



Work-Stealing e particionamento recursivo com Fork/Join

A implementação de um eficiente algoritmo paralelo, infelizmente, ainda é uma tarefa não-trivial na maioria das linguagens: precisamos determinar como particionar o problema, determinar o nível ótimo de paralelismo e, finalmente, construir uma implementação com sincronização mínima. Esta última parte é particularmente crítica uma vez que a lei de Amdahl nos diz: “a aceleração de um programa usando múltiplos processadores múltiplos em computação paralela é limitada pelo tempo necessário para a fração sequencial do programa”.
O framework Fork/Join (JSR 166) no JDK7 implementa uma técnica inteligente de work-stealing para a execução paralela que vale a pena conhecer – mesmo que você não seja um usuário do JDK. Otimizado para paralelização dos algoritmos divide-and-conquer (e Map-Reduce), ele abstrai toda a programação da CPU e balanceamento de trabalho por trás de uma API simples de usar.
Balanceamento de carga vs sincronização
Um dos principais desafios na paralelização de qualquer tipo de carga de trabalho é o passo do particionamento: idealmente, queremos particionar o trabalho de tal forma que cada peça terá exatamente a mesma quantidade de tempo. Na realidade, muitas vezes temos que adivinhar o que a partição deve ser, o que significa que algumas partes do problema vão levar mais tempo, seja por causa do esquema de particionamento ineficiente, ou devido a algumas outras razões imprevistas (por exemplo, serviço externo, acesso a disco lento etc.).
É aqui que o work-stealing entra. Se alguns dos núcleos da CPU concluírem seus trabalhos cedo, então nós queremos que eles ajudem a terminar o problema. No entanto, agora temos que ter cuidado: tentar “roubar” o trabalho de outro trabalhador vai exigir sincronização, que irá diminuir a velocidade do processamento. Assim, queremos o work-stealing, mas com sincronização mínima – lembre-se novamente da lei de Amdahl.
Fork/JoinWork-Stealing
O framework Fork-Join (docs) resolve esse problema de uma maneira inteligente: particionamento de trabalho recursivo e uma estrutura double-ended queue (deque) para a realização das tarefas.
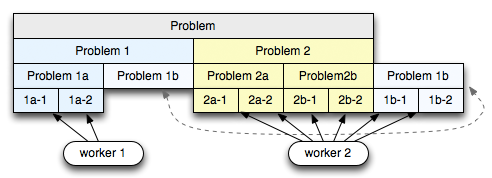
Dado um problema, nós o dividimos em N pedaços grandes, e entregamos cada pedaço para um dos trabalhadores (2 no diagrama acima). Cada worker então recursivamente subdivide o primeiro problema na cabeça do deque e anexa as tarefas de divisão para a head do mesmo deque. Após algumas iterações, nós vamos acabar com um determinado número de tarefas menores na frente do deque, algumas tarefas maiores e outras ainda a serem particionadas. Até aqui tudo bem, mas o que obtemos?
Imagine que o segundo trabalhador tenha terminado todo o seu trabalho, enquanto que o primeiro está ocupado. Para minimizar a sincronização, o segundo trabalhador agarra um trabalho a partir do final do deque (daí a razão para head eficiente e o acesso a tail). Ao fazer isso, ele terá o maior bloco disponível de trabalho, permitindo minimizar o número de vezes que ele tem que interagir com o outro trabalhador (ou seja, minimizar sincronização). Uma técnica simples, mas muito inteligente!
Fork-Join na prática (JRuby)
É importante entender por que e como funciona o framework Fork/Join por baixo dos panos, mas a melhor parte é que a API apresentada ao desenvolvedor abstrai completamente todos esses detalhes. O tempo de execução pode e vai determinar o nível de paralelismo, bem como lidar com todo o trabalho de equilibrar as tarefas entre os trabalhadores disponíveis:
require 'forkjoin'
class Fibonacci < ForkJoin::Task
def initialize(n)
@n = n
end
def call
return @n if @n <= 1
(f = Fibonacci.new(@n - 1)).fork
Fibonacci.new(@n - 2).call + f.join
end
end
n = ARGV.shift.to_i
pool = ForkJoin::Pool.new # 2,4,8, ...
puts "fib(#{n}) = #{pool.invoke(Fibonacci.new(n))}, parallelism = #{pool.parallelism}"
# $> ruby fib.rb 33
O gem forkjoin do JRuby é um wrapper simples para a API Java. No exemplo acima, nós exemplificamos um ForkJoin::Pool e chamamos invoke passando o nosso problema de Fibonacci. O problema de Fibonacci é do tipo ForkJoin::Task, que implementa um método recursivo call: se o problema for “muito grande”, então o dividimos em duas partes, uma das quais é “forked” (empurrado para head do deque), e a segunda nós invocamos imediatamente. A resposta final é a soma das duas funções.
Por padrão, o ForkJoin::Pool vai alocar o mesmo número de threads como núcleos de CPU disponíveis – no meu caso, isso passa a ser 2, mas o código acima escalona automaticamente até o número de núcleos disponíveis! Copie o código, execute-o, e você vai ver todos os recursos disponíveis surgirem com o carregamento.
Map-Reduce e Fork-Join
O recurso da técnica divide-and-conquer é o que habilita o deque work-stealing eficiente. No entanto, é interessante notar que o fluxo de trabalho do “map-reduce” é simplesmente um caso especial desse padrão. Em vez de particionar o problema recursivamente, o algoritmo map-reduce irá subdividir o problema abertamente. Isso, por sua vez, significa que, no caso de uma carga de trabalho desequilibrada, estamos propensos a roubar tarefas mais refinadas, que vão também levar a uma maior necessidade de sincronização – se você pode particionar o problema de forma recursiva, faça isso!
require 'zlib'
require 'forkjoin'
require 'archive/tar/minitar'
pool = ForkJoin::Pool.new
jobs = Dir[ARGV[0].chomp('/') + '/*'].map do |dir|
Proc.new do
puts "Threads: #{pool.active_thread_count}, #{Thread.current} processing: #{dir}"
backup = "/tmp/backup/#{File.basename(dir)}.tgz"
tgz = Zlib::GzipWriter.new(File.open(backup, 'wb'))
Archive::Tar::Minitar.pack(dir, tgz)
File.size(backup)
end
end
results = pool.invoke_all(jobs).map(&:get)
puts "Created #{results.size} backup archives, total bytes: #{results.reduce(:+)}"
# $> ruby backup.rb /home/igrigorik/
O código acima é um simples exemplo de map-reduce através da mesma API. Dado um caminho, esse programa irá iterar sobre todos os arquivos e pastas, criar todas as tarefas de backup abertamente e, finalmente, invocá-los para criar os arquivos de backup. O melhor de tudo: não há gerenciamento threadpool ou código de sincronização para ser visto, e o framework facilmente fixar todos os seus núcleos disponíveis, bem como equilibrar automaticamente o trabalho entre todos os trabalhadores.
Parallel Java & Distributed Work-Stealing
O framework Fork/Join é muito simples na superfície, mas como sempre, o diabo está nos detalhes quando se trata de otimizar o desempenho. No entanto, independentemente de você ser um usuário do JDK ou não, o deque, combinado com um passo de particionamento recursivo é um ótimo padrão para manter em mente. A implementação do JDK é construída para “cargas de trabalho” dentro de JVM individuais, mas um padrão similar pode ser igualmente útil em muitos casos distribuídos.
***
Texto original disponível em http://www.igvita.com/2012/02/29/work-stealing-and-recursive-partitioning-with-fork-join/
É Developer Advocate no Google, trabalha com tudo o que está relacionado a desempenho na web, como melhores práticas, protocolos, padrões e desempenho do navegador.



