Microsserviços com Flask
saiba tudo sobre Microsserviços com Flask, neste novo artigo imperdível e completo do iMasters


Neste artigo vamos desenvolver um micro-serviço para funcionalidades de “Logging” afim de registrar ações bem sucedidas e / ou erros de nossas aplicações de negócio.
Certa vez, a alguns anos atrás (muitos), nosso gerente de desenvolvimento sugeriu desenvolver um componente que registrasse tudo o que o sistema fazia em uma tabela no database… Imediatamente como garotos inexperientes que éramos achamos a idéia uma verdadeira loucura… Pois é, muitos anos depois percebi que sem esse recurso fica praticamente impossível de manter um sistema sob controle. Um módulo de logging, nos dias de hoje, é um braço direito insubstituível na vida de qualquer programador.
Antes de colocar a mão na massa, micro-serviços nada mais são do que servidores http independentes que podem ou não estarem na mesma máquina / processador e atendem / fazem requisições entre outros micro-serviços.
Um micro-serviço que faz parte de um “todo” (a esse todo me refiro a nossa aplicação completa), ao mesmo tempo não depende de outro(s) micro-serviço(s) para estar “rodando”. Se um micro-serviço simplesmente para de rodar, o outro micro-serviço deve continuar rodando normalmente. Se isso não acontecer, o nosso micro-serviço não pode ser considerado um tal e sim um “micro-monolítico”.
Vamos nos concentrar em desenvolver dois services dando a eles independência e integração entre os mesmos.
O último ponto importante sobre micro-serviços está na questão da “necessidade”. Em uma aplicação monolítica que estava funcionando bem, porém com algum crescimento de dados e principalmente “concorrência” (mais requisições simultâneas), vale considerar uma análise detalhada nós índices das tabelas, nas queries a serem resolvidas pelo banco, na forma como está escrito o seu código (programação funcional X iteração) e latência na construção dos objetos e não menos importante o transporte dos seus dados até o solicitante de origem.
Verifique tudo isso antes de partir para o desenvolvimento de um padrão de micro-serviços, pois é mais trabalhoso desenvolver nesse padrão, a transição pode custar caro e nem sempre temos tempo hábil para tal.

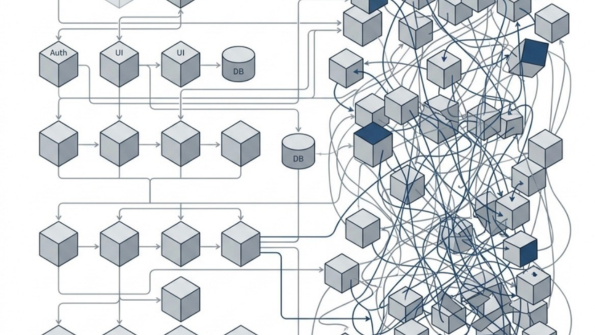
A imagem acima representa tudo o que você leu até agora!
- “Latência”: Gerenciamento de construção dos recursos de comunicação entre os micro-serviços.
- “Autonomia”: 1 micro-serviço continua rodando enquanto outro está em atualização de versão, por exemplo.
- “Processamento distribuído”: Posso criar “paralelismo” real usando processadores distintos e gerar reação performática em cadeia em toda minha aplicação.
- “Monitoramento”: Com um ou mais micro-serviços de logging, posso tirar estatísticas de requisições e tempos de respostas identificando os pontos de gargalo de minha aplicação.
Mão na massa
Ok, vamos botar a mão na massa e criar nosso “logging micro-service”.
Crie uma conta e um cluster gratuito em https://cloud.mongodb.com/. Vamos usar mongoDB em nuvem para exemplificar este artigo. Você deverá obter uma url de conexão conforme imagem abaixo:
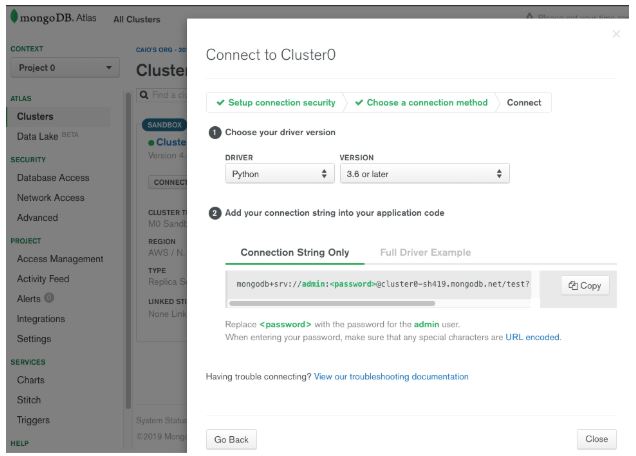
Guarde essa url e vamos instalar algumas bibliotecas para o nosso projeto. Abra o seu terminal e digite:
python -m pip install –upgrade pip <Enter>
pip install pymongo <Enter>
pip install flask <Enter>
Para codificar vou usar VSCode, editor de textos queridinho por programadores python e outras linguagens…
A próxima imagem descreve a estrutura de nossa API para rodar os micro-serviços.
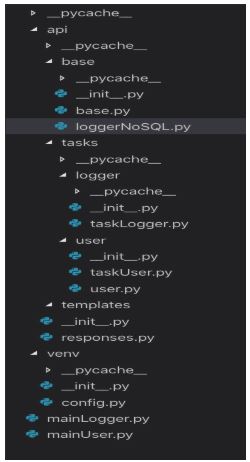
A estrutura de pastas de nosso projeto sugerida seguirá o modelo de API rest.
Como base faremos a construção de nossa classe “loggerNoSQL” para reunir os recursos de “listar os logs.
cadastrados” e “inserir um novo log”.
Teremos 2 APIs: 1 serviço para fins de LOGGING e outro (como exemplo) para fins de manuseio de dados de usuário.
O objetivo é fazer com que cada API seja um micro-serviço. Cada micro-serviço será executado de forma independente pode receber requisições entre os mesmos ou requisições de terceiros.
Definição de recursos:
Serviço de Logging: Pode receber requisições de outro micro-serviço ou de ferramentas terceiras como por exemplo o software de requisições HTTP postman.
Serviço de Logging: Possui as mesmas características do serviço de logging e ainda pode fazer requisições para outros micro-serviços
Classe de criação e listagem de nossos logs
Na pasta api/base crie um arquivo chamado “loggerNoSQL.py” e siga as instruções abaixo:
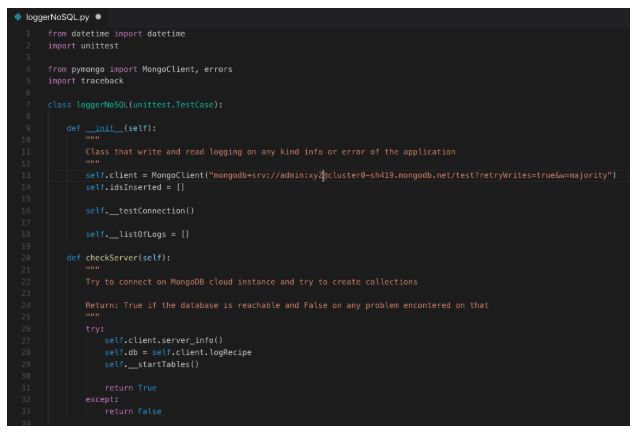
Explicação do código:
Após a importação das bibliotecas necessárias, na construtora da classe, definimos o nosso objeto de conexão “self.client” com a url de conexão do “Atlas MongoDB” e mais algumas propriedades privadas para auxílio de nossos testes.
Abaixo temos um método para tentar conectar no database e definir algumas tabelas de uso. No caso do mongoDB, a criação de “Coleções” e uso de “Documentos” podem ser entendidos como tabelas em nosso costume em bancos SQL. Se os documentos ainda não existem, serão criados automaticamente.
Vamos usar o pytest para testar cada funcionalidade de nossa classe:
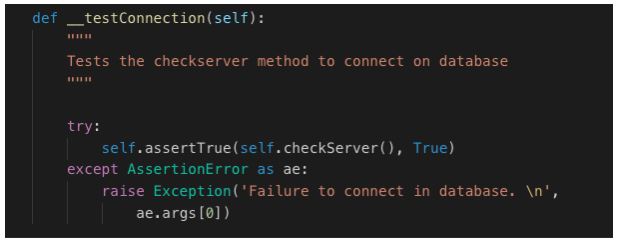
O teste nos retorna True quando este passa e automaticamente estamos conectados com nossas coleções e documentos no mongoDB.
O método checkServer é testado pelo método __testConnection e o início com duplo underscore “__” indica um método privado dentro da classe.
Definição e criação de coleções para gravar nossos logs
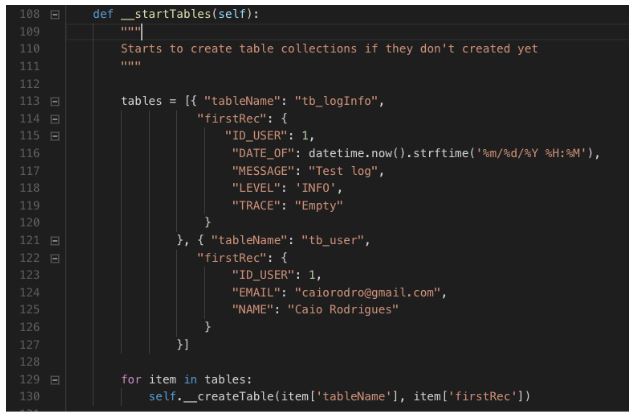
Conforme código acima temos uma coleção de log chamada “tb_logInfo” e outra coleção de exemplo chamada “tb_user”. A definição de cada coleção é descrita pela estrutura do node “firstRec” junto com os valores de cada campo. O método __createTable é executado para a ação efetiva da criação das coleções.
Método __createTable:
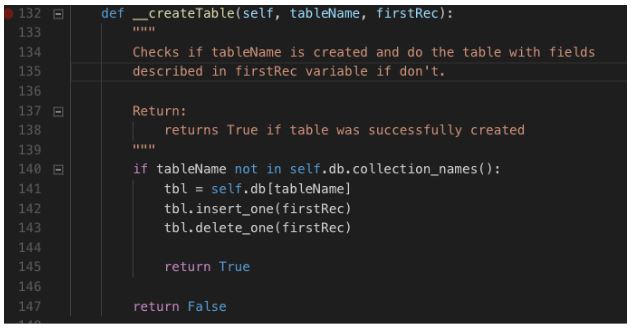
Em seguida vamos criar nosso método de adicionar novos registros de log.
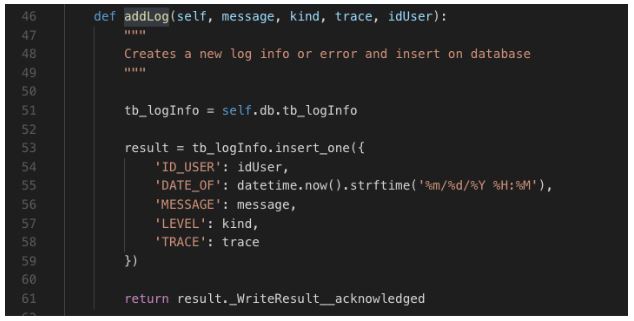
Com a coleção identificada ou criada em nosso database, o método acima insere um registro (documento) com base nos parâmetros recebidos e em seguida retorna o número de registros inseridos na ação.
Ok, vamos testar o método acima:
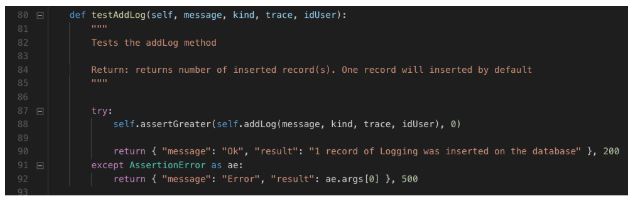
O teste acima espera um resultado maior do que zero e retorna o status 200 para o solicitante da requisição. Caso contrário, onde o registro não pode ser inserido, o status 500 é retornado.
Agora vamos adicionar mais 1 método para listar o(s) nosso(s) log(s):
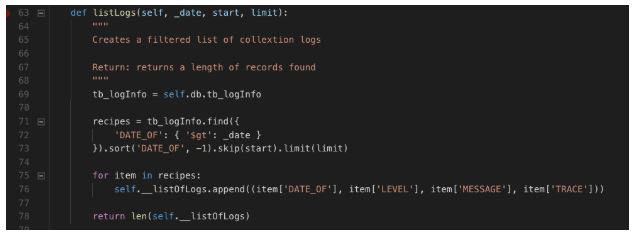
Com tempo o database de logs tende a ficar enorme. Vamos colocar um “paginador” com o objetivo de trafegar poucos dados a cada requisição. Na linha 71 definimos a query pelo método find, criando um filtro pelo campo “DATE_OF” e em seguida usamos os métodos “skip” e “limit” para trazer os registros em uma “página / bloco”. A propriedade “__listOfLogs” é preenchida e retornamos o tamanho dessa lista para provar que a query deu certo.
Bora testar esse método também:
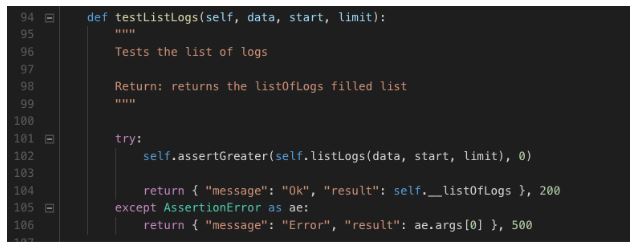
O resultado do teste esperado é maior que zero. Não necessariamente seria um erro caso o resultado da query não encontrasse nenhum registro pelo filtro enviado, mas vamos manter assim apenas para exemplo.
Agora vamos estruturar a nossa “API” para rodar os métodos de testes e obter o resultado efetivo.
Na pasta /api/tasks/logger vamos criar 2 arquivos:
|
__init__.py |
Arquivo de identificação de pasta do projeto e definição de direcionamento de recursos da API |
|
taskLogger.py |
Definição dos métodos da API (POST, GET, PUT e DELETE) |
__init__.py
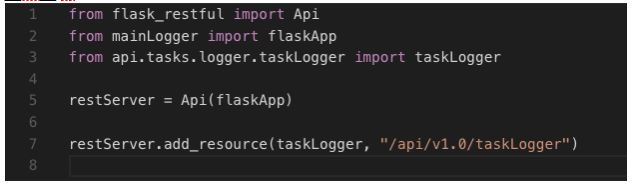
Explicação do código
Importamos os recursos de API rest pela biblioteca flask_restful. Importamos também o arquivo de ponto de entrada “mainLogger” e a nossa classe de ação de rotas das requisições (GET, PUT, POST e DELETE) chamada “taskLogger“. Criamos uma instância de nossa API e adicionamos o recurso de nossa classe junto com o path a ser acessado.
taskLogger.py – parte 1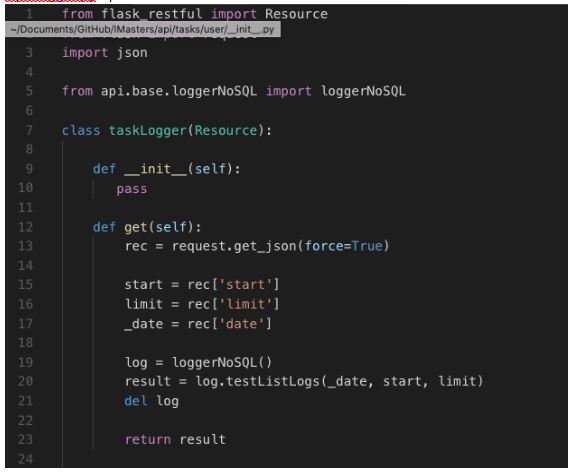
Explicação do código
O método “get” testa o método listLogs da nossa classe de gerenciamento de logging e retorna um array de dados em formato JSON para o solicitante.
Dando tudo certo, o retorno é um JSON com o status 200 “Ok”.
taskLogger.py – parte 2
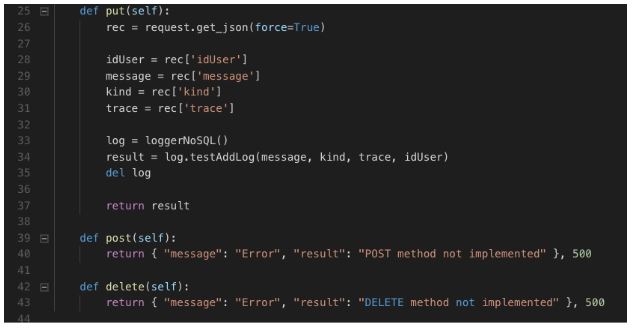
Explicação do código
O método “put” recebe os parâmetros de dados e testa o método “addLog” da nossa classe de gerenciamento de log.
Os outros métodos “put” e “delete” não são necessário para o nosso projeto.
Agora vamos implementar o nosso último arquivo que servirá como ponto de entrada e execução de nossa API.
Crie esse arquivo na pasta raíz do projeto. Crie também um arquivo em branco chamado “__init__.py”
mainLogger.py
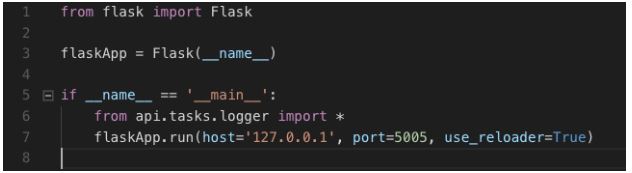
Explicação do código
Neste arquivo principal, de entrada de execução da API, apenas importamos a biblioteca flask e em seguida criamos uma instância do objeto Flask. Checamos se esse arquivo está sendo executado “primeiro” e por fim importamos nossa pasta “tasks” com todos os arquivos contidos e suas funcionalidades. Carregamos o servidor flask definindo o nosso endereço http e porta.
Pronto, finalmente podemos rodar o nosso primeiro micro-serviço! Para tal vamos usar a ferramenta “postman” para fazer as requisições da API.Abra um novo terminal e digite: “python mainLogger.py” <Enter>.
Nosso servidor está pronto para receber requisições.
Abra a ferramenta postman (download em https://www.getpostman.com/) e crie uma nova requisição conforme imagem abaixo:

A url de sua requisição deve ser: “http://127.0.0.1:5005/api/v1.0/taskLogger”. Clique em “Body”, em seguida em “raw” e informe os parâmetros abaixo:
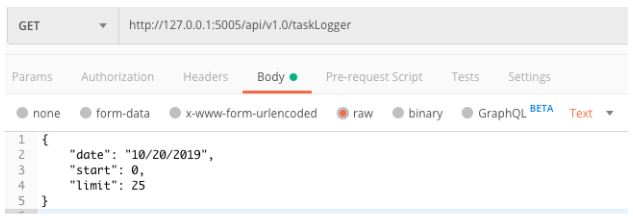
Selecione o método de requisição “GET”, clique no botão “Send” e aguarde o resultado. Provavelmente sua lista irá retornar sem nenhum dado, pois o método PUT (a seguir) vai inserir o primeiro log.
Exemplo de resposta:
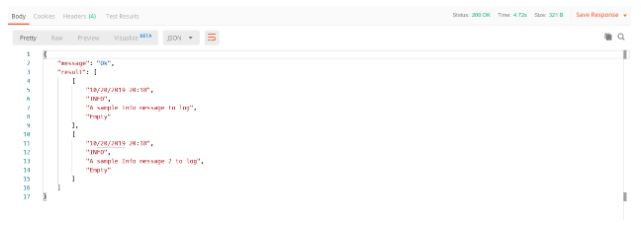 Repare no código do status “200 Ok” e no resultado em formato JSON. Veja também o print de resposta no terminal:
Repare no código do status “200 Ok” e no resultado em formato JSON. Veja também o print de resposta no terminal:
 Ok, vamos fazer um exemplo no método PUT para inserir um novo log, passando os seguintes parâmetros:
Ok, vamos fazer um exemplo no método PUT para inserir um novo log, passando os seguintes parâmetros:
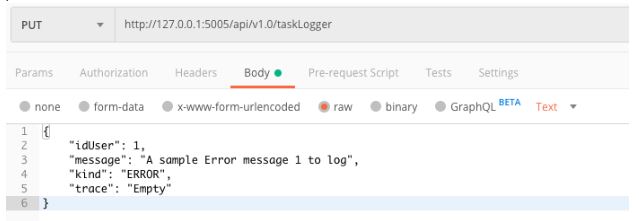
Resultado:

Muito legal! Temos o nosso primeiro micro-serviço baseado no modelo API rest usando Flask com a linguagem python.
Agora vamos criar outro micro-serviço com as mesmas características do primeiro e com alguns recursos a mais.
O próximo micro-serviço é o de gerenciamento de usuários. Alguns métodos apenas simulam uma listagem e inserção de dados e a cada simulação, o primeiro micro-serviço de logging é requisitado através de solicitação “request”.
Vamos começar criando a nossa classe de negócio. Na pasta /api/tasks/user crie os arquivos user.py, taskUser.py e _init__.py
user.py
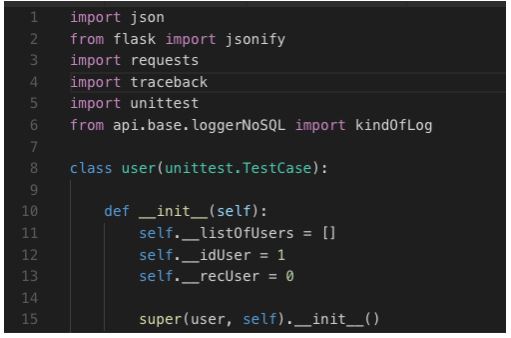
Explicação do código:
Começamos importando algumas bibliotecas e uma classe que nos servirá como ENUM para especificar o tipo de log, no caso “ERROR” ou “INFO”. Na linha 12, em nossa construtora da classe, definimos algumas propriedades que serão utilizadas para testes.
User.py – continuação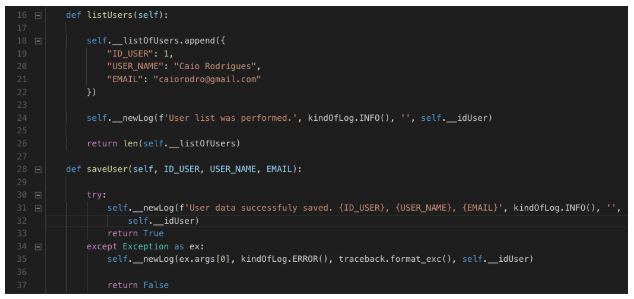
Explicação do código:
Na continuação da classe vamos criar apenas 2 métodos que vão simular as ações e registrar um log através do método __newLog.
Na continuação abaixo vamos apenas testar os nossos métodos de execução.
User.py – continuação
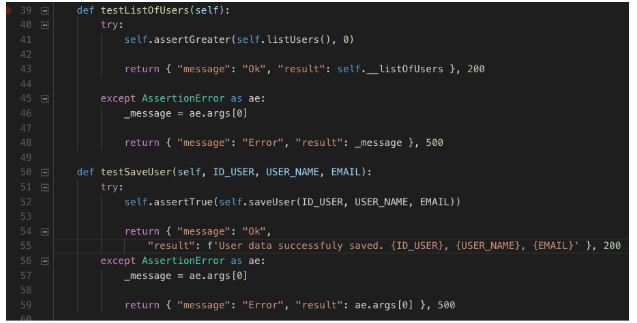
Explicação do código:
Testamos os 2 métodos “testSaveUser” e “testListOfUsers” dando as respostas 200 ou 500 conforme o resultado do teste.
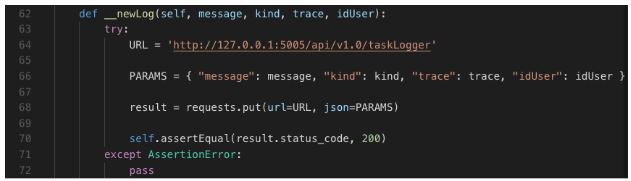
Explicação do código:
E por fim definimos o método que faz a requisição ao micro-serviço de logs via requests.
Agora vamos criar o arquivo taskUser.py na pasta /api/tasks/user. Lembrando que este arquivo é a definição do redirecionamento do recurso da API.
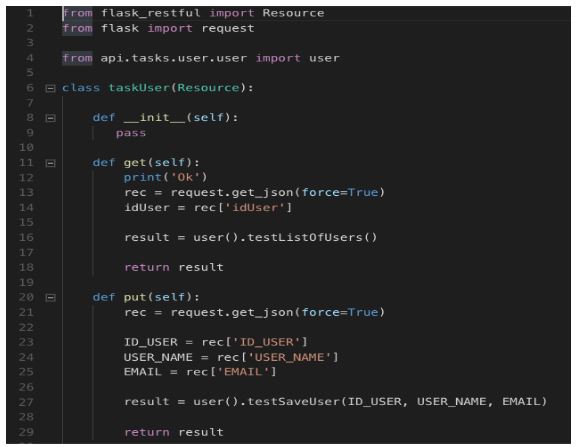
Explicação do código:
Classe de execução das requisições http conforme o “método” solicitante. Vamos usar apenas os métodos GET e PUT para este projeto.
Arquivo __init__.py
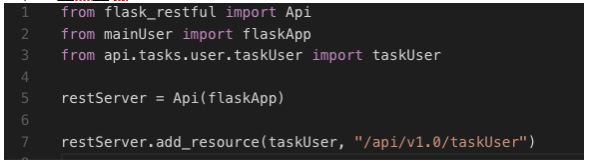
Explicação do código: Arquivo de rota à nossa classe de execução das solicitações http.
Vamos criar o nosso último arquivo na pasta raiz do projeto, que é o ponto de entrada de nosso novo micro-serviço:
mainUser.py
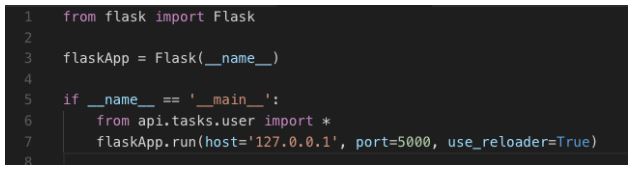
Muito bem, agora temos 2 micro-serviços que podem trabalhar de forma independente.
Vamos obter os resultados nas duas requisições “GET” e “PUT”
Primeiro acessando via GET obtendo uma lista simulada de usuários no formato JSON.

Resultado:
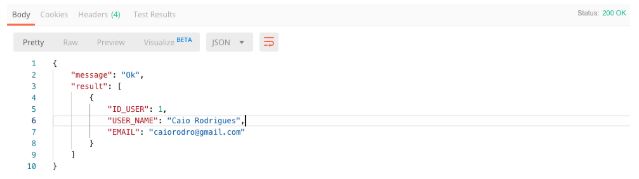
Agora pelo via método PUT simulando a gravação de um novo usuário:

Fizemos a chamada via PUT, simulamos a inserção de um usuário e registramos um log fazendo outra chamada ao micro-serviço de logging através de request http.
O repositório deste projeto de estudos iniciais sobre microserviços está em https://github.com/caiorodro/Logging_Microservice.Ainda no assunto deste artigo, separando as partes como fizemos, podemos obter resultados de requisições fazendo várias “requests” simultâneas e tratar situações de pico melhorando a latência, leitura e transporte de dados. Mas isso já é assunto para o próximo artigo.
Sou programador a pouco mais de 25 anos, tenho softwares em contrato com clientes atualmente, minha principal atuação é como full-stack, trabalho muito com javascript, C# e pytthon.