



Introdução para modelagem de dados para banco orientado a documentos
No seguinte artigo, Danielle Monteiro apresenta uma introdução para modelagem de dados para banco orientado a documentos.


Introdução
Quando comecei este artigo eu tinha traçado um roteiro bacana, mas resolvi mudar os rumos e investir em um assunto muito importante: a modelagem para bancos de dados orientados a documentos, até porque esse assunto não foi muito abordado em português.
Prometo não deixar meu lado AD interferir! Mas a modelagem de dados é a chave do sucesso! Como criar algo que você não conhece?
A modelagem de dados é um processo de abstração. Você começa com as necessidades de negócio, e então você mapeia essas necessidades em estruturas para armazenar e organizar seus dados. Simples assim!
O processo envolve a identificação de entidades e os relacionamentos entre as entidades. Para criar seu modelo, identifique os padrões usados para acessar os dados e os tipos de consultas a serem realizadas.
É, amigos, a grande dificuldade da modelagem é entender. Desenhe, rabisque, veja as relações, use um diagrama UML, ou Entidade relacionamento, ou não use nenhum, e escreva frases, mas represente seu dados de forma que você entenda e possa compartilhar o seu entendimento com a sua equipe. Errar no começo do projeto é muito mais simples do que construir um BD que não atende as necessidades de negócio!
Quando modelamos um banco de dados NoSQL orientado a documentos, precisamos lembrar que não existem respostas absolutas, por isso eu sigo alguns princípios, e são eles que eu quero compartilhar com vocês:
- Começo sempre pelo modelo lógico, porque meu objetivo inicial é entender como as entidades são
- Identifico as operações mais importantes para o negócio
- Identifico as operações que ocorrem mais vezes
- Se as operações predominantes são as consultas, meu objetivo será criar estruturas agregadas de forma que a aplicação acesse o banco de dados o menor número possível de vezes para recuperar os dados. Neste caso eu aceito ter dados redundantes
- Se a operação predominante são as alterações e inclusões de dados, eu penso em estruturas mais normalizadas, para que a operação seja o mais granular possível e eu não tenha tantos dados redundantes
E se todas as operações ocorrem e são importantes? Você precisará avaliar qual será a estratégia mais adequada! Lembre-se de que não existe mágica e nem uma verdade absoluta, mas pense sempre nos seguintes fatores:
- Como você garantirá a qualidade dos dados: dados redundantes não são problemas quando têm qualidade
- O hardaware é um fator limitante?
- Se o disco é um fator limitante, fique atento com as desnormalizações
- Tenha atenção com as operações mais importantes para o negócio – elas devem ser pensadas para atender aos requisitos da melhor maneira possível
A modelagem e os bancos de dados orientados a documentos
O fato de não ter schema não implica na ausência da modelagem! Espero ter te convencido disso, mas devemos considerar que temos diferentes tipos de bancos de dados NoSQL e que a implementação física de cada um deles é muito diferente, e deverá ser considerada no momento adequado.
Primeiro tentamos entender o negócio, sem o compromisso com os padrões regras (me perdoem, ADs!). Na segunda etapa podemos criar um diagrama usando uma convenção como UML. E na última etapa precisamos definir as estruturas, atributos, tipos de dados, etc.
Perdoem as minhas opiniões pessoais – sem elas não teria graça nenhuma ler, e muito menos escrever este artigo!
Bancos de dados orientados a documentos recebem dados em um formato semi-estruturado, normalmente um JSON. O mais famoso deles é o MongoDB, que segundo o site DB-Engines.com, é o banco de dados NoSQL mais usado no mundo.
No MongoDB um JSON é chamado de documento. Um conjunto de documentos dá origem a uma coleção e um conjunto de coleções forma um banco de dados.
Cada documento possui um conjunto de atributos, e cada atributo tem um tipo e um valor. Atenção neste ponto! Não se iluda achando que todos os valores dos atributos em um JSON são string! Não são. E se você criar seus documentos dessa forma, terá problemas de desempenho nas consultas.
Modelar um banco de dados é extremamente importante porque um bom esquema pode significar a diferença entre:
- Bom ou mau desempenho.
- Poucas consultas ou muitas.
- Ter dados na memória ou fazer buscas no disco.
O objetivo de modelar um banco de dados orientado a documentos é minimizar a quantidade de “idas ao banco de dados”, para que a aplicação seja mais rápida.
Não pense que para minimizar a quantidade de acessos ao Banco de Dados basta você colocar todos os seus atributos no mesmo documento! Desde já parta da premissa:
- Informações acessadas juntas devem fazer parte do mesmo documento
- Informações raramente acessadas devem ser separadas
Quando você está modelando seu banco de dados, precisa decidir se os dados serão referenciados ou embedding.
Vamos entender melhor esses conceitos!
Quando eu falo de um documento embedding eu estou falando de uma estrutura não normalizada, onde os dados normalmente são acessados juntos – basicamente, um documento dentro do outro.
Essa estrutura bacana é ideal quando:
- A operação principal são as leituras, o que não impede de ser usada em aplicações com um grande volume de escritas. Eu vejo essa estrutura com receios se a sua aplicação faz muitas alterações nos dados. Neste caso, é preciso ser cuidadoso porque a mesma informação está replicada em vários documentos. Sendo assim, a atualização dessa informação pode precisar ser feita em muitos lugares, sob pena de ter dados inconsistentes
- Uma entidade não existe sem a outra. Por exemplo, não faz sentido falar de itens de pedido sem os pedidos
- Coleções que contém um número grande de documentos pequenos
- Dados que são lidos sempre juntos

A outra possibilidade é a de ter um documentos separado, mas um dos documentos tem a referência para o outro. Essa é a estrutura referenciada, onde minimizamos a quantidade de dados duplicados, aumentamos o desempenho nas operações de escrita, mas diminuímos o desempenho nas consultas.
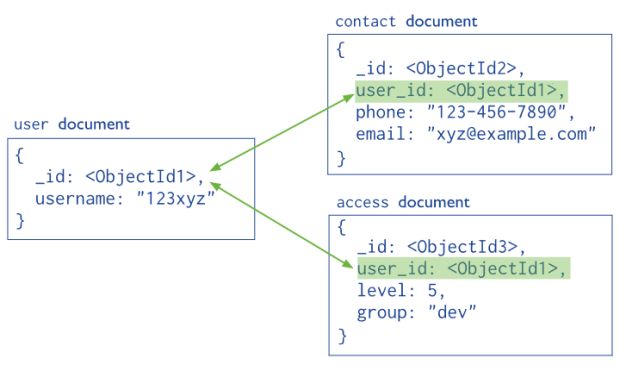
Use essa estrutura se:
- Quando uma parte do documento é frequentemente lida/atualizada e a outra parte não
- O tamanho do documento excede 16MB
- Quando os dados não devem ser duplicados
- Quando um objeto é referenciado em muitos outros
Conclusão
Esse é um assunto bem polêmico. Conheço profissionais excelentes que defendem que não há tempo para modelagem de dados nos projetos de software “do mundo real”.
Acredito que sem ela os projetos têm grande chances de falhar e, por isso, a minha dica é que você tente entender as necessidades de negócio e crie um modelo que atenda as necessidades que você conhece.
As mudanças são naturais, possíveis e mais fáceis em um banco de dados orientado a documentos, como o MongoDB. Eu as vejo como uma evolução e não como um problema, e tenho certeza que se modeladas elas serão mais fáceis e trarão mais benefícios para a sua organização.
Se você quer saber mais sobre o MongoDB, acesse DB4Beginners.com/MongoDB. Publiquei uma série de artigos sobre esse banco de dados incrível lá.
É mestre em Engenharia da Computação, Microsoft MVP, MongoDB Female Innovator e autora do blog DB4Beginners.com. Ajuda desenvolvedores iniciantes a modelar e consultar bancos de dados relacionais e NoSQL para que eles possam criar ótimos aplicativos e conquistar os melhores empregos.



