



Falando em voz alta – Uma introdução ao processamento de linguagem natural

Em 1954, a Universidade de Georgetown e a IBM demonstraram a capacidade de traduzir algumas frases russas para o inglês. Meio século depois, a IBM desenvolveu um sistema de resposta automática chamado IBM Watson que derrotou até mesmo os melhores jogadores do Jeopardy. O Processamento de Linguagem Natural/Natural Language Processing (NLP), característica da IBM Watson, continua sendo um dos aplicativos mais importantes do aprendizado de máquinas porque ele representa a interface mais natural entre humanos e máquinas. Este tutorial explora alguns dos métodos principais que são utilizados para NLP, como a aprendizagem profunda (redes neurais). Ele também demonstra NLP usando bibliotecas de código aberto.
O NLP é um guarda-chuva em vários campos relacionados à linguagem. Para ilustrar, considere o diagrama na Figura 1. Em um sistema abstrato de resposta automática, há tradução de áudio em texto, quebrando o texto em uma estrutura que as máquinas podem usar; um mecanismo discursivo que mantém estado e uma interface para alguma fonte de conhecimento; a geração de uma resposta; e, finalmente, síntese de áudio de fala.
Figura 1. Um sistema abstrato de perguntas e respostas
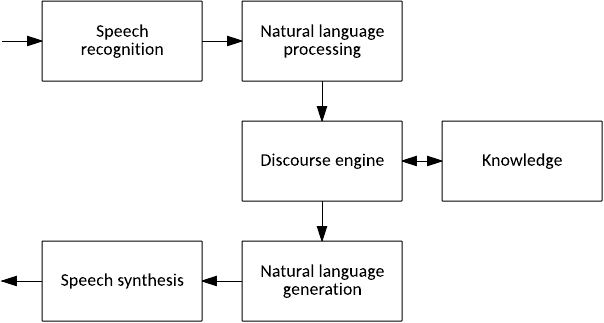
Você pode dividir esses elementos de um sistema de Q&A abstrato ainda mais. No NLP, o texto é dividido por sintaxe em suas partes compostas e, em seguida, é atribuído algum significado através da semântica. Na geração de linguagem natural, o sistema deve reconstruir um conceito abstrato (para ser comunicado ao usuário) em uma resposta (considerando as regras da estrutura da frase para o idioma desejado).
Mas, Q&A é apenas um aspecto do NLP. O NLP também é aplicado em muitas áreas fora do discurso. Dois exemplos são a análise do sentimento (determinar o efeito de uma frase ou documento) e sumarização (onde o sistema cria um resumo de um corpo de texto). Vamos fazer uma rápida pesquisa da história do NLP e, em seguida, mergulhar nos detalhes.
História no NLP
O NLP foi uma das primeiras metas de pesquisa para a inteligência artificial forte porque é a interface natural entre humanos e máquinas (Figura 2). A primeira implementação do NLP foi parte do experimento Georgetown de 1954, um projeto conjunto entre a IBM e a Universidade de Georgetown que demonstrou com sucesso a tradução automática de mais de 60 frases russas para o inglês. Os pesquisadores realizaram esta façanha usando regras de linguagem codificadas manualmente, mas o sistema falhou na escala para a tradução geral.
Figura 2. Uma linha de tempo dos principais marcos do NLP
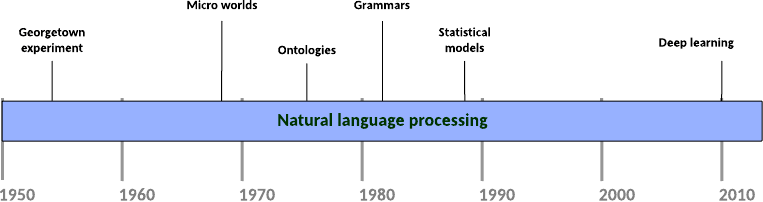
A década de 1960 viu pesquisas em “micro-mundos”, que desenvolveram mundos simulados e NLP para pesquisar e manipular objetos nesses mundos. Um exemplo famoso foi o SHRDLU de Terry Winograd, que usou o NLP para mudar o estado de uma sandbox virtual que continha formas e, em seguida, consultou o estado do mundo através do inglês (“Pode uma pirâmide ser suportada por um bloco?”). SHRDLU demonstrou não apenas o NLP, mas também planeja realizar requisições como “Limpe a tabela e coloque o bloco vermelho no bloco azul”. Outros desenvolvimentos incluíram a construção de Eliza, uma chatterbot que simula um psicoterapeuta.
A década de 1970 trouxe ideias novas para o NLP, como a construção de ontologias conceituais (dados utilizáveis pela máquina). Este trabalho continuou na década de 1980, onde os pesquisadores desenvolveram regras e gramáticas codificadas para analisar a linguagem. Estes métodos revelaram-se frágeis, mas foram métodos ideais, dados os recursos computacionais disponíveis no momento.
Apenas somente no final da década de 1980 que os modelos estatísticos entraram em jogo. Em vez de regras complexas que tendiam a ser frágeis, os modelos estatísticos usavam corpos textuais existentes (documentos e outras informações) para construir modelos de como as pessoas usavam linguagem. Os pesquisadores aplicaram modelos de Markov ocultos (um método para criar modelos probabilísticos para sequências lineares) para rotular a parte da fala para desambiguar o significado por trás das escolhas de palavras na fala (tendo em conta as muitas ambiguidades que existem no idioma). Os modelos estatísticos romperam a barreira de complexidade das regras codificadas à mão criando-as através da aprendizagem automática.
Hoje, o deep learning aumentou a barra em muitas tarefas de NLP. As redes neurais recorrentes (que diferem das redes feed-forward no sentido de que elas podem ser auto-referenciais) foram aplicadas com sucesso na análise, análise de sentimentos e até mesmo na geração de linguagem natural (em conjunto com redes de reconhecimento de imagem).
Analisando uma frase
Agora, vejamos o processamento de uma frase em inglês e o pipeline de tarefas que são usadas para derrubar isso. Vou analisar uma frase simples de quatro palavras (“O outro garoto corre”/”The other boy runs”) e, então, ilustrar isso na Figura 3.
Figura 3. Pipeline de análise de frases
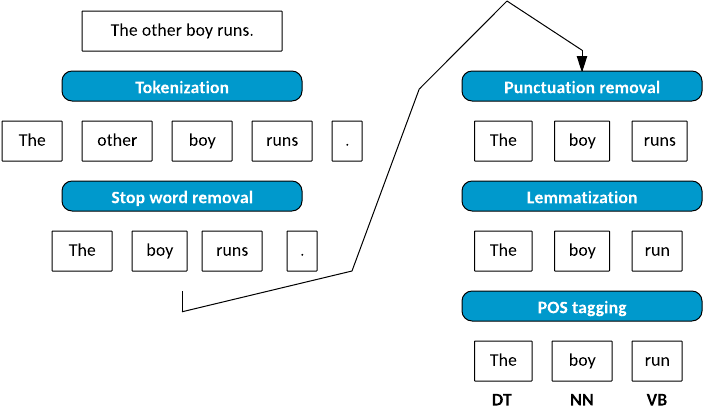
O primeiro passo na análise é tokenizar a frase – isto é, simplesmente quebrar a sentença em suas partes individuais (ou tokens). Os tokens que compõem a minha frase simples são The, other, boy, runs, e o ponto final (.). Tokenization produz o conjunto completo de palavras individuais que compõem a frase.
O próximo passo é chamado de parar a remoção de palavras. O objetivo de parar a remoção de palavras é remover palavras comumente usadas no idioma para permitir o foco nas palavras importantes na frase. Não há uma única definição do conjunto de palavras de parada, mas existem palavras comuns que são facilmente removidas.
Depois de remover as palavras de parada, eu me concentro em remover a pontuação. A pontuação neste contexto se refere não apenas às vírgulas e aos pontos finais, mas também à variedade de símbolos especiais usados (parênteses, apóstrofos, aspas, pontos de exclamação, etc.).
Agora que eu limpei minha sentença, vou me concentrar no processo de lemmatization (também chamado de stemming ). O objetivo da lemmatization é reduzir as palavras para o tronco ou a forma da raiz. Por exemplo, caminhar seria reduzido a andar. Em alguns casos, o algoritmo muda a escolha da palavra para usar o lemma correto (por exemplo, trocar melhor por bom). Neste exemplo, eu reduzo corridas para a sua forma raiz, correr.
A fase final da análise é chamada de marcação parcial da fala (POS). Neste processo, marco as palavras, pois correspondem a uma parte da fala com base no seu contexto. Eu identifico meus tokens de palavras restantes que correspondem a um determinante, um substantivo e a um verbo.
Essas não foram etapas complexas, mas agora vamos ver como esse processo se dá quando executado automaticamente.
Analisando com NLTK
Uma das plataformas mais populares para NLP é o Kit de Ferramentas de Linguagem Natural/Natural Language Toolkit (NLTK) para Python. Usando o pipeline de análise de frases na Figura 3, usarei NLTK em uma frase um pouco mais complexa. Neste exemplo, uso a linha de abertura do Neuromancer de William Gibson. Carreguei a linha dentro de uma string em Puython (observe aqui que >>> é o prompt do Python).
>>> sentence = "The sky above the port was the color of television, tuned to a dead channel."
Em seguida, tokenizo a frase usando o tokenizador de palavras do NLTK e emito os tokens.
>>> tokens = nltk.word_tokenize( sentence ) >>> print tokens ['The', 'sky', 'above', 'the', 'port', 'was', 'the', 'color', 'of', 'television', ',', 'tuned', 'to', 'a', 'dead', 'channel', '.']
Com a frase tokenizada, posso remover as palavras de parada criando um conjunto de palavras de parada para o inglês e, em seguida, filtrando os tokens desse conjunto.
>>> stop_words = set( stopwords.words( "english" ) ) >>> filtered = [ word for word in tokens if not word in stop_words ] >>> print filtered [ 'The', 'sky', 'port', 'color', 'television', ',', 'tuned', 'dead', 'channel', '.' ]
Em seguida, eu removo qualquer pontuação da minha lista filtrada de tokens. Eu crio um conjunto simples de pontuação e, depois, filtro a lista mais uma vez.
>>> punct = set( [ ",", "." ] ) >>> clean = [ word for word in filtered if not word in punct ] >>> print clean [ 'The', 'sky', 'port', 'color', 'television', 'tuned', 'dead', 'channel' ]
Finalmente, eu executo a marcação POS para a lista limpa de tokens. O resultado é um conjunto de token e pares de tag, com a tag indicando a classe de palavras.
>>> parsed = nltk.pos_tag( clean )
>>> print parsed
[ ('The', 'DT'), ('sky', 'NN'), ('port', 'NN'), ('color', 'NN'),
('television', 'NN'), ('tuned', 'VBN'), ('dead', 'JJ'), ('channel', 'NN') ]
Esse é um pequeno subconjunto das capacidades do NLTK. Com o NLTK, você também possui uma coleção de corpos que você pode usar facilmente para experimentar com NLTK e suas capacidades.
Métodos estatísticos
O problema com a análise de texto com base em gramática codificada manualmente é que as regras podem ser bastante frágeis. Mas, ao invés de confiar em regras frágeis codificadas à mão, e se as regras pudessem ser aprendidas com exemplos de textos? É aqui que os métodos estatísticos entram em jogo. Uma vantagem interessante dos métodos estatísticos é que eles podem operar em entradas ou entradas não vistas anteriormente que incluem erros. Graciosamente, lidar com esses tipos de problemas (operando em novas entradas nunca antes vistas) geralmente não é possível usando gramáticas.
Vamos explorar alguns dos métodos estatísticos que o NLTK fornece. Primeiro, vou importar um corpo de amostra que eu, então, usarei dentro do NLTK.
>>> import nltk >>> import nltk.book import *
Eu importei este NLTK para o Python e, em seguida, importei os nove exemplos de textos. Para este exemplo, uso o corpus Text4, que é o “Corpus de Endereço Inaugural”.
>>> text4 <Text4: Inaugural Address Corpus>
Posso facilmente identificar a distribuição de frequência de um texto usando o método FreqDist. Este método me dá a distribuição de palavras dentro de um corpus. Construir uma distribuição de frequência é uma tarefa comum e o NLTK facilita isso. Com a distribuição criada, uso o método most_common para emitir as 15 palavras mais comuns (com o número de aparências no corpus). Posso ver o número total de palavras (e símbolos) usando o método len, que me diz que a palavra “the” representa mais de 6% do texto.
>>> fdist = FreqDist( text4 ) >>> fdist.most_common( 15 ) [ (u’the’, 9281), (u’of’, 6970), (u’,’, 6840), (u’and’, 4991), (u’.’, 4676), (u’to’, 4311), (u’in’, 2527), (u’a’, 2134), (u’our’, 1985), (u’that’, 1688), (u’be’, 1460), (u’is’, 1403), (u’we’, 1141), (u’for’, 1075), (u’by’, 1036)] >>> len( text4 ) 145735 >>> print 100.0 * 9281.0 / len( text4 ) 6.36840841253
NLTK facilmente identifica os contextos mais comuns em que uma palavra é usada em um corpus. Usando o método common_contexts, posso fornecer uma lista de palavras e encontrar seus contextos (o exemplo a seguir indica que “cloaked” foi encontrado no contexto “contempt cloaked in”).
>>> text4.common_contexts( [ “cloaked” ] ) contempt_in
Finalmente, vejamos um aspecto importante da compreensão de um corpus: sequências de palavras que ocorrem com frequência. O conceito de bigram (ou seja, pares de palavras que ocorrem juntas em um texto) entra em jogo aqui, mas uma colocação é o subconjunto de bigrams que ocorrem de forma incomum com frequência. Usando o método collocations , eu posso extrair um conjunto de pares de palavras comuns que ocorrem frequentemente juntas em um determinado texto.
>>> text4.collocations() United States; fellow citizens; four years; years ago; Federal Government; General Government; American people; Vice President; Old World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice; God bless; every citizen; Indian tribes; public debt; one another; foreign nations; political parties
A partir deste conjunto de colocações, é fácil ver que esses pares de palavras dependem fortemente do corpus. Considere outro exemplo usando o filme Monty Python and the Holy Grail como o corpus de entrada.
>>> text7.collocations() BLACK KNIGHT; clop clop; HEAD KNIGHT; mumble mumble; Holy Grail; squeak squeak; FRENCH GUARD; saw saw; Sir Robin; Run away; CARTOON CHARACTER; King Arthur; Iesu domine; Pie Iesu; DEAD PERSON; Round Table; clap clap; OLD MAN; dramatic chord; dona eis
Bigrams (ou n-grams em geral, onde um bigram representa n=2) pode ser útil na compreensão do uso e sequência de palavras dentro de um texto ou para avaliar a probabilidade de ocorrência de uma palavra (em face do ruído). Este método também foi usado para apoiar a identificação de palavras com erros ortográficos ou texto plagiado. N-grams foram utilizados para gerar texto treinado a partir dos n-grams de um determinado corpus.
Deep learning
O deep learning tornou-se a área de estudo mais interessante na aprendizagem de máquina e foi aplicado ao reconhecimento de objetos em imagens ou vídeos (como rostos) e até mesmo resumindo imagens com linguagem natural com base em amostras treinadas. Os pesquisadores também aplicaram aprendizagem profunda na área do NLP.
Um método-chave de utilização do NLP cai sob a abordagem recorrente da rede neural, em que uma rede inclui uma pipeline baseada em tempo ou uma rede com elementos auto-referenciais. Uma arquitetura chave é a longa rede de memória de curto prazo (LSTM), que usa uma arquitetura inovadora em que células de memória compõem as células de processamento. Cada célula de memória inclui uma entrada e um portal de entrada (que determina quando a nova entrada pode ser incorporada); saída e portal de saída (para determinar quando a saída é alimentada para a frente); e um portão de esquecimento, que determina quando o atual estado da célula de memória é esquecido para permitir uma nova entrada. Esta arquitetura geral é mostrada na Figura 4, que representa uma única camada de células com entrada, saída e a capacidade de alimentar o estado celular através de outras células (representando tempo ou sequência).
Figura 4. Rede de memória de curto prazo
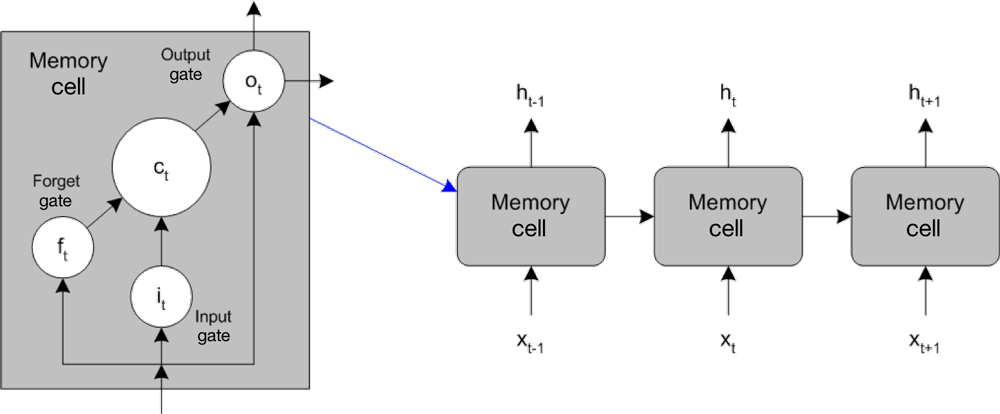
Você pode treinar LSTMs na entrada (usando aprendizagem supervisionada para modificar as células com base no erro da saída) com o algoritmo backpropagation-through-time, um tipo de retro-propagação aplicável a redes recorrentes. Note que, para o NLP, as palavras não se representam, mas são representadas numericamente ou através de vetores de palavras, que mapeiam palavras para um espaço de 1.000 dimensões em que as dimensões podem representar tempo verbal, singular versus plural, gênero e assim por diante. Mapear palavras em vetores de palavras criou a capacidade de executar operações matemáticas em palavras, com resultados surpreendentes. Um exemplo famoso é onde a palavra Queen é muito parecida com a operação King + Woman – Man. Logicamente, isso faz sentido, mas também funciona matematicamente usando vetores de palavras.
O poder dos LSTMs se dá não em pequenas redes, mas em redes verticalmente profundas, que aumentam sua memória e suas redes horizontalmente profundas, o que aumenta sua capacidade de representação. Isso está ilustrado na Figura 5.
Figura 5. Aumentando a memória e as capacidades de representação de uma longa rede de memória de curto prazo
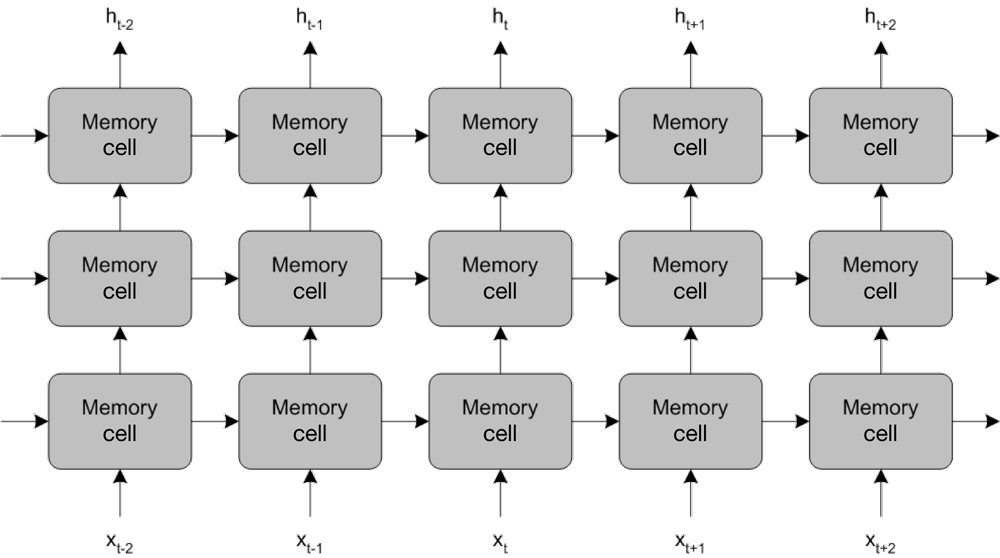
O dimensionamento das redes LSTM baseia-se no tamanho do vocabulário sobre o qual eles devem operar.
A complexidade desses algoritmos para o NLP pode ser significativa, por isso não é surpreendente que você possa agora conduzir NLP com o IBM Watson através de um conjunto de APIs. As mesmas APIs que ajudaram a derrotar os jogadores no programa de televisão Jeopardy estão disponíveis através de um conjunto de serviços REST.
As APIs do IBM Watson expõem uma variedade de funcionalidades, incluindo uma API de conversação que você pode usar para adicionar uma interface de linguagem natural a um aplicativo e APIs que podem classificar ou traduzir o idioma. O IBM Watson pode até traduzir a fala para texto ou texto para fala através de APIs.
Outras aplicações
Eu discuti várias aplicações para NLP aqui, mas a aplicabilidade da NLP é, na verdade, bastante grande e diversificada. A pontuação de ensaio automatizada é uma aplicação útil na arena acadêmica, juntamente com a verificação de gramática, que faz parte de muitos processadores de palavras (incluindo simplificação de texto). O NLP dentro do aprendizado de línguas estrangeiras também é popular, ajudando os alunos a entender o texto em outro idioma ou a verificar o texto gerado por humanos em outro idioma (o que inclui a tradução automatizada de idiomas). Finalmente, a pesquisa em linguagem natural e a recuperação de informações são aspectos úteis do NLP, particularmente considerando o crescimento de dados multimídia que podem ser extraídos.
O NLP também é bastante útil na análise de texto (também conhecida como mineração de texto), que consiste em funções de tarefas como a frequência de palavras, determinando colocações (palavras que ocorrem juntas) e bigrams e distribuição de comprimentos de palavras. Esses recursos podem ser úteis para determinar a complexidade textual ou até a análise da assinatura para identificar o autor.
O futuro é deep learning
O NLP mostrou crescimento ao longo dos últimos 60 anos a partir de gramáticas e regras codificadas manualmente, mas a ciência deu um salto tecnológico significativo através do uso de deep learning. O NLP representa a interface mais natural para os seres humanos, por isso a viagem para levar esse modelo de comunicação às máquinas foi necessária. Hoje, você pode encontrar o NLP, juntamente com reconhecimento e síntese de fala, em dispositivos cotidianos. O deep learning continua a evoluir e isso trará ainda mais novos avanços para esse campo.
Recursos para download
Tópicos relacionados
Watson Natural Language Understanding/Compreensão da Linguagem Natural Watson
Watson Natural Language Classifier/Classificador de Linguagem Natural Watson
***
M. Tim Jones faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://www.ibm.com/developerworks/library/cc-cognitive-natural-language-processing/index.html



