



Desempenho do processador x desempenho do SQL Server – Parte 03
Neste artigo, Rodrigo Ribeiro Gomes apresenta um caso onde ele pôde detectar problemas de lentidão analisando o desempenho da máquina.


São 7 horas da manhã, e recebo uma ligação da equipe de BI, dizendo que todas as cargas estão 50% mais lentas. O caos se instaura na equipe, pois os relatórios do dia não estariam prontos.
Isso aconteceu depois de uma migração. A máquina antiga era virtual. E a máquina nova? Física – com configurações idênticas! Como pode? O mínimo era ter desempenho igual, não inferior. O que aconteceu?
Vou contar melhor essa história
Bem-vindo de volta!
No último artigo desta série você viu como uma redução de 50% no clock da CPU impactou diretamente no tempo das consultas de um SQL Server.
Se você ficou surpreso com isso, saiba que não é algo novo. Isso se dá por uma simples teoria matemática: velocidade e tempo são grandezas inversamente proporcionais.
Se eu dobrar a velocidade, eu faço na metade do tempo. Do mesmo jeito que, se eu usar metade da velocidade, eu gasto o dobro do tempo.
E foi exatamente isso que aconteceu no exemplo do artigo anterior: a velocidade da CPU diminuiu e o tempo das instruções e – consequentemente – da nossa query, aumentaram.
Mas por que você se preocuparia com isso? Afinal, quem seria louco o suficiente para baixar a velocidade da CPU pelo gerenciamento de energia? É aí que voltamos a nossa historinha.
Um caso real e inesquecível
Que absurdo é esse onde uma máquina física, idêntica à virtual (pra ser mais preciso, idêntica ao host da máquina virtual), é muito mais lenta?
Gastamos um bom tempo checando tudo – configurações da instância, bloqueios, disco, etc. Até que tive a ideia de fazer um simples teste de CPU.
Vou comparar quanto tempo levo pra executar uma quantidade de instruções na instância antiga e na nova. Como fazer isso no SQL Server? Um simples loop:
DECLARE @i bigint = 10000000, @start datetime = current_timestamp
while @i > 0 set @i = @i - 1;
select datediff(ms,@start,current_Timestamp) as LoopTimeEste código SQL é muito simples:
- 1. A variável @i começa em 10 milhões. Meu objetivo é decrementar ela até que chegue em zero. O processador vai ser utilizado basicamente para operações aritméticas, que são simples e rápidas.
- 2. Eu utilizo a variável @start para gravar a data e hora atuais, antes de começar o loop WHILE.
- 3. Ao final do meu loop while, eu calculo quanto tempo se passou, subtraindo a data de agora pelo valor gravado em @Start.

Este é um código que vai gastar apenas CPU. Não tem disco, rede, memória, ou outra coisa significativa envolvida. Mais de 99% do tempo desse script será gasto executando instruções na CPU.
Quando eu executei este script na máquina antiga ele me retornou um tempo de cinco segundos. Quando executei na nova, variava de 7 a 8 segundos.
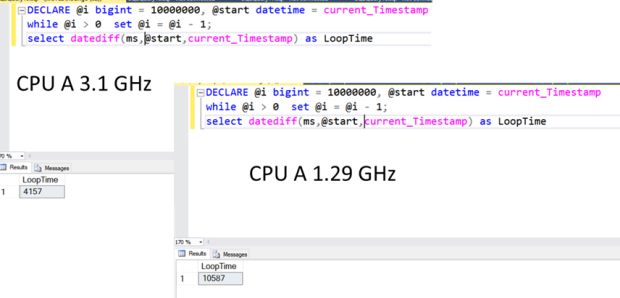
Pronto, tinha achado um norte. O próximo passo, nesse caso, foi verificar se o problema estava dentro do SQL Server, ou era algo generalizado, no sistema operacional.
Então, fiz a mesma versão desse script, em PowerShell:
(Measure-Command { [int]$i = 10000000; while($i--){}; }).TotalMillisecondsE novamente comparei o resultado com a máquina nova e antiga! Mesma situação. Dessa vez excluí o SQL Server do problema.
O script na máquina antiga (virtual) retornava um valor muito inferior ao da máquina nova (física). A partir daí, usei o CPU-Z (era um Windows Server 2008), e constatei que o clock do processador do servidor novo estava operando a 2.2 GHz, enquanto que o CPU-Z da máquina virtual reportava 2.5 GHz. Uma diferença de apenas 300 MHz foi suficiente para dar dor da cabeça no ambiente de BI!
Você pode estar se perguntando o porquê de apenas 300 MHz causar 50% de lentidão no processo de carga. A razão é muito simples:
- O processo de carga não envolve apenas uma única consulta – são várias consultas. Consultas de 2, 3, 15 minutos, subindo para 4, 6, 18 minutos, respectivamente. As consultas pequenas também.
- A instância onde ocorria tudo isso, além de concorrer com um Analysis Service e Integration Services, que também estavam sendo impactados pelo problema, tinham outras queries em execução, de outros relatórios, e não somente do processo de carga.
- Todo o sistema operacional lento. Logo, gravações em disco mais lentas, comunicação de rede mais lenta. Toda a concorrência do processador estava maior. Uma vez que a CPU está mais lenta, tudo demora mais na CPU, e aí aumenta a espera por CPU
O problema foi resolvido depois que, comprovado para a equipe de infraestrutura que o problema era da máquina, eles abriram chamado no fabricante, que detectou uma atualização de BIOS.
E aí resolveu tudo (depois de várias tentativas por parte deles, como mudar configuração da BIOS, colocar a máquina com 100% de energia, já que ela aceitava quatro cabos de força, e apenas dois estavam plugados, etc.).
Isso levou meses, e tivemos que desfazer a migração até lá. Quando nos foi reportado que a máquina estava pronta, apenas repetimos todos os testes e dessa vez os tempos estavam iguais.
Prosseguimos com a migração, e tudo certo. O processo de carga estava até um pouco mais rápido!
Epidemia
Alguns meses depois deste problema, um colega me procurou e me relatou sobre um problema de lentidão após um ambiente extremamente crítico migrar do SQL 2008 R2 para o SQL 2014. Chegaram a cogitar problema com o novo CE.
De novo, o problema era um clock mais lento nas novas máquinas.
Muito antes de fazer parte do #TeamFabricioLima, o Fabrício me contou sobre o mesmo sintoma: novo servidor e tudo mais lento e, novamente, encontramos problemas com velocidade do clock.
Depois disso, achei muitos problemas como este, até em ambiente com outros bancos de dados, com outras tecnologias. Me dei a liberdade de batizar isso de epidemia de ClockLentopsia.
A questão aqui é: quantas vezes você parou pra validar o desempenho do seu processador? Você coloca isso no seu checklist de migração? Um conceito extremamente simples, que pode estar afetando seu ambiente.
Você percebeu no artigo anterior que uma query de 266 ms foi para mais de 500ms? Na casa dos milissegundos ninguém percebe isso. Você já pode ter migrado um ambiente sem nem sequer notar que a CPU ficou mais lenta, mas as queries podem ter saído de 50ms, para 100ms.
Mas aqui vai um conselho: sempre verifique! Sempre valide! Até agora nesta série você já aprendeu a usar duas ferramentas e tem dois scripts para validar.
Coloque isso em seus processos e durma feliz após as migrações críticas! Não estou dizendo que este sempre vai ser o problema, mas se for, você vai pegá-lo antes que o inverso aconteça.
E se ainda você precisar de uma força para avaliar casos estranhos como estes, pode chamar a gente do #TeamFabricioLima, que vamos até os bits e bytes da sua CPU para achar o problema!
E você acha que acabou por aqui? Nada disso. Ainda tem muito o que falar sobre CPU!
No próximo artigo quero explicar uma diferença muito importante sobre o tempo de CPU e o percentual de CPU. Você vai passar a analisar as queries de outra forma!
Até lá!
Consultor de Banco de Dados no #TeamFabricioLima e na Stefanini, com experiência em SQL Server, focado em desempenho e apaixonado por Sistema Operacional! Além disso, já publicou artigos em revistas, contribui em fóruns, e participa ativamente da comunidade técnica!



