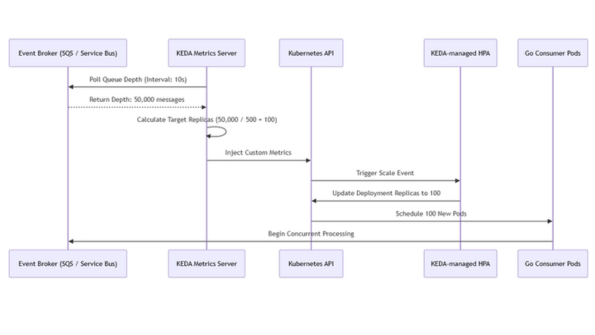
O Load Balancer não está com problema, você que dimensionou errado
Vamos exemplificar o fluxo e a organização dos requests lançados pelo cliente no servidor web.

Em geral, quando um cliente acessa o site e este retorna o erro HTTP 5XX, a primeira medida do administrador é acessar o servidor para verificar se houve queda no serviço. Quando ele verifica que todas as aplicações do servidor estão funcionando normalmente, fica em dúvida: “como meu serviço está funcionando se eu estou recebendo 5XX do outro lado? Que tela branca é essa no browser?” e a primeira resposta que aparece é: “o ELB (Elastic Load Balancer) está com algum problema. Vamos abrir um ticket na AWS (Amazon Web Services)!”. Neste artigo, vamos mostrar o equívoco deste diagnóstico.
Entender como funcionam estas filas não é a tarefa mais simples do mundo…
Por isso, vamos exemplificar o fluxo e a organização dos requests lançados pelo cliente no servidor web, explicando como funciona a organização das filas em cada instância e como ocorre a distribuição delas pelo Load Balancer. A ideia é expor como o problema de timeout e o tamanho máximo das filas de requests podem limitar o número de acessos ao serviço em questão.

Na figura, podemos ver a existência de filas nas entradas do Load Balancer e em cada uma das instâncias EC2 na camada web. Na camada do ELB, a AWS programa sua escalada automática de forma que sua capacidade de atendimento possa dobrar a cada cinco minutos, de acordo com a demanda. A fila do ELB comporta 1024 requests. Nas EC2s, o tamanho da fila deve ser configurado no webserver e determinado pelo tempo de latência da aplicação, considerando o tempo de timeout do browser.
O tempo default de timeout idle no ELB é de 60 segundos, como normalmente é configurado no browser.
Em um exemplo prático, se considerarmos que o tempo médio da aplicação para uma request é de 0.6 segundos e que o tempo máximo de espera do browser do cliente é de 60 segundos, então o tamanho máximo dessa fila deveria ser de 100 solicitações, de forma que todas elas pudessem ser respondidas dentro de 60 segundos para cada instância EC2.
Na camada do web-server temos 10 instâncias conectadas à rede atendendo os requests dos clientes na internet, totalizando um volume de mil requests por minuto (1000 req/min). O Load Balancer possui uma fila de 1024 requests e está redirecionando esse tráfego de forma equilibrada para as 10 instâncias EC2 na camada web. Podemos fazer uma alusão dessas filas como uma “piscina de requests”.
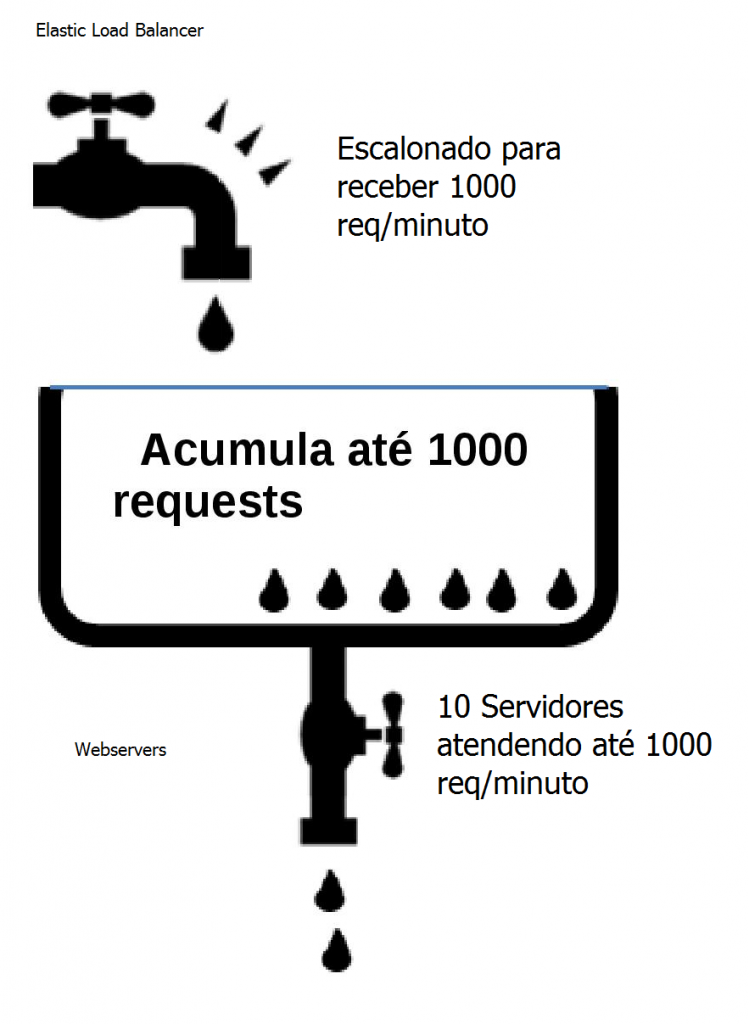
Caso os requests na camada web do nosso exemplo transbordem, as excedentes não serão atendidas, retornando um erro para o cliente. Dependendo da configuração do servidor de aplicações na camada web, este pode retornar timeout para o cliente final, mas tipicamente não é isso o que ocorre.
No caso dos requests transbordarem, a ideia de volume também pode ser aplicada aqui. Em geral, fazer um escalonamento horizontal é fazer com que essa “piscina” comporte mais requests. Nos cenários abaixo, vamos exemplificar os casos mais comuns de erros enfrentados pelo problema de fila no servidor.
TimeoutEm geral, ocorre quando há aumento no tempo de latência médio de processamento da aplicação. Nestes casos, os últimos requests alocados na fila recebem timeout por não conseguirem ser atendidos pelo servidor no prazo de 60 segundos estabelecidos pelo browser do cliente. A instância não responde a tempo para o ELB e este envia o código de erro HTTP504 para o cliente (passando de 60 segundos idle na conexão).
O aumento do tempo de latência pode ser utilizado como gatilho pelo CloudWatch para disparar um escalonamento horizontal no Auto Scaling, devolvendo, assim, o volume original na capacidade de atendimento de requests na camada web e ajustando o tamanho das filas de cada instância para as novas condições de operação.
Limite de transbordo das EC2s excedidoOcorre quando o número máximo de requests atendidas pelo servidor web é excedido. No nosso exemplo, temos uma capacidade máxima de mil requests por minuto. O webserver pode ser configurado para responder imediatamente um código de erro para requests além de 1000, ou descartar. Se o webserver responder imediatamente, o cliente verá um erro 5XX vindo do servidor. Se o webserver descartar o request, o ELB, por fim, vai retornar o erro HTTP 504 para o browser do cliente. Uma forma de contornar esse problema é, novamente, ajustar o Auto Scaling para dar mais volume de atendimento para o servidor web.
Limite de fila do Load BalancerVamos criar um cenário no qual o Product Owner, junto com seu DevOps, está lidando com um evento em que teremos um “boom” no número de requests por minuto a partir de uma determinada hora, e que este será 10 vezes maior que o volume original total do servidor web. Eles agendaram no Auto Scaling para começar o atendimento do pico com 100 instâncias e ir diminuindo à medida que o fluxo de tráfego fosse estabilizando. Isso dá a eles a capacidade de atendimento de 10 mil requests/min. Na hora do “boom”, mesmo assim, o site ficou fora do ar.
Nesse caso, o conceito de fila aplicado nas instâncias é o mesmo para o Load Balancer. Nesse exemplo, o ELB estava escalonado para atender a 1 mil requests/min, mas o tráfego de entrada subiu muito rapidamente para 10 mil requests/min. O ELB conseguiu atender os dois mil primeiros clientes e os outros 8 mil foram descartados da fila. Mesmo com o Load Balancer dobrando sua capacidade a cada 5 minutos, ele iria precisar de pelo menos 20 minutos para conseguir atender um fluxo de 10 mil requests por minuto vindo da internet.
Os requests rejeitados são os não muito conhecidos “Spillover requests”. Nesse caso, o ELB vai te responder um código 503.
Uma maneira de contornar esse problema de fila no Load Balancer é realizar um procedimento chamado de pedido de pre-warm up. O pre-warming do ELB é solicitado via ticket na AWS. Se o pre-warming tivesse sido feito no nosso exemplo, ele começaria o evento com uma capacidade de atendimento de 10 mil req/s e todas as solicitações seriam redirecionadas para a camada de instâncias web, mantendo, assim, o “site no ar”.
Faça um bom projeto!Até aqui, listamos as principais causas e maneiras de contornar o problema de fila dentro do servidor web. Todos esses problemas podem ser contornados utilizando mecanismos de trigger fornecidos pela Amazon Web Services (CloudWatch e Auto Scaling) e uma previsão correta do tráfego de requests no site. O Cloudwatch sempre pode te ajudar no diagnóstico, ver os erros ELB_5XX e os erros Backend_5XX no ELB ajudam muito.
Vale ressaltar que mesmo tendo o histórico de uso dos clientes, em alguns casos o time pode estimar um número de acessos para um lançamento de produto, por exemplo, e na hora esse valor ser bem superior. Se este caso ocorrer, não tem solução, o site vai parecer indisponível até que seu escalonamento chegue lá. O modelo de alocação de recursos por hora ajuda muito nessa hora porque sempre podemos começar um evento com um número bem maior do que o estimado de servidores com um custo relativamente pequeno, e deixar a infra diminuir conforme os usuários do evento entrem no site.
O time é responsável, mas um DevOps com conhecimentos de arquitetura e de como cada camada funciona deve ser capaz de cuidar e ajudar o time a prever os casos críticos. É fundamental montar corretamente os mecanismos de trigger e manter sempre o volume da “piscina” em níveis aceitáveis, e assim não deixar seu site “sair do ar”.
Estagiário e devops na Concrete Solutions, atualmente está concluindo a graduação em Engenharia Eletrônica e de Computação na Universidade Federal do Rio de Janeiro (UFRJ). Adora física de altas energias e programar, e não dispensa uma boa leitura nas horas vagas.