

Eu encontrei este pequeno problema outro dia: um servidor que roda por um tempo e então falha. Ele era reiniciado por um script, e todo o processo se repetia novamente. Não parece tão ruim, uma vez que ele não era de missão crítica, apesar de haver uma perda significativa de dados. Decidi então olhar mais de perto e encontrar exatamente qual era o problema.
A primeira coisa que notei é que o servidor passa por todos os testes unitários e vários testes de integração. Ele roda bem em todos os ambientes de teste, usando dados de teste, portanto, o que pode estar errado? É fácil supor que, em produção, ele provavelmente deve estar com uma carga maior do que nos testes, ou maior do que foi permitido no projeto e, por conta disso, está ficando sem recursos. Mas quais seriam os recursos e onde? Essa é uma pergunta traiçoeira.
Para demonstrar como investigar esse problema, a primeira coisa a fazer é escrever um exemplo de código com vazamento.
Para demonstrar código com vazamento, preciso, como sempre, de um cenário bem planejado e, nele, imaginar que você trabalha para um corretor de ações em um sistema que grava suas compras de ações em uma base de dados. As ordens são recebidas e enfileiradas por uma thread simples. Outra thread pega as ordens da fila e as escreve na base de dados. O POJO Order é muito direto e se parece com isto:
public class Order {
private final int id;
private final String code;
private final int amount;
private final double price;
private final long time;
private final long[] padding;
/**
* @param id
* The order id
* @param code
* The stock code
* @param amount
* the number of shares
* @param price
* the price of the share
* @param time
* the transaction time
*/
public Order(int id, String code, int amount, double price, long time) {
super();
this.id = id;
this.code = code;
this.amount = amount;
this.price = price;
this.time = time;
// This just makes the Order object bigger so that
// the example runs out of heap more quickly.
this.padding = new long[3000];
Arrays.fill(padding, 0, padding.length - 1, -2);
}
public int getId() {
return id;
}
public String getCode() {
return code;
}
public int getAmount() {
return amount;
}
public double getPrice() {
return price;
}
public long getTime() {
return time;
}
}
O POJO Order é parte de um aplicativo Spring simples, que possui três abstrações fundamentais que criam uma nova thread quando o Spring chama o método start().
A primeira dessas abstrações é o OrderFeed. O método run() cria uma ordem de mentira e a coloca na fila. Ela então fica em estado de sleep até o momento de criar a próxima ordem.
public class OrderFeed implements Runnable {
private static Random rand = new Random();
private static int id = 0;
private final BlockingQueue<Order> orderQueue;
public OrderFeed(BlockingQueue<Order> orderQueue) {
this.orderQueue = orderQueue;
}
/**
* Called by Spring after loading the context. Start producing orders
*/
public void start() {
Thread thread = new Thread(this, "Order producer");
thread.start();
}
/** The main run loop */
@Override
public void run() {
while (true) {
Order order = createOrder();
orderQueue.add(order);
sleep();
}
}
private Order createOrder() {
final String[] stocks = { "BLND.L", "DGE.L", "MKS.L", "PSON.L", "RIO.L", "PRU.L",
"LSE.L", "WMH.L" };
int next = rand.nextInt(stocks.length);
long now = System.currentTimeMillis();
Order order = new Order(++id, stocks[next], next * 100, next * 10, now);
return order;
}
private void sleep() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
A segunda classe é OrderRecord, que é responsável por pegar as ordens da fila e escrevê-las na base de dados. O problema é que ela leva significativamente mais tempo para escrever as ordens na base de dados do que para produzi-las. Isso é demonstrado pelo longo 1 segundo de sleep no meu método recordOrder(…).
public class OrderRecord implements Runnable {
private final BlockingQueue<Order> orderQueue;
public OrderRecord(BlockingQueue<Order> orderQueue) {
this.orderQueue = orderQueue;
}
public void start() {
Thread thread = new Thread(this, "Order Recorder");
thread.start();
}
@Override
public void run() {
while (true) {
try {
Order order = orderQueue.take();
recordOrder(order);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* Record the order in the database
*
* This is a dummy method
*
* @param order
* The order
* @throws InterruptedException
*/
public void recordOrder(Order order) throws InterruptedException {
TimeUnit.SECONDS.sleep(1);
}
}
O resultado é óbvio: a thread OrderRecord não consegue acompanhar a fila e se tornará maior e maior, até que a JVM fique sem espaço e quebre. Este é o grande problema com o padrão Producer Consumer: o consumer precisa ser capaz de acompanhar o producer.
Apenas para provar a tese, adicionei uma terceira classe, OrderMonitor, que imprime o tamanho da fila a cada poucos segundos para que você possa ver o que está dando errado.
public class OrderQueueMonitor implements Runnable {
private final BlockingQueue<Order> orderQueue;
public OrderQueueMonitor(BlockingQueue<Order> orderQueue) {
this.orderQueue = orderQueue;
}
public void start() {
Thread thread = new Thread(this, "Order Queue Monitor");
thread.start();
}
@Override
public void run() {
while (true) {
try {
TimeUnit.SECONDS.sleep(2);
int size = orderQueue.size();
System.out.println("Queue size is:" + size);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Apenas para completar, incluí o contexto do Spring abaixo:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd"
default-init-method="start"
default-destroy-method="destroy">
<bean id="theQueue" class="java.util.concurrent.LinkedBlockingQueue"/>
<bean id="orderProducer" class="com.captaindebug.producerconsumer.problem.OrderRecord">
<constructor-arg ref="theQueue"/>
</bean>
<bean id="OrderRecorder" class="com.captaindebug.producerconsumer.problem.OrderFeed">
<constructor-arg ref="theQueue"/>
</bean>
<bean id="QueueMonitor" class="com.captaindebug.producerconsumer.problem.OrderQueueMonitor">
<constructor-arg ref="theQueue"/>
</bean>
</beans>
A próxima coisa a fazer é começar com o código de vazamento. Você pode fazer isso alterando para o seguinte diretório
/<your-path>/git/captaindebug/producer-consumer/target/classes
…e digitando o comando a seguir:
java -cp /path-to/spring-beans-3.2.3.RELEASE.jar:/path-to/spring-context-3.2.3.RELEASE.jar:/path-to/spring-core-3.2.3.RELEASE.jar:/path-to/slf4j-api-1.6.1-javadoc.jar:/path-to/commons-logging-1.1.1.jar:/path-to/spring-expression-3.2.3.RELEASE.jar:. com.captaindebug.producerconsumer.problem.Main
…onde “path-to” é o caminho para os seus arquivos jar.
Uma coisa que eu realmente odeio em relação ao Java é o fato de que é MUITO difícil executar qualquer programa a partir da linha de comando. Você precisa descobrir o caminho da classe, quais opções e propriedades precisam de configuração e qual é a classe principal. É claro que é possível pensar em uma forma de simplesmente digitar Java nomeDoPrograma e a JVM descobrir onde todo o resto está, especialmente se usarmos uma convenção em vez de configuração: por que é tão difícil?
Você também pode monitorar o aplicativo com vazamento simplesmente anexando um simples jconsole. Se estiver executando remotamente, então é necessário acrescentar as seguintes opções à linha de comando acima (escolhendo o número da porta desejada):
-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9010 -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
… e se você quiser dar uma olhada na quantidade de pilha usada, a verá aumentando gradualmente, na medida em que a fila fica maior.
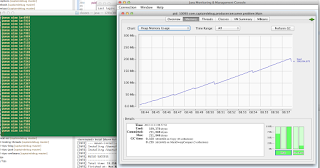
Se um kilobyte de memória vazar, então você provavelmente nunca perceberá; se um gigabyte de memória vazar, o problema será óbvio. Portanto, tudo que resta a fazer por hora é sentar-se e esperar pela memória que se esvai, antes de passar para o estágio seguinte de investigação. Mais sobre isso no próximo artigo.
O código fonte para esse artigo pode ser encontrado no meu projeto Producer Consumer no Github.
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://www.captaindebug.com/2013/11/investigating-memory-leaks-part-1.html#.UvKMEfihVFJ

De 0 a 10, o quanto você recomendaria este artigo para um amigo?