

Eu sempre gostei de trabalhar com SGBDs diferentes, porque eu saia da minha zona de conforto e aprendia coisas novas. Para uma pessoa hiperativa isso é ótimo!
Sempre que me aventuro com um SGBD novo, uma das primeiras coisas que eu procuro entender são os tipos de dados suportados e suas particularidades.
Quando escolhemos um data type limitamos os valores que podem ser incluídos em uma determinada coluna e, dessa forma, começamos a garantir a qualidade dos dados.
Muito se fala de tunning, de ciência de dados e Inteligência Artificial, mas pouco se fala no quanto as empresas gastam porque precisam limpar os dados (que serão usados pelos cientistas de dados e engenheiros de IA), e um dos motivos para ter dados sujos é não escolher o data type correto.
A primeira versão deste artigo continha um resumo super extenso sobre os tipos de dados do PostgreSQL, mas confesso que ficou mega chato de ler e eu não tenho a mesma competência para escrever da comunidade que escreveu a documentação do PG, então recomendo fortemente que você leia a documentação para conhecer os tipos de dados.
Neste artigo vou destacar alguns itens que eu acho muito legais e que diferenciam o PG dos outros SGBDs (não vou falar sobre os tipos para pesquisa de texto, que são lindos, porque em breve escreverei um artigo sobre eles).
Item 1 – Tipos seriais
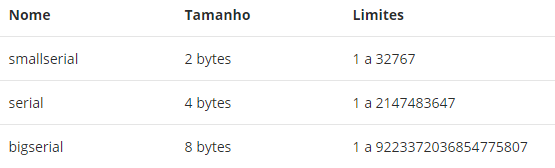
Um que eu adoro no PG são os tipos seriais. Os tipos de dados smallserial, serial e bigserial não são verdadeiros tipos, mas uma notação conveniente para a criação de colunas cujos valores são auto incrementais (semelhante à propriedade identity do SQL Server).
Item 2 – Tipo de Dados Interval
Representa um intervalo de tempo, aceita um parâmetro opcional (p) que especifica o número de dígitos fracionários retidos no campo de segundos. Por padrão, não há limite explícito na precisão. O intervalo permitido p é de 0 a 6.
O tipo interval tem uma opção que indica qual tipo de intervalo deve ser armazenado
- YEAR
- MONTH
- DAY
- HOUR
- MINUTE
- SECOND
- YEAR TO MONTH
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND

Item 3 – Tipo booleano
O que eu acho legal neste data type é que temos uma boa variedade de valores que podem ser usados com o mesmo significado (eu sempre uso os tradicionais TRUE / FALSE).

Valores literais válidos para o “verdadeiro”, são:
- TRUE
- ‘t’
- ‘true’
- ‘y’
- ‘yes’
- ‘on’
- ‘1’
Para o “ falso ” , os seguintes valores podem ser usados:
- FALSE
- ‘f’
- ‘false’
- ‘n’
- ‘no’
- ‘off’
- ‘0’
Item 4 – Tipos enumerados
Para a fanática da qualidade de dados, um tipo ENUM é uma beleza! Esses tipos de dados que compreendem um conjunto de valores ordenados e estáticos. Eles são equivalentes aos enum suportados em várias linguagens de programação.
Item 5 – Tipos de endereço de rede
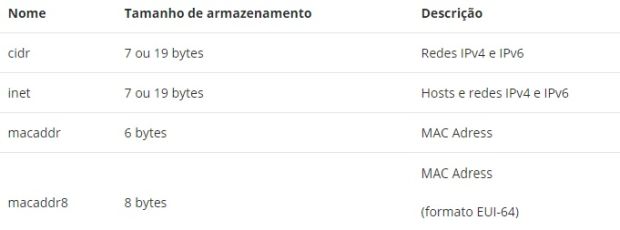
O PostgreSQL oferece tipos de dados para armazenar endereços IPv4, IPv6 e MAC. É melhor usar esses tipos em vez de tipos de texto sem formatação para armazenar endereços de rede, porque esses tipos oferecem verificação de erros de entrada e operadores e funções especializadas.
Conclusão
Trago quatro conclusões que (na minha opinião) são verdades absolutas quando o assunto é banco de dados:
- 1. Tuning começa com a escolha e pesquisa dos tipos de dados corretos para cada necessidade e SGBD.
- 2. Quando escolhemos um data type limitamos os valores que podem ser incluídos em um determinado atributo, e dessa forma começamos a garantir a qualidade dos dados.
- 3. Corrigir um data type é muito mais trabalhoso do que criar as colunas com o tipo certo.
- 4. Limpar dados é caro!
Este assunto continuará com PostgreSQL como BD NoSQL e os tipos de dados para pesquisa de texto.
Referências

De 0 a 10, o quanto você recomendaria este artigo para um amigo?