ID FROM Artigo INNER JOIN Autor ON Autor.ID = Artigo.IDAutor WHERE Artigo.URL = 'XXX'
Essa consulta traz as informações do Artigo e de seu Autor (só o que importa do autor para a página do artigo). Mas e as tags e categorias? Precisamos de mais duas consultas para isso:
SELECT Categoria.* FROM Categoria INNER JOIN ArtigoCategoria ON ArtigoCategoria.IDCategoria = Categoria.ID WHERE ArtigoCategoria.ID = x;--esse ID eu pego na primeira consulta SELECT Tag.Nome FROM Tag WHERE IDArtigo = x;
Puxa, esqueci dos comentários ainda, certo? Vamos trazê-los também!
SELECT Comentario.* FROM Comentario WHERE IDArtigo = x
Modelagem de Blog: Não-Relacional
Em bancos de dados não-relacionais, o primeiro ponto a considerar é que você deve evitar relacionamentos, afinal, se for pra usar um monte de FK, use SQL e seja feliz!
A maioria das relações são substituídas por composições de sub-documentos dentro de documentos, mas vamos começar por partes. Primeiro, vamos criar um documento JSON que represente o mesmo artigo do exemplo anterior com SQL (dados de exemplo apenas), como pertencendo à uma coleção Artigo:
{
_id: ObjectId("123abc"),
titulo: "Tutorial MongoDB",
dataPublicacao: new Date("2016-05-18T16:00:00Z"),
conteudo: "Be-a-bá do MongoDB",
idAutor: ObjectId("456def"),
status: 1,
url: "http://www.luiztools.com.br/post/1"
}
Primeira diferença: aqui os IDs não são numéricos auto-incrementais, mas sim ObjectIds auto-incrementais. Segunda diferença: não há schema rígido, então eu posso ter artigos com mais informações do que apenas estas, ou com menos. Mas e aquele idAutor ali?
Se eu colocar daquele jeito ali, com idAutor, quando eu for montar a tela do artigo eu sempre teria de ir na coleção de Autores para pegar os dados do autor, certo? Mas se eu sei quais informações eu preciso exibir (apenas nome e id, assim como na consulta SQL), o certo a se fazer aqui é reproduzir estas informações como um subdocumento de artigo, como abaixo:
{
_id: ObjectId("123abc"),
titulo: "Tutorial MongoDB",
dataPublicacao: new Date("2016-05-18T16:00:00Z"),
conteudo: "Be-a-bá do MongoDB",
autor: {
_id: ObjectId("456def"),
nome: "Luiz"
},
status: 1,
url: "http://www.luiztools.com.br/post/1"
}
Esse é o jeito “certo” de fazer com MongoDB! Note que o subdocumento autor possui apenas os dados necessários para montar uma tela de artigo. Mas se precisarmos depois da informação completa do autor, podemos pegá-la a partir de seu id.
Como MongoDB não garante integridade referencial por não possuir FK, temos de tomar muito cuidado quando você for excluir um autor, para desvinculá-lo em todos os artigos dele, e quando você for atualizar o nome dele, para atualizar em todos artigos dele.
Já a coleção Autor, fica com documentos bem parecidos com a tabela original em SQL:
{
_id: ObjectId("456def"),
nome: "Luiz Duarte",
bio: "Empreendedor, professor, etc",
foto: "1.jpg",
usuario: "luiz",
senha: "ds6dsv8ds5v76sd5v67d5v6"
}
Note que aqui eu não vou embutir todos os artigos deste autor, pois seria inviável. O foco do blog são os artigos, não os autores, logo, os artigos vão conter o seu autor dentro de si, e não o contrário!
Um adendo: MongoDB trabalha muito bem com arquivos binários embutidos em documentos, então se quisesse usar um binário de imagem no campo foto, funcionaria perfeitamente bem, melhor que no SQL tradicional (BLOBs, arghhh!).
Mas e as categorias e tags? Como ficam?
Primeiro que aqui não precisamos de tabelas-meio quando temos relacionamento N-N. Todos os relacionamentos podem ser representados na modalidade 1-N usando campos multivalorados, como mostrado no exemplo abaixo, de uma v3 do documento de artigo:
{
_id: ObjectId("123abc"),
titulo: "Tutorial MongoDB",
dataPublicacao: new Date("2016-05-18T16:00:00Z"),
conteudo: "Be-a-bá do MongoDB",
autor: {
_id: ObjectId("456def"),
nome: "Luiz"
},
status: 1,
url: "http://www.luiztools.com.br/post/1",
categorias: [{
_id: ObjectId("789ghi"),
nome: "cat1"
}],
tags: ["tag1", "tag2"]
}
Tags são apenas strings tanto na modelagem relacional original quanto nesta modelagem orientada a documentos. Sendo assim, um campo do tipo array de String resolve este cenário sem maiores problemas.
Já as categorias são um pouco mais complexas, pois podem ter informações extras como uma descrição. No entanto, como para exibir o artigo na tela do sistema nós só precisamos do nome e do id das categorias, podemos ter um array de subdocumentos de categoria dentro do documento de artigo.
Em paralelo deveremos ter uma coleção de categorias, para armazenar os demais dados, mantendo o mesmo ObjectId:
{
_id: ObjectId("789ghi"),
nome: "cat1",
descricao: "Categoria bacana"
}
Novamente, caso no futuro você venha a excluir categorias, terá de percorrer toda a coleção de artigos visando remover as ocorrências das mesmas. No caso de edição de nome da categoria original, também. Com as tags não temos exatamente este problema, uma vez que elas são mais dinâmicas.
Para encerrar, temos os comentários. Assim como fizemos com as categorias, vamos embutir os documentos dos comentários dentro do documento do artigo ao qual eles fazem parte, afinal, não faz sentido algum eles existirem alheios ao artigo do qual foram originados.
{
_id: ObjectId("123abc"),
titulo: "Tutorial MongoDB",
dataPublicacao: new Date("2017-10-18T16:00:00Z"),
conteudo: "Be-a-bá do MongoDB",
autor: {
_id: ObjectId("456def"),
nome: "Luiz"
},
status: 1,
url: "http://www.luiztools.com.br/post/1",
categorias: [{
_id: ObjectId("789ghi"),
nome: "cat1"
}],
tags: ["tag1", "tag2"],
comentarios: [{
_id: ObjectId("012jkl"),
nome: "Hater",
texto: "Não gosto do seu blog",
data: new Date("2017-10-18T18:00:00Z")
}]
}
Note que aqui optei por ter um _id no comentário, mesmo ele não possuindo uma coleção em separado. Isso para que seja possível mais tarde moderar comentários.
E esse é um exemplo de documento completo, modelado a partir do problema de um site de artigos, blog, wiki, etc.
Ah, mas e como fazemos a consulta necessária para montar a tela de um artigo? Lembra que em SQL eram inúmeras consultas cheias de INNER JOINs? No MongoDB, precisamos de apenas uma consulta, bem simples, para montar a mesma tela:
> db.Artigo.findOne({url: 'http://www.luiztools.com.br/post/1'});
Essa consulta traz os mesmos dados que todas aquelas que fiz em SQL juntas. Isso porque a modelagem dos documentos é feita sem relacionamentos externos, o documento é auto-suficiente em termos de dados, como se fosse uma VIEW do SQL, mas muito mais poderoso.
Claro, existem aqueles pontos de atenção que mencionei, sobre updates e deletes, uma vez que não há uma garantia nativa de consistência entre coleções. Mas lhe garanto, a performance de busca é incomparável, uma vez que a complexidade é baixíssima. Você inclusive pode criar um índice no campo url da coleção Artigo, para tornar a busca ainda mais veloz, com o comando abaixo:
> db.Artigo.createIndex({url: 1});
Demais, não?!
Você pode estar preocupado agora com a redundância de dados, afinal diversas strings se repetirão entre os diversos anúncios, como o nome do autor, tags, nomes de categoria, etc. Não se preocupe com isso, o MongoDB trabalha muito bem com volumes muito grandes de dados e desde que você tenha bastante espaço em disco, não terá problemas tão cedo. Obviamente não recomendo que duplique conteúdos extensos, mas palavras como essas que ficaram redundantes na minha modelagem não são um problema.
No entanto, lidar com subdocumentos e campos multivalorados adiciona um pouco mais de complexidade à manipulação do MongoDB, e trato disso nesse artigo, que é continuação da série!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?