



Como usar Notebooks Jupyter e pandas para analisar dados
No seguinte artigo, a autora mostra como como usar Notebooks Jupyter e pandas para analisar dados.

No ano passado, descobrimos um extenso conjunto de dados sobre o assunto de tráfego nas estradas alemãs fornecido pelo BASt. Ele contém números detalhados de carros, caminhões e outros grupos de veículos passando por mais de 1.500 estações de contagem automática.
A coisa surpreendente sobre este conjunto de dados é que os registros para cada estação de contagem são fornecidos em uma base horária e eles vêm desde o ano de 2003. Um conjunto de dados com dados anuais agregados por estação também está disponível.
Como este parecia ser um conjunto de dados bastante interessante para explorar, começamos a criar ideias para uma visualização. O projeto também foi aceito pelo programa mFUND.
Como uma tentativa de conhecer a estrutura e encontrar uma boa maneira de lidar com o enorme tamanho do conjunto de dados, montamos alguns Notebooks Jupyter (anteriormente, IPython). Os notebooks são uma ótima ferramenta para fazer análise de dados, por isso os usamos para criar tabelas e gráficos simples que respondem a perguntas básicas e nos dão insights sobre os dados. Nas seções a seguir, você pode ver como produzimos gráficos úteis de uma grande quantidade de dados com apenas algumas linhas de código.
Comece
Primeiro de tudo, você precisará importar algumas bibliotecas básicas. No nosso caso, são pandas, que fornecem estruturas de dados, ferramentas para lidar com eles e utilitários de I/O para ler e gravar de e para diferentes fontes de dados, e matplotlib, que usaremos para criar os gráficos.
Como optamos por não usar um esquema de cores predefinido, também definimos uma matriz de cores para os gráficos.
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
colors = ['#2678B2', '#AFC8E7', '#FD7F28', '#FDBB7D',
'#339E34', '#9ADE8D', '#D42A2F', '#FD9898',
'#9369BB', '#C5B1D4', '#8B564C', '#C39C95',
'#E179C1', '#F6B7D2', '#7F7F7F', '#C7C7C7']
Nas seções a seguir produziremos três tipos diferentes de gráficos: um gráfico de linhas, um gráfico de dispersão e um gráfico de área empilhada. O gráfico de linhas e o gráfico de dispersão serão baseados nos dados por hora, enquanto o gráfico de áreas empilhadas será usado para exibir os dados por ano.
Gráfico em linhas: tráfego de carros em uma estação
Usaremos um gráfico de linhas para descrever a frequência de uma única estação de contagem durante o ano de 2016. Portanto, temos que carregar os dados de um csv em um objeto DataFrame e usar a função group_by para agrupá-los por número de estação.
Como seriam muitos dados para exibir em uma base por hora, nós somaremos os números para cada dia, primeiro agrupando-os e, em seguida, somando as colunas para ambas as direções:
# download file from http://www.bast.de/videos/2016_A_S.zip
df = pd.read_csv('2016_A_S.txt', sep=';')
df = df[['Zst', 'Land', 'KFZ_R1', 'KFZ_R2', 'Datum', 'Stunde']]
df.columns = ['nr', 'land', 'cars_r1', 'cars_r2', 'date', 'hour']
# convert values in 'date' column to DateTime
df.loc[df.hour == 24, 'hour'] = 0
df['date'] = pd.to_datetime( df['date'].astype(str) + '-' + df['hour'].astype(str), format='%y%m%d-%H')
grouped_by_name = df.groupby(['name'])
grouped_by_name = df.groupby(['nr'])
number = 1177
station = grouped_by_name.get_group(number)
station_days = station.set_index('date').groupby([pd.TimeGrouper('D')])[['cars_r1', 'cars_r2']].sum().reset_index()
O código para gerar um gráfico de linhas é bastante simples. Usamos sub gráficos para definir um tamanho para o gráfico (figsize = (15, 8)). Em ax.plot (y, x, …), uma linha é plotada no gráfico. Isso é feito duas vezes, pois o tráfego deve ser mostrado nas duas direções. A função set_major_formatter é usada para formatar os valores do eixo de um gráfico. Neste caso, os números são exibidos com ‘,’ como separador de milhares. plt.show() exibirá o gráfico.
fig, ax = plt.subplots(figsize=(15, 8), dpi=200)
ax.plot(station_days['date'], station_days['cars_r1'], c=colors[0])
ax.plot(station_days['date'], station_days['cars_r2'], c=colors[2])
ax.yaxis.set_major_formatter(FuncFormatter(lambda x, p: format(int(x), ',')))
ax.legend(loc='upper right', bbox_to_anchor=(1.1, 1.02))
plt.title('station nr: ' + str(number))
plt.margins(0)
plt.show()
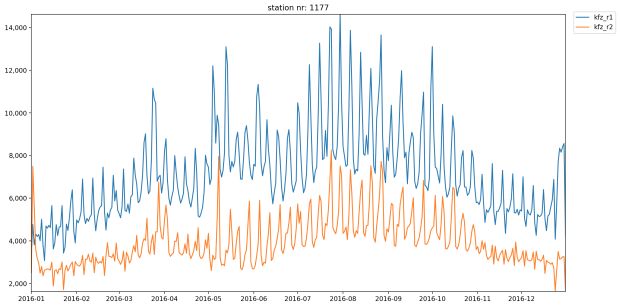
Olhando para este gráfico, fica claro que há muito mais tráfego na direção 1 do que na direção 2 durante todo o ano na estação 1177. O motivo poderia ser que esta é a primeira estação de contagem na Autobahn A23. Os altos e baixos no gráfico deixam claro que há menos tráfego durante os finais de semana.
Gráfico de dispersão: Top 3 dos dias mais movimentados por estado
Para mostrar os três principais dias mais movimentados por estado, decidimos usar um gráfico de dispersão. Antes que o gráfico possa ser gerado, o conjunto de dados precisa de um pouco de reestruturação.
Primeiro, adicionamos coluna sum (soma do tráfego em ambas as direções) ao DataFrame. Em seguida, os dados são agrupados por área e dia antes de classificá-los por sum. Como somente os três principais dias por estado devem ser exibidos, o head(3) é usado para obter os cinco primeiros elementos.
df_scatter = df
df_scatter['sum'] = df_scatter['cars_r1'] + df_scatter['cars_r2']
df_byday = df_scatter.set_index('date').groupby(['land', pd.TimeGrouper('D')])[['sum']].sum().reset_index()
df_sorted = df_byday.sort_values(by=['sum'], ascending=False)
df_clean = df_sorted.groupby(['land']).head(3)
Quando se trata de gerar o gráfico, precisamos dos dados agrupados por land. Para cada área, todos os elementos podem ser adicionados ao gráfico usando ax.scatter(x, y, …). Certifique-se de definir um rótulo. Caso contrário, não é possível criar uma legenda:
groups = df_clean.groupby('land')
scatter_colors = iter(colors)
fig, ax = plt.subplots(figsize=(15, 8), dpi=200)
for name, group in groups:
dates = group['date'].dt.strftime('%Y-%m-%d').values
dates = [pd.to_datetime(d) for d in dates]
ax.scatter(dates, group['sum'].values, s=150, c=next(scatter_colors), label=name)
ax.yaxis.set_major_formatter(FuncFormatter(lambda x, p: format(int(x), ',')))
ax.legend(loc='upper right', bbox_to_anchor=(1.1, 1.015))
plt.show()
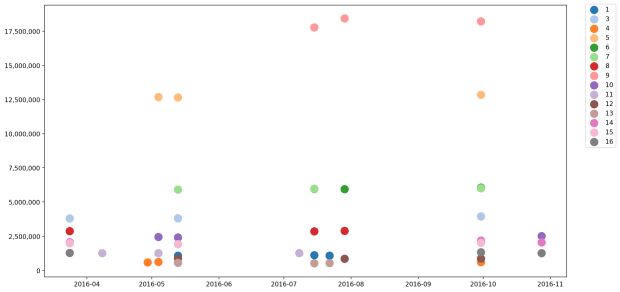
Como você pode ver, os três dias mais movimentados dos estados federais concentram-se em ~ 10 dias do ano. Esses dias de pico podem ser explicados pelo início e término das férias e feriados no país. Por exemplo, as aulas na maioria das universidades começam em 1º de outubro, o que explica o alto volume de tráfego em 30 de setembro.
Gráfico de área empilhada: Desenvolvimento do tráfego de caminhões nas estradas rurais
Por último, mas não menos importante, analisamos os dados anuais, que fornecem os números agregados por ano para cada estação. Criamos um gráfico de área empilhada para descobrir se houve uma mudança no tráfego depois que em 2005 o ‘LKW-Maut’ foi introduzido na Alemanha.
Depois de carregar year_data.csv, todos os elementos com valor ‘A’ (Autobahnen) na coluna str_kl serão excluídos, pois só queremos verificar se havia mais tráfego nas estradas rurais. O DataFrame é, então, agrupado por land, então cada área pode ser exibida como uma camada no gráfico.
df_stacked = pd.read_csv('year_data.csv', sep=';')
df_stacked = df_stacked[df_stacked['str_cl'] != 'A']
grouped_by_land = df_stacked.groupby(['land'])
No nosso caso, três matrizes são usadas para gerar o gráfico:
- years: eixo x
- rows: áreas a serem empilhadas
- names: rótulos para áreas
Essas matrizes são preenchidas com dados por meio da iteração no objeto grouped_by_land. Observe que years e names são matrizes unidimensionais, enquanto rows é bidimensional. Finalmente, plotamos os dados no gráfico usando ax.stackplot(x, y, …).
x = [2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016]
names = []
rows = []
for name, land in grouped_by_land:
by_year = land.groupby(['year'])['trucks_r1', 'trucks_r2'].sum()
names.append(name)
data = (by_year['trucks_r1'] + by_year['trucks_r2'])
data = data.fillna(method='pad').values
rows.append(data)
fig, ax = plt.subplots(figsize=(10, 5), dpi=200)
ax.stackplot(x, rows, labels=names, colors=colors)
ax.legend(loc='upper right', bbox_to_anchor=(1.15, 1.02))
ax.yaxis.set_major_formatter(FuncFormatter(lambda x, p: format(int(x), ',')))
plt.margins(0, 0.1)
plt.show()
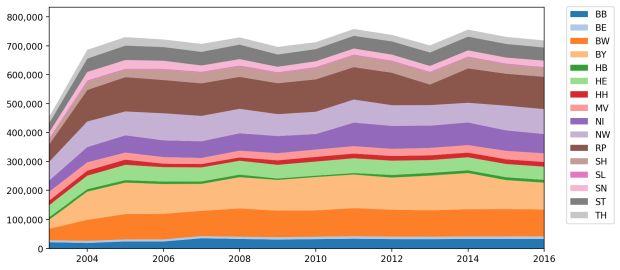
O gráfico mostra que o tráfego nas estradas rurais se desenvolveu de forma diferente do esperado e não houve aumento significativo no ano de 2005, quando o LKW Maut foi introduzido.
O notebook no GitHub
Quer dar uma olhada mais de perto? Ideias e sugestões para futuras visualizações são muito bem vindas!
Sinta-se à vontade para verificar o notebook no GitHub caso queira brincar com o código.
***
Christine Wiederer faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://blog.webkid.io/analysing-data-with-jupyter-notebooks-and-pandas/
Após estudar mídia e computação em Berlim, Christine agora trabalha como desenvolvedora front-end e cientista de dados na webkid.io.



