

Conversando com a minha amiga querida Cristina Luz sobre como juntar dados de mais de uma coleção no MongoDB, ela falou que esse assunto seria um bom post para o blog…. Seguindo a dica vamos conversar um pouco sobre o Aggregation Framework (que neste post vou chamar de AF) e sobre como fazer um LEFT JOIN no MongoDB.
O Aggregation Framework
Em meu momento tia velha vou confessar que eu tinha algumas resistências com o AF antes da versão 4.0 do MongoDB. Achava super chato criar consultas complexas sem uma interface gráfica para me ajudar (podem me chamar de DBA Nutella, mas este é um caso onde eu penava!)…
Quando eu fui para o MongoDB World 2018, todos esperavam as transações, mas a novidade que eu mais gostei foi o Aggregation Pipeline Builder, que faz parte do MongoDB Compass e também do MongoDB Atlas.
As operações feitas no AF processam registros e retornam resultados computados. De maneira mais simples eu tenho um conjunto de dados, eles são processados em várias etapas, e o resultado de uma etapa serve de entrada para a etapa seguinte, até que o processamento termina, e os dados resultantes dão origem a um documento, ou uma coleção ou uma view materializada (assunto do último post, e novidade fofa da versão 4.2 do MongoDB).
Cada etapa do processamento é chamada de estágio, e não há limites para o número de estágios que um pipeline de agregação pode ter. O legal é que os pipelines podem ser tão simples ou complexos quanto você desejar.
Para fazer as operações com os dados, usamos operadores (observe que eles começam com $). Cada operador tem seus parâmetros e faz uma operação diferente nos dados, neste artigo o foco é mostrar como juntar dados de duas coleções, e por isso falaremos sobre o operador $lookup.
Não se intimide há muitos operadores lindos, e sempre vale uma visita na documentação oficial para conhecê-los.
Aggregation Pipeline Builder
Tanto no MongoDB Compass quanto no MongoDB Atlas as interfaces são muito parecidas, para deixar este post com menos prints eu enumerei os componentes desta ferramenta fofa.
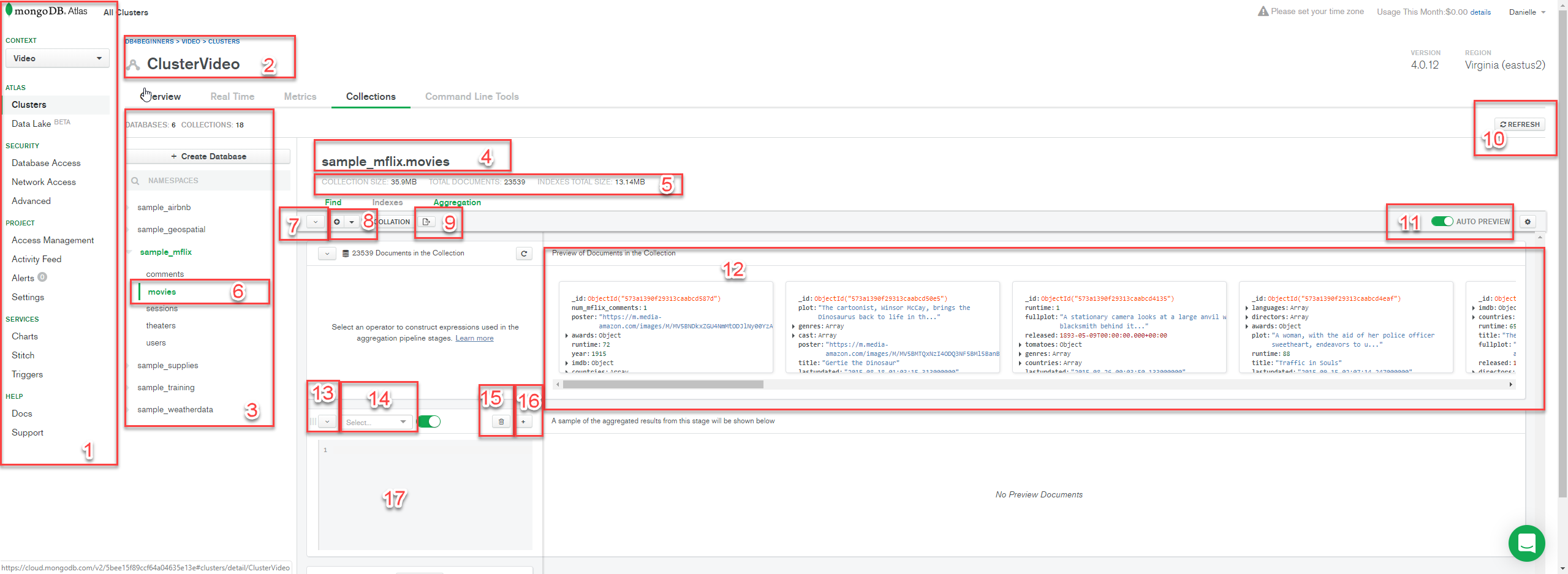
1 – Menu do MongoDB Atlas
2 – Informações do meu cluster
3 – Meus bancos de dados e as minhas coleções
4 – Nome do banco de dados e da coleção que eu manipularei os dados
5 – Informações da coleção selecionada
6 – Veja que a coleção selecionada tem um indicador verde ao lado esquerdo
7 – Mostra ou esconde os estágios
8 – Permite criar um pipeline a partir de um texto (como se fosse uma importação, você cria o pipeline, salva como texto e depois pode abrir)
9 – Permite importar o pipeline para Node, Java, C# e Python (amo esta funcionalidade, porque eu crio o pipeline em uma interface gráfica e depois posso copiar para a minha aplicação)
10 – Atualiza a tela
11 – Oculta ou exibe a pre- visualização dos dados
12 – Pre visualização dos documentos da coleção
13 – Mostra ou oculta o estágio
14 – Mostra a lista de todos os estágios disponíveis. Quando um estágio é escolhido uma explicação, a listagem dos parâmetros e sua descrição é exibida no item 17
15 – Exclui o estágio
16 – Adiciona um novo estágio
17 – Neste espaço eu forneço os parâmetros para o operador escolhido no item 14
JOIN no MongoDB?
Eu sempre olho este operador com um pouco de cuidado, por que o uso excessivo dele pode indicar erros de modelagem. Mas ele existe, e se usado nos momentos certos ajuda muito, porque permite buscar dados de uma outra coleção, que obedeçam a uma determinada condição de igualdade, da mesma forma que um LEFT JOIN.
Antes de mostrar um exemplo, vamos conhecer a sintaxe deste operador:
db.Coleção.aggregate([
{
$lookup:
{
from: <nome da Coleção onde vamos buscar os dados>,
localField: <nome do atributo usado na condição de igualdade, na coleção origem, aqui chamada de Coleção>,
foreignField: <nome do atributo usado na condição de igualdade na tabela destino, onde buscaremos os dados>,
as: <atributo que receberá os novos dados >
}
}
Em nosso exemplo temos uma coleção de filmes, chamada movies, queremos buscar os dados dos comentários de cada filme. Os comentários estão na coleção comments.
Agora que sabemos em quais coleções estão os dados que buscamos, precisamos identificar os atributos que permitem estabelecer uma condição de igualdade entre as coleções.
De forma bem rápida vamos olhar os atributos dos documentos.
Neste ponto vou fazer uma observação, a melhor ferramenta para análise do schema é o MongoDB Compass, a análise que eu estou fazendo é bem superficial, mas válida a título de exemplo.
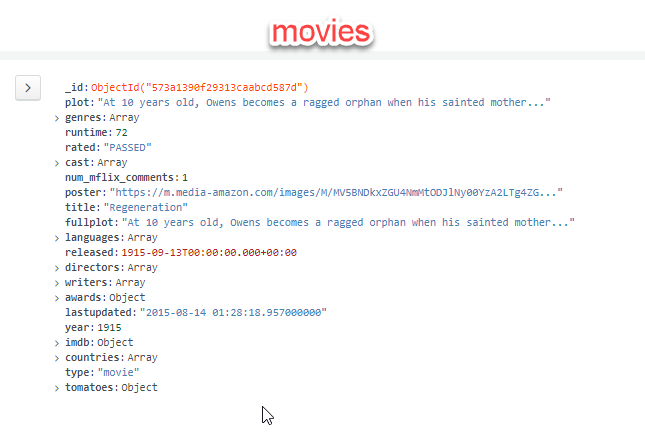

Podemos ver que a coleção comment possui o atributo movie_id que faz referência ao atributo _id da coleção movies.
Vamos armazenar os comentários em um novo atributo chamado comentarios.
Abra o MongoDB Atlas, clique em Collections
Selecione o banco de dados e a coleção
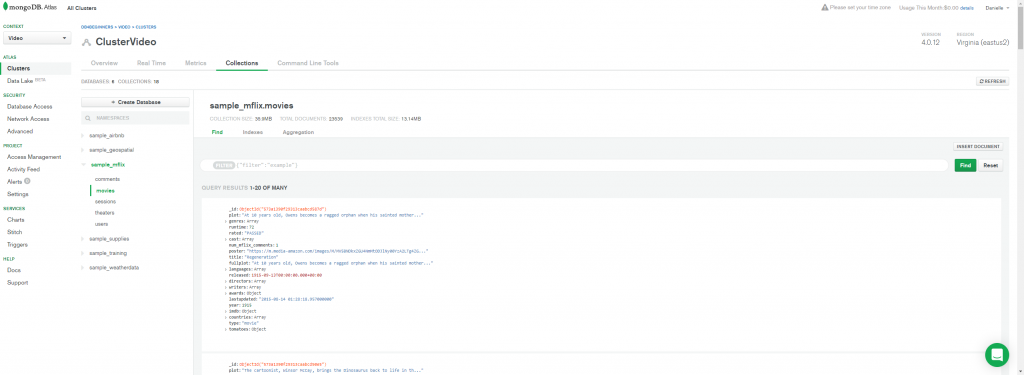
Clique em Aggregation
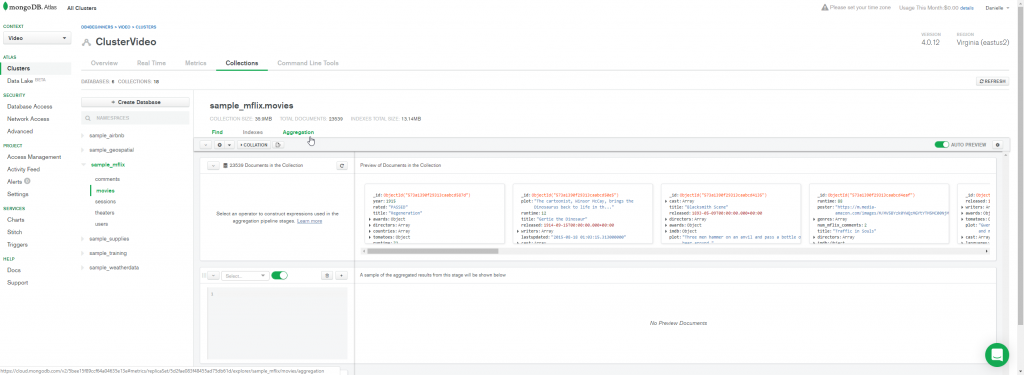
Escolha o operador $lookup

Veja que ao escolher o operador já aparece uma explicação dos parâmetros e o tipo de dados esperado para cada um deles.
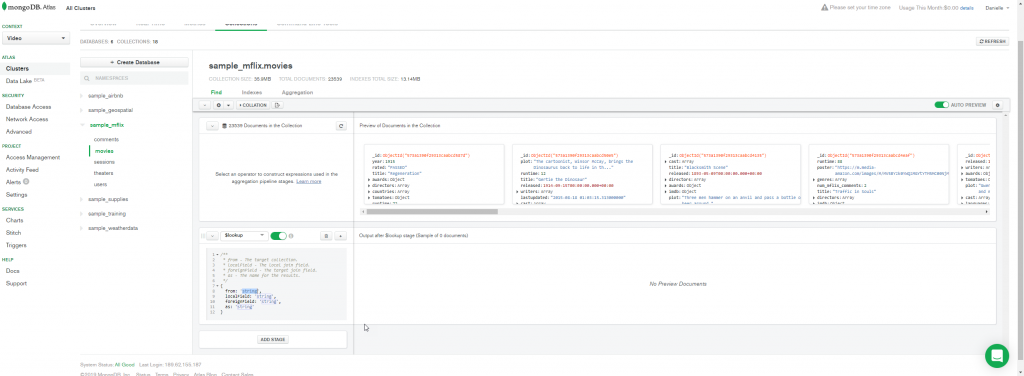
Veja que o atributo comentarios foi incluído nos documentos. Ele é um array que contém todos os comentários de um filme
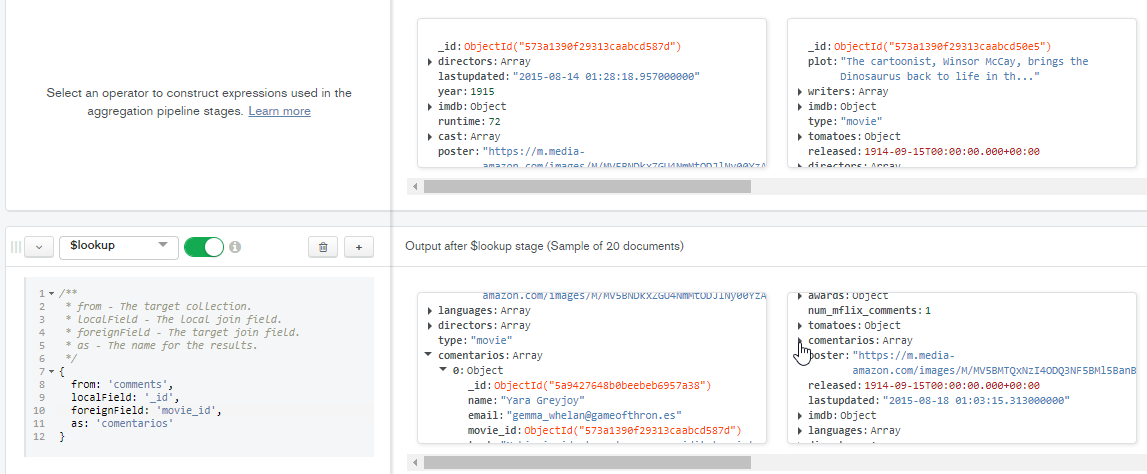
O código que eu usei neste exemplo
/**
* from - The target collection.
* localField - The local join field.
* foreignField - The target join field.
* as - The name for the results.
*/
{
from: 'comments',
localField: '_id',
foreignField: 'movie_id',
as: 'comentarios'
}
Pipeline criado, basta gerar o código na linguagem de programação usada pela sua aplicação.

Conclusão
O AF é uma fofura! Permite fazer análises complexas com dados armazenados no MongoDB.
Neste post usamos o MongoDB Atlas, os dados de exemplo fornecidos pela MongoDB e o Aggregation Pipeline Builder.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?